Parallelism (Gather Streams)
Introduction
The Parallelism operator, also known as Exchange operator, is used to exchange rows between parallel and serial zones of an execution plan, or between parallel zones with different requirements as to how the rows are distributed. The Parallelism operator has three different Logical Operations, that are each represented with different icons in the graphical execution plan. For ease of understanding, each of the three Logical Operations will be described on its own page here.
The Gather Streams operation of the Parallelism operator makes the operator read rows from a parallel zone, so from multiple threads. It outputs those rows into a serial zone, so all combined onto a single thread. The two other logical operations are Distribute Streams (that reads from a serial zone and outputs to a parallel zone) and Repartition Streams (that connects two parallel zones with different distributions).
For a good primer on the basics of parallelism, please read this article by Paul White.
Visual appearance in execution plans
Depending on the tool being used, a Parallelism operator with its Logical Operation set to Gather Streams is displayed in a graphical execution plan as shown below:
|
SSMS and VS Code |
Legacy SSMS |
Plan Explorer |
Paste The Plan |
Algorithm
The Parallelism operator always runs multiple processes on multiple threads at the same time. When the Logical Operation is set to Gather Streams, then Parallelism has one process on each thread on the side that is shown on the right in graphical execution plans, connecting to the child operator of the Parallelism operator on that thread. This side is called the “producer side”. On the other side, called the “consumer side”, just a single process runs, connecting to the serial parent operator of the Parallelism operator.
Producer side
On the producer side, the same process runs on each thread. This process reads rows from the child operator, stores them in a holding area called a “packet”, and initiates a transfer of the packet to the consumer side process when the packet is full.
The basic algorithm for the producer side process of a Parallelism operator with its Logical Operation set to Gather Streams is as shown below:
 Note that this flowchart is a simplification. It does not show the details of what happens when the producer side process tries to push a packet of rows to the consumer side (this is shown in more detail below). It also doesn’t show the details of how a parallel plan starts up its execution. (Paul White has written an excellent series of articles to describe specifically the startup phase: Part 1, Part 2, Part 3, Part 4, Part 5).
Note that this flowchart is a simplification. It does not show the details of what happens when the producer side process tries to push a packet of rows to the consumer side (this is shown in more detail below). It also doesn’t show the details of how a parallel plan starts up its execution. (Paul White has written an excellent series of articles to describe specifically the startup phase: Part 1, Part 2, Part 3, Part 4, Part 5).
Predicate?
The Parallelism operator supports an optional Predicate property. When present, the supplied predicate is applied to every row read in the producer side process. Only rows where the predicate evaluates to True are processed; if the predicate is False or Unknown, the row is discarded.
So far, I have only ever observed Predicate expressions with a PROBE function in their expression.
Push packet
When one of the processes on the producer side has completely filled its packet, or when it has a partially filled packet when the end of data has been reached, then that producer side process pushes the packet to the consumer. This process of pushing a packet to the consumer has its own logic, as follows:
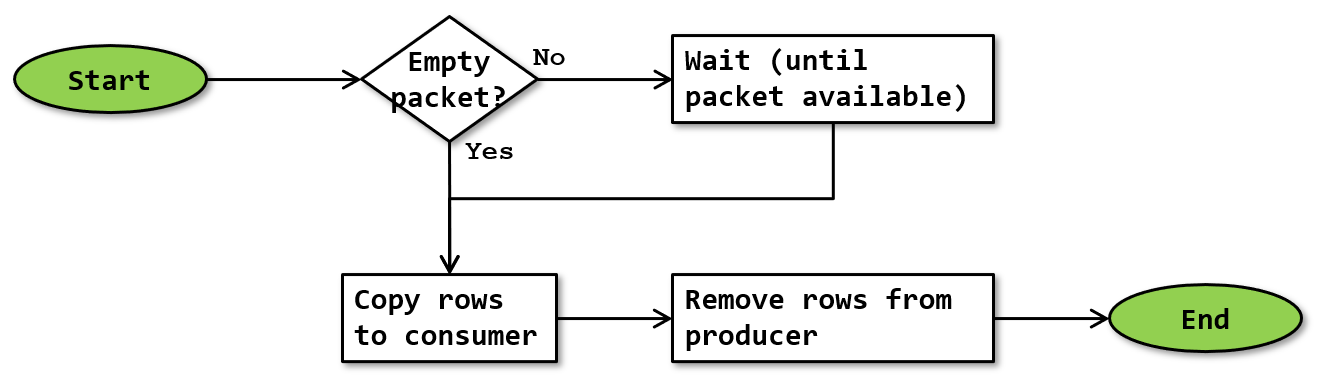 Here, the “Empty packet?” test checks whether the packet corresponding to this thread on the consumer process is empty. If this is not the case, then the consumer side process is still working on the rows sent from this thread in a previous packet, and the producer side on this thread will have to wait until an empty packet is once more available. The producer side processes on the other threads do not have to wait for this; they can continue to work.
