Table Spool
Introduction
The Table Spool operator is one of the four spool operators that SQL Server supports. It retains a copy of all data it reads in a worktable (in tempdb) and can then later return extra copies of these rows without having to call its child operators to produce them again. These copies can be made available in the same part of the execution plans, or in another part.
Table Spool is probably the most basic of the spool operators. The Index Spool operator is very similar to it, but indexes its data to allow it to return only a subset of the stored rows. The Row Count Spool operator is optimized for specific cases where the rows to be returned are empty. And the Window Spool operator is used to support the ROWS and RANGE specifications of windowing functions.
Typical use cases of a Table Spool are: to reproduce the same input multiple times without having to re-execute its child nodes (e.g. in the inner input of a Nested Loops); to make the same input available in multiple branches of an execution plan (e.g. in wide update plans); or to ensure that an original copy of the data is available after an insert, update, or delete operator changes the base data (“Halloween protection”).
Execution modes
A Table Spool operator can function in three different execution modes, as determined by the properties Logical Operation and Primary Node ID. The options are as follows:
- Eager builder: Logical Operation is Eager Spool and Primary Node ID is absent.
On the first execution, an eager builder first reads and stores the entire input when the first row is requested, then returns the first row only; it then returns the remainder of the rows from the worktable as more rows are requested. Subsequent executions read and return all rows from the worktable, unless a rebind is issued. - Lazy builder: Logical Operation is Lazy Spool and Primary Node ID is absent.
On the first execution, a lazy builder reads, stores, and immediately returns a single row; it repeats this as more rows are requested. Later executions read and return all rows from the worktable, unless a rebind is issued. - Consumer: Primary Node ID is present.
A consumer does not build its own worktable but reads and returns rows from a worktable that is built by either another Table Spool or Index Spool operator, indicated by the Primary Node ID. In this case only, the Table Spool operator does not have a child operator. The Logical Operation can be marked as either Eager Spool or Lazy Spool without affecting the execution mode (as far as known the Logical Operation of the consumer Table Spool is always the same as that of the Table Spool or Index Spool referenced by the Primary Node ID).
(Note that the terms “builder” and “consumer” are not official Microsoft terms; I have introduced these terms to be able to quickly describe the different behaviors).
Visual appearance in execution plans
Depending on the tool being used, a Table Spool operator is displayed in a graphical execution plan as shown below:
|
SSMS and VS Code |
Legacy SSMS |
Plan Explorer |
Paste The Plan |
Algorithm
The basic algorithm for the Table Spool operator consists of two phases.
The first phase is the initialization, which runs not only when the operator is first called, but every time the execution is restarted (using either a rebind or a rewind). Though it might make sense to expect this logic to execute on the Intialize() call, this is not actually the case. There are strong indicators that suggest that the entire initialization logic is handled on the first GetNext() call after an Initialize() call. All subsequent GetNext() calls skip this.
The second phase is the actual logic. This second phase is executed each time GetNext() is called. The first GetNext() call after each Initialize() call executes the actual logic after the initialization phase; all subsequent GetNext() calls (until the next Initialize() call) does only the actual logic.
