Nested Loops
Introduction
The Nested Loops operator is one of four operators that join data from two input streams into a single combined output stream. As such, it has two inputs. The outer input (sometimes also called the left input) is pictured on the top in a graphical execution plan. The inner (or right) input is at the bottom.
Nested Loops is most effective join operator when the outer input has a low estimated cardinality, and the inner input has a low estimated cost per execution. The alternatives are Merge Join (ideal for joining data streams that are sorted by the join key), Hash Match (most effective for joining large unsorted sets), and Adaptive Join (which can be used when the optimizer finds viable plans for both Nested Loops and Hash Match and wants to postpone the final choice until run time).
The Nested Loops operator supports only four logical join operations: inner join, left outer Join, left semi join, and left anti semi join.
Visual appearance in execution plans
Depending on the tool being used, a Nested Loops operator is displayed in a graphical execution plan as shown below:
|
SSMS and VS Code |
Legacy SSMS |
Plan Explorer |
Paste The Plan |
Algorithm
The basic algorithm for the Nested Loops operator is as shown below:
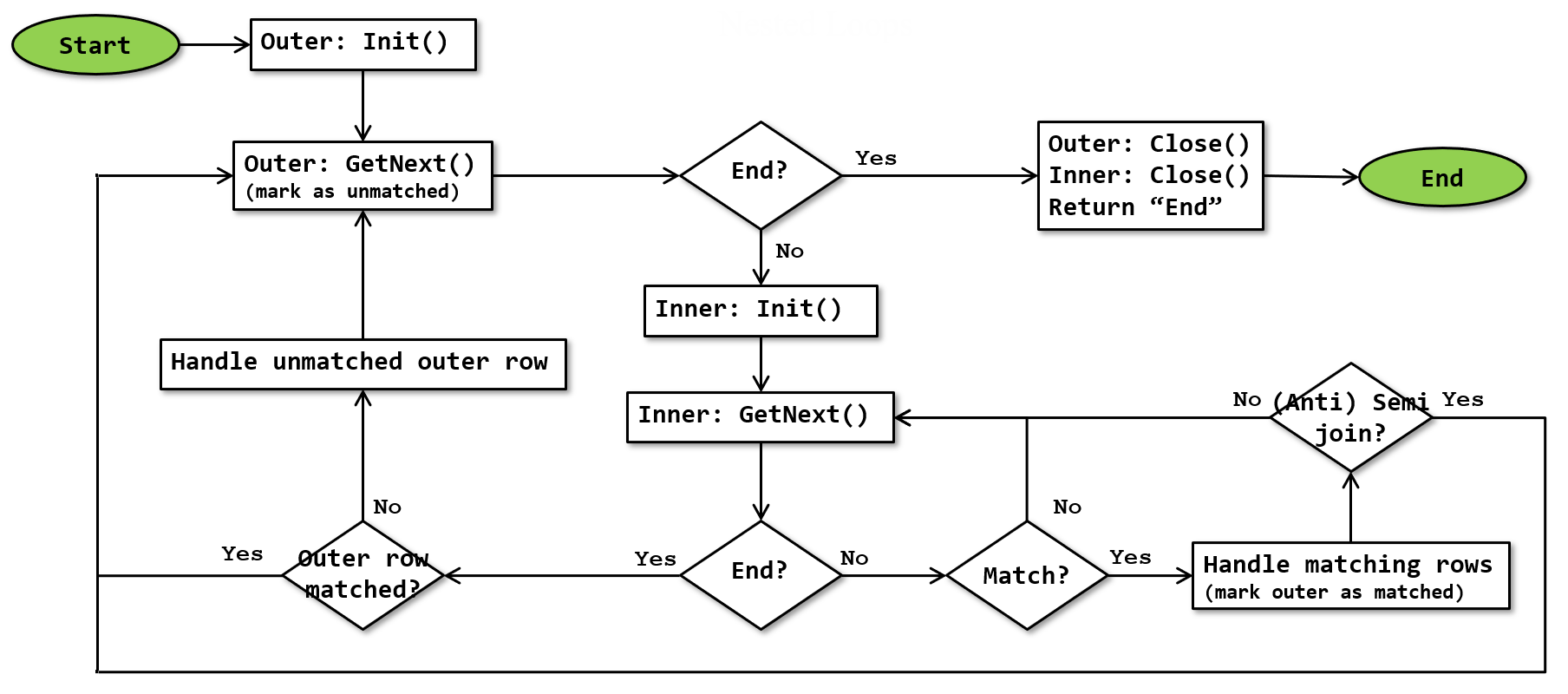 Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called. It also doesn’t show the extra logic to handle the optional optimizations described below.
Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called. It also doesn’t show the extra logic to handle the optional optimizations described below.
The flowchart shows the origin of this operator’s name. The inner loop, that processes data from the inner input, is nested inside the outer loop that processes the outer input. There will be one full execution (initialization plus retrieval of all rows) of the inner input for each row in the outer input.
In this post you can see some nice (slightly simplified) animations showing the algorithm in action. Thanks, Bert!
Variations by join type
The flowchart above shows the basic outline of Nested Loops processing. Depending on the requested join type (the logical operation), some of the steps will change.
Inner Join
For an inner join, “Handle matching rows” returns the combined data to the calling operator. On the next call, execution resumes in the “(Anti) Semi join?” test. This is not a semi or anti semi join, so the algorithm continues in the inner loop, to check if more matching rows can be found.
Unmatched rows are not returned by an inner join, so “Handle unmatched outer row” does nothing for this join type. Because of that, the “Outer row matched?” test becomes irrelevant, and that in turns suggests that there is no need to track whether the outer row was matched. It is unknown whether this operator is actually implemented to test the logical operation and then skip these steps, or whether Microsoft chose to simply run these steps in all cases.
Left Outer Join
A left outer join handle matching data exactly the same as an inner join. The actions in “Handle matching rows” and “(Anti) Semi join?” are the same here as they are for an inner join.
Since a left outer join also has to return unmatched rows from the left (outer) input, the action in “Handle unmatched outer row” is to return a row as well. This row consists of data from the outer input, with null values for columns from the inner input. Because the operator can return a row (and pass control) from two different locations, it needs to store (internally) in what location to continue on the next call.
Left Semi Join
The left semi join operation returns data from “Handle matching rows”. The data returned will be from the outer input only. After regaining control, the “(Anti) Semi join?” causes the algorithm to immediately abandon the inner loop: after finding a single match, no effort will be expended to look for further matches.
Because unmatched rows from the outer input are not returned by a left semi join, “Handle unmatched outer row” does nothing. The “Outer row matched?” test and the actions that facilitate this test are also irrelevant. As stated above, it is unknown if they are still executed or actually skipped.
Left Semi Join (probed)
A Nested Loops (Left Semi Join) executes as a probed left semi join if the Probe property is present. This property then gives the name of the probe column. You will also find the probe column in the Defined Values property (without specification), and in the Output List.
The probed left semi join returns all rows from the left input, whether or not a match exists in the right input. So both “Handle matching rows” and “Handle unmatched outer row” return a row. The only difference is the value assigned to the Probe column. As with the normal left semi join, the “(Anti) Semi join?” tests ensures that processing for each outer row stops after finding the first matching row in the inner input.
Because the inner loop terminates after finding a match, the “Outer row matched?” test can only result in “No” when control actually passes to that part of the flowchart. As such, it is again possible to skip this test and skip the steps to track whether a row was matched. And again, it is not known whether or not Microsoft coded the operator that way.
Left Anti Semi Join
For a left anti semi join , “Handle matching rows” does nothing; the “(Anti) Semi join?” test after it will immediately break from the inner loop. In other words, it immediately moves to the next outer row upon finding but a single match in the inner input.
The “Outer row matched?” test can only branch to “No” in this case, because control never gets here when a match exists. This test and the logic to track this can be skipped in this logical operation as well. The “Handle unmatched outer row” then is where a row is returned to the caller.
As with the other logical operations, it is unknown whether or not Microsoft has actually built conditional logic to skip steps that do nothing, or whether they found it to be faster to just execute it regardless.
Variations by inner input type
The inner input of a Nested Loops operator can be static (meaning it will normally return the same data every time it is executed, barring changes to the data from other sources), or it can be dynamic (meaning that the execution plan itself contains logic to change the rows returned on each execution based on the current outer row).
A static inner input is usually less efficient than a dynamic inner input. The optimizer typically only chooses a static inner input if a dynamic inner input is not possible or not practical.
Static inner input
A static inner input can be recognized by the absence of the Outer References property. Because no values from the outer input are pushed into the inner input, the operators on the inner input will usually return the exact same set of data on every execution. This is not always the case though. Depending on the chosen transaction isolation levels, concurrent transactions can modify data being read in the inner input while the query is running. Further, a Table Spool on the inner input can also produce different data on subsequent executions due to actions of other operators in the plan.
