Key Lookup
Introduction
The Key Lookup operator provides a subset of the functionality of the Clustered Index Seek operator, but within a specific context. It is used when another operator (usually an Index Seek, sometimes an Index Scan, rarely a combination of two or more of these or other operators) is used to find rows that need to be processed, but the index used does not include all columns needed for the query. The Key Lookup operator is then used to fetch the remaining columns from the clustered index.
A Key Lookup operator will always be found on the inner input of a Nested Loops operator. It will be executed once for each row found. Since the key values passed in always come from another index, the requested row will always exist (except in rare race scenarios when read uncommitted isolation level is used).
Since a Key Lookup is only used in situations where the key values have been retrieved from another index (including the internal uniqueifier column in the case of a clustered index that is not declared to be unique), it always operates as a singleton seek, never as a range seek.
Visual appearance in execution plans
Depending on the tool being used, a Key Lookup operator is displayed in a graphical execution plan as shown below:
|
SSMS and ADS |
Legacy SSMS |
Plan Explorer |
Paste The Plan |
The icon design is a bit strange, especially when compared to the icon design of the RID Lookup operator, and the design of other operators that depict either an action on a heap, or an action on a clustered index. My theory is that the icons for Key Lookup and RID Lookup were accidentally switched when they were introduced in SQL Server 2005, and then Microsoft didn’t want to change it later for fear of causing even more confusion.
Algorithm
Based on the history of this operator (see below), it is safe to assume that the Key Lookup operator actually uses the same logic as the Clustered Index Seek operator (which in turn is the same logic as the Index Seek operator). See that page for the full description of that operator.
However, since a Key Lookup never has more than a single Seek Keys property and can only operate as a singleton seek, a lot of the logic in that flowchart is irrelevant to this operator. For easier understanding, the flowchart below shows only the logic that can actually be used by the Key Lookup operator:
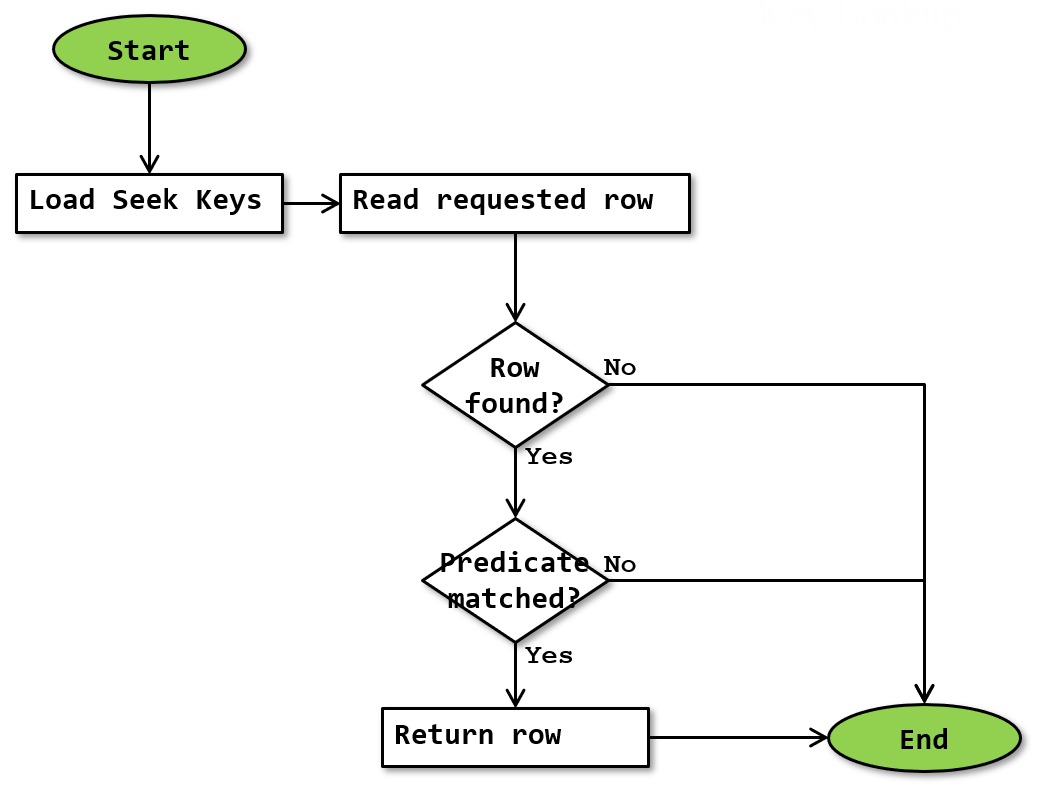
Note that, depending on the transaction isolation level that is in effect for the index being read, locks may be taken and released as rows are accessed. This is part of the responsibility of the storage engine, and a detailed discussion of this functionality is beyond the scope of this website.
Seek Keys
The Seek Keys specification of a Key Lookup operator only uses a subset of the available functionality in the generic (Clustered) Index Seek operator. For a Key Lookup, only the Prefix Specification is used, and it always specifies all key columns. For a Key Lookup on a clustered index that is not declared to be unique, this includes the hidden internal uniqueifier column. Within the execution plan, this column is named using the mnemonic prefix “Uniq”, followed by a unique 4-digit number.