Here, the “Empty packet?” test checks whether the packet corresponding to this thread on the consumer process is empty. If this is not the case, then the consumer side process is still working on the rows sent from this thread in a previous packet, and the producer side on this thread will have to wait until an empty packet is once more available. The producer side processes on the other threads do not have to wait for this; they can continue to work.
Once the consumer side packet is empty, the “Push packet” process moves the data in the packet on the producer side to the correct packet on the consumer side, by first copying the data to the packet on the consumer side, and then removing it from the packet on the producer side.
Wait (until packet available)
When the consumer side process has not yet finished processing all rows in a packet before the next packet for the same thread is already available, then the producer side process on this thread cannot continue until the consumer side finishes processing these rows. It enters a wait state, where the process is taken off the processor (so that other SQL Server tasks can use it), and waits until the consumer side has an empty packet available for receiving new rows.
These are the infamous CXPACKET waits. Ideally, we would hope that the consumer side process is able to finish work on all rows in a packet before the next packet from that input thread is ready, so there should be little to no CXPACKET waits. But with many input threads producing data at the same time, and just a single output thread processing the combined data, that is not always the case. And especially when the Parallelism operator is set to be merging (see below), CXPACKET waits can be high. Even more so when the data distribution in the parallel section is skewed.
Consumer side
The process on the consumer side reads data from all of the packets (of which there is one for each producer side thread). It combines them in one of two possible ways (“merging” or “non-merging”) and returns them to its parent operator.
The basic algorithm for the consumer side process of a Parallelism operator with its Logical Operation set to Gather Streams is as shown below:
 Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called.
Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called.
Merging?
The Parallelism operator with its Logical Operation set to Gather Streams can operate in two different ways:
- Merging: A merging Parallelism operator is used when the input streams on all threads are guaranteed to be in a specific order, and the optimizer needs that order to be retained. This introduces some overhead for the Parallelism operator, but it saves the cost of (re)sorting the data after it has been combined on a single thread.
A Parallelism operator is merging when its Order By property is present. The optimizer ensures that the input streams are all already in the correct order; the Parallelism operator is not able to actively reorder data on any of its input streams, it merely combines the data in such a way that the existing order as specified in the Order By property is preserved.
All descriptions in this text are based on an ascending sort order, but a descending sort order is supported as well. Or even a mix of ascending and descending if the Order By property specifies more than one column. - Non-merging: A non-merging Parallelism operator is free to return the data to its parent operator in any order. It will not actively reorder rows, but it will simply return the first row available as soon as it is available. This reduces the amount of CXPACKET and CXCONSUMER waits as compared to a merging Parallelism (Gather Streams) operator.
A Parallelism operator is non-merging when it does not have an Order By
Data in ALL/ANY packets?
When a Parallelism operator with its Logical Operation set to Gather Streams is set to merge its sorted inputs, then it can only safely return a row when it can see the next row from each of its input threads. This means that there has to be data in the packets for all input threads. After all, if just one packet is empty, there is no way to tell whether the next row that will be received in that packet has a lower value in its Order By columns than the first available row in all of the other packets.
When a Parallelism operator with its Logical Operation set to Gather Streams does not have to merge its inputs, then it can safely return rows to its parent from any packet that has data, so there is no need to wait until all packets have data.
Note that when a producer side process sends its end of data signal, this signal is also included in the packet, and never removed. This packet is then considered to hold data for the purpose of deciding if the consumer side process has to wait.