Almost every Nested Loops operator with a static inner input has a Predicate property. This property is tested in the “Match?” test in the flowchart above. If the Predicate property is absent, every row is considered a match; this is for instance the case for queries that contain a CROSS JOIN.
Dynamic inner input
A dynamic inner input can be recognized by the presence of the Outer References property. This property shows which columns from the outer input are pushed into the inner input in an effort to remove non-qualifying rows as early as possible. Operators on the inner input use these pushed down values to eliminate rows that do not qualify; only qualifying rows are returned.
Based on observing execution plans, I think that the Outer References and Predicate properties are mutually exclusive. In other words, when any logic to eliminate non-matching rows is pushed into the inner input, then all such logic is pushed there. All rows returned from the inner input are matches by definition. The “Match?” test in the flowcharts above, where the Predicate property is tested, will therefore always return true for a dynamic inner input.
(If you ever see an execution plan with a Nested Loops operator that has both a Predicate and an Outer References property, please let me know!)
Rebinds and rewinds
Every time the inner input of a Nested Loops join initializes counts as a separate execution. Each of these executions is either a “rebind” or a “rewind”. The difference between the two is irrelevant for most operators, but some change their behavior based on the type of execution. Generally, these are operators that have the data they produced in the previous execution stored somewhere.
When a dynamic inner input of a Nested Loops restarts execution but the values of all Outer References columns is the same as for the previous execution, it is a rewind. Operators that care about the difference usually have some way to return the required rows without invoking their child operators. This is often more efficient. When the dynamic inner input restarts but the Outer References values change, it is a rebind. Because a new value is pushed into the inner input, all its operators have to start over to ensure that the correct data is produced.
A static inner input has no Outer References columns. The first execution here is always a rebind; all others are rewinds.
Operators that are not in the inner input of a Nested Loops have only a single execution (or a single execution per thread in a parallel plan), which is a rebind by definition.
Since every execution is either a rebind or a rewind, the sum of the number of rebinds and the number of rewinds for any operator is always equal to the total number of executions.
Optimizations
Because of how a Nested Loops operator works, data access in the inner input tends to follow semi-random patterns. Without additional measures, this results in relatively slow disk access on spinning disk (which was the norm when SQL Server was built), and limited read-ahead capacity. Both of these slow down processing so much that the Nested Loops operator can use some specific optimizations to help counter these issues. Even in SQL Server 2017 and running on modern hardware (SSD’s and lots of memory), these optimizations are still active.
Optimized Nested Loops
A so-called “optimized” Nested Loops tries to improve efficiency of the inner input by reordering the data from the outer input such that the data on the inner input is processed in an order that benefits more from sequential access patterns.
An optimized Nested Loops tries to read the entire outer input into memory when first called, then reorders it using a limited, “best effort” sorting algorithm. These sorted rows are then used, one by one, to drive the inner loop and produce the output rows.
The optimized Nested Loops algorithm doesn’t spill to tempdb. If there is insufficient memory to store all rows from the outer input, it simply stores as many rows as it can fit, then proceeds to reorder and process them. Once they are all processed, the operator returns to the outer input, reading its remaining rows into memory to be sorted, etc. This repeats as often as needed. Because of this design, rows from the inner input are not read into memory by the Init() method (as is the case for most other memory-using operators), but by the GetNext() method.
The output of an optimized Nested Loops join is “highly unlikely to be fully sorted”. The optimizer considers the output of an optimized Nested Loops join to be unsorted.
Unlike a “normal” Nested Loops join, an optimized Nested Loops join is semi blocking. When enough memory is available, it will block while processing the outer input, then stream while iterating over the sorted rows and reading from the inner input. When memory is insufficient, it will block while reading the first set of rows into memory and sorting them, stream while processing, block again while reading and sorting the next set of rows from the outer input, etc.
For more information on the optimized Nested Loops algorithm, see Craig Freedman’s blog post.
Prefetching
Prefetching can be used with a dynamic inner input to optimize the read-ahead capabilities of the storage engine. Normally, when the outer input is not sorted by the Outer References column(s), the reads in the inner input will be in a more or less random order. This defies the regular read-ahead process. That is where prefetching comes in.
With prefetching enabled, the Nested Loops operator reads multiple rows from the outer input instead of just a single row, then issues an asynchronous scatter read request to the disk subsystem for all of the values just read from the outer input. While the first execution of the inner input is busy, the disk subsystem is working in the background. Later executions of the inner input should usually find the data they need already in the buffer pool.