For a Key Lookup into a clustered columnstore index, the Seek Keys always lists a single column, the hidden internal column for the location of a row within the columnstore index. Within the execution plan, this column is named using the mnemonic prefix “ColStoreLoc”, followed by a unique 4-digit number.
Predicate
The Key Lookup operator supports the optional Predicate property, just as the (Clustered) Index Seek does. A Predicate property will typically be used in a Key Lookup when a query has a filter that can be effectively used by a nonclustered index, but also has filters on columns not included in that nonclustered index.
The operator uses the Seek Keys specification to find the indicated row, reads it, but then first checks the Predicate property to determine whether to return the row, or return an end of data signal.
Variations by index type
The flowchart above shows the basic outline of Key Lookup processing. Some of the actions can vary depending on the type of index that is used in the Index Seek. In the paragraphs below these differences are detailed per type of index.
RowStore
For a RowStore clustered index (Storage = “RowStore”), the Key Lookup operator uses the B-tree structure of the index to find the requested row. If the index is not defined as unique, then the value of the hidden uniqueifier column will be read from a nonclustered index elsewhere in the execution plan and passed to the Key Lookup, in an internal column named “Uniq” + a unique 4-digit number.
For the “Read requested row” action, the internal data structures (which can be seen through the sys.sysindexes view) are used to find the location of the root page. It brings that page into the buffer pool and compares the values of the indexed columns in each entry (in correct logical order, based on the row offset table on the page) to the specifications in the Seek Keys specification. As soon as it finds an entry for which the values in all columns in the Prefix conditions are equal to or greater (lesser for descending index columns) than the specified target values, it goes back one entry (to the last entry that does not satisfy these conditions) to find the page to process at the next lower level. (If the very first entry already matches the conditions, then there is no prior entry and the first entry itself will be followed).
It now brings the page to process at the next lower level into the buffer pool and checks the page header. If the page is an intermediate level index, it is processed the same way as the root page to find the page at the next deeper level. This repeats until a leaf page is found.
Once a leaf page is found, it once more compares the values of the indexed columns in each row (in correct logical order, based on the row offset table on the page) to the specifications in the Seek Keys specification until it finds the row for which the values in all columns in the Prefix conditions are equal to the specified target values. This is the row to be returned (depending on the Predicate check, if needed).
When the read uncommitted isolation level is used, it is theoretically possible that the row to be returned does not exist in the clustered index. In that case, obviously, no row will be returned.
ColumnStore
For a ColumnStore clustered index (Storage = “ColumnStore”), the key operator uses an internal column that specifies the exact location of the row within the clustered index. This internal column is stored in the leaf pages of all nonclustered indexes on the table. It will be read elsewhere in the execution plan and passed to the Key Lookup, in an internal column named “ColStoreLoc” + a unique 4-digit number.
The structure and contents of this internal column are not documented. Based on my understanding of how columnstore indexes are designed, I have to assume that they include an identification of the rowgroup (probably its number), and an identification of the row within that rowgroup (probably an ordinal to represent its position). But since the row might be in an open rowgroup (aka delta store), the ColStoreLoc column should also be able to identify the row within the B-tree that stores the data within that open rowgroup.
Using the data in the internal ColStoreLoc column, the storage engine can immediately access the requested row. If the Predicate property is present and the ColStoreLoc column indicates a compressed rowgroup, the min_data_id and max_data_id columns in sys.column_store_segments (for the colums listed in the Predicate) are checked; if the data within the rowgroup can impossibly match the Predicate, the row is not accessed at all. If it can, then the data in the rowgroup is decompressed to fetch the requested row, the Predicate (if present) is checked, and if it qualifies the row is returned.
When the read uncommitted isolation level is used, it is theoretically possible that the row to be returned does not exist in the clustered columnstore index. In that case, obviously, no row will be returned.
Since the internal column indicates the exact location of the row within the clustered columnstore index, I consider a Key Lookup operator on a clustered columnstore index to be actually more like a variation of the RID Lookup operator than a variation of the Key Lookup operator, but that is not how Microsoft has classified it.
MemoryOptimized
Due to how memory optimized indexes are designed, a Key Lookup for this type of index is never required. Even though all memory optimized indexes are labeled “nonclustered”, they still give access to all data so there is never a need to request additional data by using a lookup operator.