Wait (until data in ALL/ANY packets)
When the consumer side process has to wait for data in its packets, then it either waits until there is data in all packets (for a merging Parallelism operator), or until there is data in at least one packet (for a non-merging Parallelism operator).
These waits used to be marked as CXPACKET waits, but since Service Pack 2 for SQL Server 2016 and Cumulative Update 3 for SQL Server 2017, they have been relabeled as CXCONSUMER waits. These waits will typically be very low when the Parallelism operator is non-merging, because data is produced by multiple parallel processes and has to be further processed on just a single node. And even when they do occur, they are considered benign because the input processes on all of the threads in the parallel section can continue to run without waiting.
For a merging Parallelism operator, CXCONSUMER waits will be higher, because the process stalls when just any of the input threads is stalling. When this does not affect the processes on any of the threads in the parallel section, then this is a benign wait. However, it is also possible that, while the consumer side is waiting for more data from one thread, another thread already has a new packet of data available to be pushed. Now that thread on the parallel side is halted, with a CXPACKET wait (see above).
In all cases, the CXCONSUMER waits are not a reason to worry. (Before these waits were relabeled as CXCONSUMER, it was a lot harder to troubleshoot parallelism, because benign and actionable waits were all registered under the same wait type).
Read row from packet
The consumer side process of a Parallelism operator with its Logical Operation set to Gather Streams has multiple packets, one for each process on the producer side. So when it reads data, it can choose from which packet to read. How this choice is made depends on the behavior of the operator:
- Merging: A merging Parallelism operator compares the values in the Order By columns of the first row in each of the packets, to find which packet currently holds the lowest Order By It then reads the row from that packet.
In case of a tie between one or more packets (same value in all Order By columns), it will choose one of the packets with this lowest value. Which of the candidates is selected is not documented. - Non-merging: A non-merging Parallelism operator can select any of the packets that still hold at least one row of data. Which of the candidates is selected is not documented.
Operator properties
The properties below are specific to the Parallelism operator with its Logical Operation set to Gather Streams, or have a specific meaning when appearing on it. For all other properties, see Common properties. Properties that are included on the Common properties page but are also included below for their specific meaning for the Constant Scan operator are marked with a *.
| Property name | Description |
|---|---|
| Order By | This property can be present or absent. When it is absent, the Parallelism operator will use its non-merging operation. When the Order By property is included, it will list one or more columns, each with a “Descending” or “Ascending” specification. The data streams on all input threads will be ordered according to that specification, and the Parallelism will use its merging operation to ensure that this order is retained in the output stream. See the main text for more details. |
| Predicate | When present, this property defines a logical test to be applied to all rows that the producer side processes read. Only rows for which the predicate evaluates to True are returned. |
Implicit properties
This table below lists the behavior of the implicit properties for the Parallelism operator with its Logical Operation set to Gather Streams.
| Property name | Description |
|---|---|
| Batch Mode enabled | The Parallelism operator with its Logical Operation set to Gather Streams only appears in row mode execution plans, or in row mode sections of batch mode execution plans. Batch mode (sections of) execution plans use a different model for parallelism, where no Parallelism operators are needed. |
| Blocking | The Parallelism operator is non-blocking. |
| Memory requirement | The Parallelism operator with its Logical Operation set to Gather Streams requires enough memory to store one packet for each process on the producer side, and a number of packets equal to the degree of parallelism on the consumer side. Unlike most other operators with high memory consumption, the Parallelism operator does not expose the Memory Fractions and Memory Usage properties. |
| Order-preserving | The Parallelism operator with its Logical Operation set to Gather Streams is only order-preserving when it is merging. When it is non-merging, then the output of this operator is always considered unordered. See the main text for more details on merging versus non-merging behavior. |
| Parallelism aware | The Parallelism operator is only used in parallel execution plans, and is fully parallelism aware. |
| Segment aware | The Parallelism operator is not segment aware. |
Change log
(Does not include minor changes, such as adding, removing, or changing hyperlinks, correcting typos, and rephrasing for clarity).
May 17, 2023: Added.
June 1, 2023: Added description of the Predicate property in main text and property list and updated flow charts to reflect the logic of the Predicate property. Fixed an error in the flowchart for the consumer side process.