Prefetching can be seen in the properties of the Nested Loops operator. However, the prefetching behavior only actually kicks in when the operator detects that actual physical I/O is required. When the data is already in the buffer pool, the prefetch properties are effectively ignored. In order to detect whether physical I/O is required, the Nested Loops operator has to look in the buffer pool for the page that its inner input would need to return its row. This results in extra logical reads that can be seen in the SET STATISTICS IO output, but are not reported in the Actual I/O Statistics property of any operator in the execution plan. It can also result in lower than expected value for the Actual I/O Statistics property, because if the data is found in the buffer pool, Nested Loop will just use it and not call its inner input to fetch the same data again.
For more information on prefetching, see Craig Freedman’s blog post, Paul White’s blog post, and Fabiano Amorim’s article.
Operator properties
The properties below are specific to the Nested Loops operator, or have a specific meaning when appearing on it. For all other properties, see Common properties. Properties that are included on the Common properties page but are also included below for their specific meaning for the Nested Loops operator are marked with a *.
| Property name | Description |
|---|---|
| Logical Operation * | The requested logical join type. Possible values are Inner Join, Left Outer Join, Left Semi Join, and Left Anti Semi Join. |
| Memory Fractions | Only used when Optimized is true. For any operator with a special memory requirement, this set of properties shows the fraction of the total available memory the operator can use, based on the optimizers understanding of which other operators are using memory at the same time.
|
| Optimized | When this property is true, use the optimized Nested Loops algorithm instead of the “normal” algorithm. See above for an explanation of the differences. |
| Outer References | Specifies a dynamic inner input. For each column listed here, the value this column has in the outer input will be pushed into the outer input whenever it (re)starts. |
| Output List * | If the Pass Through property is present, the Output List property may include a column named Passnnnn (where nnnn is a 4-digit number that is unique within the execution plan). This is a bit column that is set to 1 if the condition in the Pass Through property was met, and set to 0 otherwise. This Passnnnn column will also be in the Defined Values property (without definition). |
| Pass Through | When this property is present, it specifies a condition that is evaluated once for each row from the outer input. If the condition is met, the inner branch is not executed at all; the outer row is passed unchanged with NULL values for columns from the inner row. This property has thus far been observed for the Inner Join, Left Outer Join, and Left Semi Join operations. |
| Predicate | Specifies the logical condition that has to be met for a combination of rows from the outer and inner input to be considered a match. |
| Probe Column | Can be used with the Left Semi Join logical operation to change its behavior to that of a “probed’ Left Semi Join. This property lists the name of the generated column that will hold the probe result. This column will also be in the Defined Values property (without definition) and in the Output List property. |
| With Ordered Prefetch | This property is present (and set to true) when prefetching is requested, but the order of rows from the outer input has to be preserved. When neither this property nor With Unordered Prefetch is present, no prefetching is used. |
| With Unordered Prefetch | This property is present (and set to true) when prefetching is requested and order doesn’t need to be preserved. In this case the operator will start with the values for which the IOs completed first. When neither this property nor With Ordered Prefetch is present, no prefetching is used. |
Implicit properties
This table below lists the behavior of the implicit properties for the Nested Loops operator.
| Property name | Description |
|---|---|
| Batch Mode enabled | The Nested Loops operator supports row mode execution only. |
| Blocking | A normal Nested Loops is not blocking. An optimized Nested Loops is semi-blocking, as described above. |
| Memory requirement | A normal Nested Loops does not have any special memory requirement. An optimized Nested Loops requests a memory grant based on the estimated size of the outer input. Insufficient memory will not result in a spill but in reduced sorting efficiency, as described above. |
| Order-preserving | A normal Nested Loops is order-preserving for the outer input, but not for the inner input. An optimized Nested Loops and any Nested Loops with unordered prefetch is not order-preserving, nor guaranteed to impose an order. |
| Parallelism aware | The Nested Loops operator is not parallelism aware. |
| Segment aware | The Nested Loops operator is not segment aware. |
Change log
(Does not include minor changes, such as adding, removing, or changing hyperlinks, correcting typos, and rephrasing for clarity).
May 31, 2018: Added.
January 14, 2019: Added links to blog posts by Bert Wagner with animated visualization of the algorithms.
June 20, 2020: Added extra details to the description of the prefetching process.
November 25, 2020: Added description of special column Passnnnn in the Output List property.
June 2, 2023: Minor update to the flowchart, to better reflect the processing of the inner loop.