Operator properties
The properties below are specific to the Key Lookup operator, or have a specific meaning when appearing on it. For all other properties, see Common properties. Properties that are included on the Common properties page but are also included below for their specific meaning for the Key Lookup operator are marked with a *.
| Property name | Description |
|---|---|
| Actual I/O Statistics * | When the Key Lookup targets a columnstore index, then the data in the Actual I/O Statistics is not correct. The Actual Scans subproperty is set equal to the number of threads where the Key Lookup executed at least once; all other metrics always show zero. Please refer to the SET STATISTICS IO output to see the actual amount of I/O done by a Key Lookup operator on a columnstore index. |
| Defined Values * | For a Key Lookup, this property lists the columns read from the index and returned to the calling operator. It is therefore the same as the Output List property. |
| Estimated Number of Rows * | Normally this is an estimation of how many rows the operator will return per execution. Has to be multiplied to Estimated Number of Executions to get the estimated total number of rows (which can then be compared to the Actual Number of Rows). Determined during query optimization. Renamed in Management Studio 18.5 to Estimated Number of Rows Per Execution. Specifically for the Key Lookup operator, if a Predicate property is present then this number represents the estimated total of rows for all executions instead of the estimated number of rows per execution. |
| Estimated Number of Rows for All Executions * | This property does not actually exist in the execution plan. It was introduced in Management Studio 18.5, as the result of multiplying Estimated Number of Rows Per Execution and Estimated Number of Executions; the result can easily be directly compared to the Actual Number of Rows for All Executions. Specifically for the Key Lookup operator, if a Predicate property is present then the Estimated Number of Rows Per Execution, in spite of its name, actually represents the estimated total of rows for all executions instead of the estimated number of rows per execution. This property will then still be computed by multiplying that number by the Estimate Number of Executions, resulting in a useless number. |
| Estimated Number of Rows Per Execution * | Normally this is an estimation of how many rows the operator will return per execution. Has to be multiplied to Estimated Number of Executions to get the estimated total number of rows (which can then be compared to the Actual Number of Rows for All Executions). Determined during query optimization. In Management Studio 18.4 and older and in Azure Data Studio, this property is called Estimated Number of Rows. Specifically for the Key Lookup operator, if a Predicate property is present then, despite the name, this number actually really represents the estimated total of rows for all executions instead of the estimated number of rows per execution. |
| Forced Index | This property is set to true if the query used an index hint to force the use of the nonclustered index where the input to this operator’s Seek Predicates property originates from. |
| ForceScan | This property is set to true if the query used a FORCESCAN hint to force the use of a scan operator even if the optimizer would rather use a seek operator. |
| ForceSeek | This property is set to true if the query used a FORCESEEK hint to force the use of a seek operator even if the optimizer would rather use a scan operator. |
| Lookup | Always set to true. |
| NoExpandHint | This property is set to true if the NOEXPAND hint was used in the query to force the optimizer to use indexes on an indexed view. |
| Number of Rows Read | This is the number of rows that was read by the operator as it was navigating the index. In a parallel execution plan, this property shows a breakdown of rows on each individual thread. The difference between this property and the Actual Number of Rows property represents the number of rows that was read but not returned due to the Predicate property. This property is not included for a Key Lookup on a columnstore index. Only available in execution plan plus run-time statistics. When the number of rows read is equal to zero, this property is omitted. |
| Object | This property lists the clustered index that the Key Lookup reads from, using four part naming (database, schema, table, index) and optionally followed by a table alias. |
| Ordered | This property is always equal to True for a Key Lookup. |
| Predicate | When present, this property defines a logical test to be applied to all rows that are read by the Key Lookup. Only rows for which the predicate evaluates to True are returned. When possible, the Key Lookup operator will push this predicate into the storage engine to prevent extra roundtrips between the operator and the storage engine. Note that a Predicate on a Key Lookup does not reduce the amount of rows that is touched by the operator. The difference between the Actual Number of Rows and the Number of Rows Read property (or their estimated counterparts) shows how many rows were read but not returned. This can be used to gauge how useful an index would be that better supports the search predicates. Also note that when a Predicate property is used, the Estimated Number of Rows, Estimated Number of Rows Per Execution, and Estimated Number of Rows for All Executions properties will be wrong, as detailed above. |
| Scan Direction | This property is always set to FORWARD on a Key Lookup. It is not used. |
| Seek Predicates | This property lists the Seek Keys property that is used to navigate the index and locate the row to be read. See the main text for more information. |
| Storage | This property determines the type of index being navigated. (Note that this could also be determined by using the DMVs based on the Object property). Possible values for a Key Lookup are RowStore and ColumnStore. |
| Table Cardinality | This property shows the number of rows in the index’s table when the plan was last compiled. |
Implicit properties
This table below lists the behavior of the implicit properties for the Key Lookup operator.
| Property name | Description |
|---|---|
| Batch Mode enabled | The Key Lookup operator supports row mode execution only. |
| Blocking | The Key Lookup operator is non-blocking. |
| Memory requirement | The Key Lookup operator does not have any special memory requirement. |
| Order-preserving | The Key Lookup operator is fully order-preserving, since it can only return a single row per execution. |
| Parallelism aware | The Key Lookup operator is not parallelism aware. |
| Segment aware | The Key Lookup operator is not segment aware. |
Change log
(Does not include minor changes, such as adding, removing, or changing hyperlinks, correcting typos, and rephrasing for clarity).
April 19, 2020: Added.
May 20, 2020: Added description of unexpected behavior of Estimated Number of Rows, Estimated Number of Rows Per Execution, and Estimated Number of Rows for All Execution properties when a Predicate property is present and corrected the description of the Forced Index property.
May 30, 2021: Added notes about a bug in the interaction of the Actual I/O Statistics property when reading data from columnstore indexes.