UDX
Introduction
The UDX operator implements several “Extended Operators”. These are used to implement one of many XQuery, XPath, and (since SQL Server 2016) JSON operations in SQL Server. Depending on the specific Extended Operator implemented, they either aggregate the data from all input rows into one or a few output rows, or they evaluate expressions based on values in the current row only to output a single row with extra columns added, or even multiple rows.
Visual appearance in execution plans
Depending on the tool being used, a UDX operator is displayed in a graphical execution plan as shown below:
|
SSMS and ADS |
Legacy SSMS |
Plan Explorer |
Paste The Plan |
Algorithm
The basic algorithm for the UDX operator is as shown below:
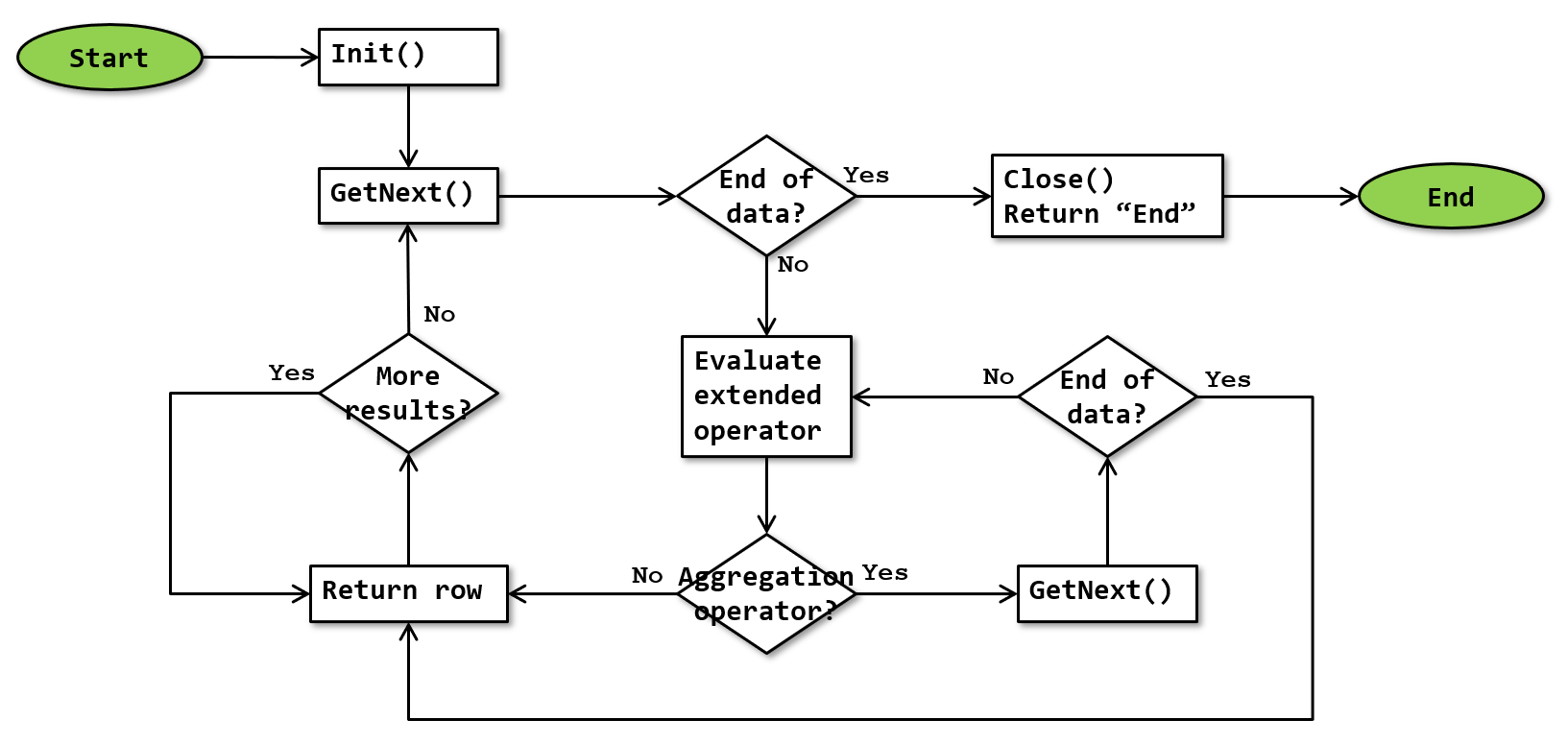 Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called. It also does not show the logic needed to prevent one extra GetNext() call to the child operator after reaching the end of the input when the extended operator is an aggregate operator.
Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called. It also does not show the logic needed to prevent one extra GetNext() call to the child operator after reaching the end of the input when the extended operator is an aggregate operator.