Initialization
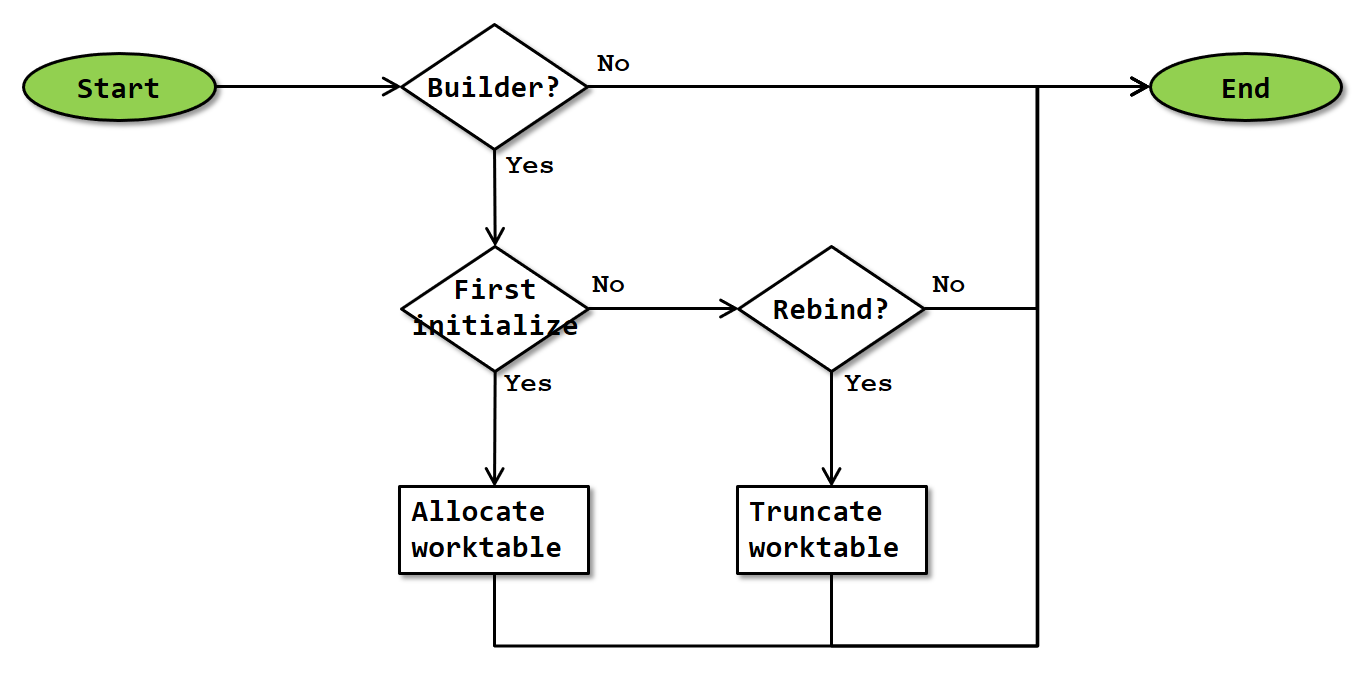 The Initialization phase is used to allocate and optionally reset the worktable when execution of the Table Spool starts or restarts. Because a Table Spool in consumer mode does not have its own worktable, it does nothing during the initialization phase.
The Initialization phase is used to allocate and optionally reset the worktable when execution of the Table Spool starts or restarts. Because a Table Spool in consumer mode does not have its own worktable, it does nothing during the initialization phase.
A Table Spool in builder mode distinguishes between being initialized for a rebind or a rewind (see Nested Loops). Whether rebind or rewind is needed is known when Initialize() is called and then stored in operator memory to be used in the initialization phase
Allocate worktable
The first initialization of a Table Spool is a rebind by definition. At this time no worktable has been allocated yet, so that is now done.
The column structure of the worktable is defined by the Defined Values property of the operator; if a column comes directly from a table or index it uses the same data type; if a column is computed in the execution plan it uses the data type inferred by applying the data type precedence rules to the expression used to compute it.
The worktable is structured as if it was defined with a clustered index on zero columns. This means that a 4-byte uniqueifier is added to each row stored except the first. This uniqueifier allows SQL Server to later read the rows in the same order in which they were inserted.
Truncate worktable
Each second and later initialization of a Table Spool can be either a rewind or a rebind. In the case of a rewind, nothing is done. The data already stored in the worktable is not changed. This implements the Table Spool functionality of repeating the same values multiple times.
In the case of a rebind, the old set of rows is no longer needed and a new set will be loaded. The structure of the worktable remains the same but the old data has to be removed, which is achieved by removing all rows. Though not explicitly documented, it is likely that this is done using the much faster truncation mechanism rather than using the slower delete mechanism.