Evaluate extended operator
The exact operation of the UDX operator depends on the specific extended operator, as indicated by the Extended Operator property. Below you will find an alphabetically sorted list of all currently known extended operators of UDX. If you ever encounter an execution plan where a UDX operator has a value in the Extended Operator property that is not in the list below, please let me know.
FOR JSON
The FOR JSON extended operator is an order-sensitive JSON aggregation operator that serializes the relational data it receives into JSON representation, and outputs a single BLOB column with a JSON representation of the input data. It is typically used for queries that use FOR JSON in a subquery.
The Used UDX Columns property lists all the columns from the input data that need to be included, in the listed order, in the generated JSON string. The Defined Values property lists the single output column, which is an nvarchar(max) column holding a string representation of the serialized JSON.
Note that T-SQL supports two versions of FOR JSON: AUTO and PATH, that can both be further modified by the ROOT, INCLUDE_NULL_VALUES, and WITHOUT_ARRAY_WRAPPER options. None of these specifications are visible in the graphical execution plan, nor in the execution plan XML. I assume that these behavior specifications are encoded in the internal representation of the execution plan, but that they are not included in the conversion to the execution plan XML when it is requested by the client.
FOR XML
The FOR XML extended operator is an order-sensitive XML aggregation operator that serializes the relational data it receives into XML representation, and outputs a single BLOB column with an XML representation of the input data. It is typically used for queries that use FOR XML in a subquery.
The Used UDX Columns property lists all the columns from the input data that need to be included, in the listed order, in the generated XML string. The Defined Values property lists the single output column, which is an nvarchar(max) column holding a string representation of the serialized XML.
Note that T-SQL supports four versions of FOR XML: AUTO, EXPLICIT, PATH, and RAW; each with their own further options. None of these specifications are visible in the graphical execution plan, nor in the execution plan XML. I assume that these behavior specifications are encoded in the internal representation of the execution plan, but that they are not included in the conversion to the execution plan XML when it is requested by the client.
XML FRAGMENT SERIALIZER
The XML FRAGMENT SERIALIZER extended operator is an order-sensitive XML aggregation operator that serializes the XML data it receives into XML representation, and outputs it as a single XML fragment, in xml format. This is typically used in execution plans for queries that use the xml.modify method to insert data in existing XML.
The Used UDX Columns property lists up to 17 columns. The first 11 columns are the id, nid, taguri, tagname, tid, value, lvalue, lvaluebin, hid, xsinil, and xsitype columns that, combined, represent an XML fragment. The function of the other columns is currently unknown.
The Defined Values property lists the single output column, which is an xml column holding the serialized XML fragment.
XML SERIALIZER
The XML SERIALIZER extended operator is an order-sensitive XML aggregation operator that serializes the XML data it receives into XML representation, and outputs it as a single XML column.
The Used UDX Columns property lists up to 20 columns. The first 11 columns are the id, nid, taguri, tagname, tid, value, lvalue, lvaluebin, hid, xsinil, and xsitype columns that, combined, represent an XML fragment. The function of the other columns is currently unknown.
The Defined Values property lists the single output column, which is an xml column holding the serialized XML.
XQUERY DATA
The XQUERY STRING extended operator is an order sensitive string aggregation operator, that evaluates an fn:data() function against the XML data in the input rows. According to the Microsoft documentation, it outputs a single row “with columns representing XQuery scalar” that contains the result of this fn:data() function.
Note that the argument between the parentheses of the fn:data() function is not visible in the graphical execution plan, nor in the execution plan XML. I assume that this is encoded in the internal representation of the execution plan, but that it is not included in the conversion to the execution plan XML when it is requested by the client.
The Used UDX Columns property lists up to 10 columns. The first 6 columns seem to be the id, nid, tid, value, lvalue, and lvaluebin of an XML fragment; the function of the 7th column is currently unknown. Column 8 appears to be the primary key value of a row in a nonclustered xml index, and the last two columns are both id values of XML documents.
The Defined Values property lists up to five output columns. The first represents a node_id in an internal table, the function of the second output column is currently unknown, and the last three output functions are the value, lvalue, and lvaluebin columns from the XML fragment that represents the output of the extended operator.
XQUERY LIST CONTAINS
The XQUERY CONTAINS extended operator is an order sensitive string aggregation operator. According to the Microsoft documentation, it outputs a single row “with columns representing XQuery scalar” that contains the result of an XQuery fn:contains() function.
I have not yet seen or been able to construct any execution plans where this extended operator is used. Hence I do not know the exact usage of the Used UDX Columns and Defined Values properties for this extended operator.
Have you seen a UDX operator that implements the XQUERY CONTAINS extended operator? Then you can help me! Please save it as a .sqlplan file, or create a stand-alone repro script, and send it to me.
XQUERY LIST DECOMPOSER
The XQUERY LIST DECOMPOSER extended operator is an XQuery list decomposition operator. For each input row representing an XML node it produces one or more rows each representing XQuery scalar containing a list element value if the input is of XSD list type.
I have not yet seen or been able to construct any execution plans where this extended operator is used. Hence I do not know the exact usage of the Used UDX Columns and Defined Values properties for this extended operator.
Have you seen a UDX operator that implements the XQUERY LIST DECOMPOSER extended operator? Then you can help me! Please save it as a .sqlplan file, or create a stand-alone repro script, and send it to me.
XQUERY STRING
The XQUERY STRING extended operator is an order-sensitive string aggregation operator, that evaluates the XQuery string value of input rows against their XML data to output a single row with the XQuery scalar that holds the result.
Note that the actual text of the XQuery string to evaluate is not visible in the graphical execution plan, nor in the execution plan XML. I assume that this is encoded in the internal representation of the execution plan, but that it is not included in the conversion to the execution plan XML when it is requested by the client.
The Used UDX Columns property lists up to 19 columns. The first 11 columns are the id, nid, taguri, tagname, tid, value, lvalue, lvaluebin, hid, xsinil, and xsitype columns that, combined, represent an XML fragment. Columns 18 and 19 appear to be the primary key value of a row in a nonclustered xml index and the id value of an XML document or fragment, respectively. The function of the other columns is currently unknown.
The Defined Values property lists two output columns, which are the lvalue and value columns from the XML fragment that represents the output of the extended operator.
XQUERY UPDATE XML NODE
The XQUERY STRING extended operator applies the XQuery modify() function to the XML data in its input, to return a row with the results of the specified modify() function.
The Used UDX Columns property lists up to 32 columns. The first 11 columns are the id, nid, taguri, tagname, tid, value, lvalue, lvaluebin, hid, xsinil, and xsitype columns that, combined, represent an XML fragment. The function of the other columns is currently unknown.
The Defined Values property lists up to 32 output columns, that together represent the results of applying the update() function on the input. The function of each of these columns is currently unknown.
Aggregation operator?
The list of extended operator can be divided into two groups, depending on whether they produce output for each input row (regular extended operator: XQUERY LIST DECOMPOSER and XQUERY UPDATE XML NODE), or whether they read and accumulate data from all input rows first, and then produce their output based on the data in all input rows (aggregation operators: all other extended operators listed above). Aggregation operators are always order sensitive: the optimizer ensures that the input is produced in the correct order for the results to be as expected.
More results?
One of the extended operators that UDX implements (XQUERY LIST DECOMPOSER) can return multiple output rows from a single input row. So when this extended operator is used, the operator will not instantly move to the next input row after returning a row and receiving back control, but it will first test if it has already returned all output rows for the current input row.
The flowchart above also allows for an aggregation operator to return multiple output rows. As far as known, there are currently no extended operators that use this feature. It is possible that Microsoft has chosen for an architecture where the “More results?” check is not used for aggregation operators.
Operator properties
The properties below are specific to the UDX operator, or have a specific meaning when appearing on it. For all other properties, see Common properties. Properties that are included on the Common properties page but are also included below for their specific meaning for the UDX operator are marked with a *.
| Property name | Description |
|---|---|
| Defined Values * | Each extended operator that UDX implements has its own results format (number of columns and function of each column). The Defined Values property maps the results to output columns, by listing the names of the output columns to use. The mapping of each result column to the output column is by position in the list, so no explicit specification is provided. |
| Output List * | When UDX implements an extended operator that does some form of aggregation, it can only include columns from the Defined Values in its Output List. However, it does not necessarily always include all the columns listed in the Defined Values. For the regular extended operators (XQUERY LIST DECOMPOSER and XQUERY UPDATE XML NODE), the Output List can also include additional columns, that are then copied unchanged from the current row received from the child operator. |
| Used UDX Columns | Each extended operator that UDX implements requires a number of input parameters. The number of parameters can be variable (for FOR JSON and FOR XML) or fixed. Data from the child operator of UDX is mapped to those parameters in the Used UDX Columns property. The mapping of the input columns to parameters is done by position in the list, rather than by name. |
Implicit properties
This table below lists the behavior of the implicit properties for the UDX operator.
| Property name | Description |
|---|---|
| Batch Mode enabled | The UDX operator supports row mode execution only. |
| Blocking | The UDX operator is non-blocking. |
| Memory requirement | The UDX operator does not have any special memory requirement. |
| Order-preserving | The UDX operator is fully order-preserving. |
| Parallelism aware | The UDX operator is not parallelism aware. |
| Segment aware | The UDX operator is not segment aware. |
Change log
(Does not include minor changes, such as adding, removing, or changing hyperlinks, correcting typos, and rephrasing for clarity).
January 16, 2024: Added.