Actual logic
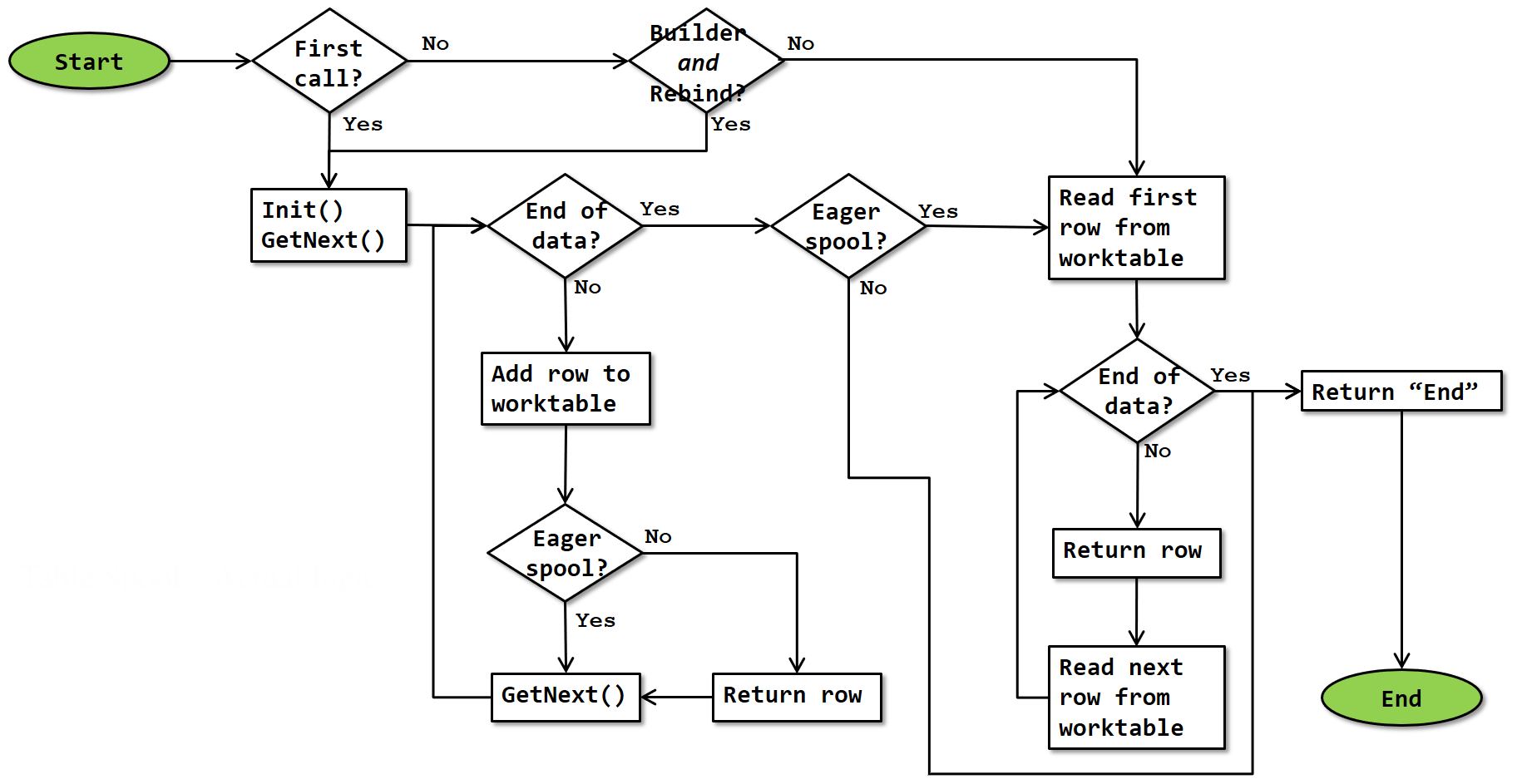 Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called. It also does not show that the operator’s input is closed when the operator itself is closed, or that the first GetNext() call after each Initialize() call first performs the initialization actions (described above) before starting this flowchart.
Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called. It also does not show that the operator’s input is closed when the operator itself is closed, or that the first GetNext() call after each Initialize() call first performs the initialization actions (described above) before starting this flowchart.
Eager builder
For an eager builder, the first call and each subsequent rebind starts with an empty table due to the initialization actions. The operator’s input is initialized and then all its rows are read and stored in the worktable without returning control to the calling operator. Once the input is depleted, the first row from the worktable is read and returned, and later calls continue to read and return the rest of the rows in the worktable.
Every rewind skips past the logic to read from the child node and store the data in a worktable, and instead immediately reads and returns the first row from the worktable that was made earlier, then after being called again continues with the rest of that worktable.
Lazy builder
For a lazy builder, the first call and each subsequent rebind starts with an empty table due to the initialization actions. The operator’s input is initialized and its first rows is read, stored in the worktable, and returned. When called again, the next row is similarly read, stored, and returned. When the input is depleted, Table Spool returns an end of data signal.
Every rewind reads and returns the first row from the worktable that was made on the last rebind, then after being called again continues with the rest of that worktable.
Consumer
For a consumer, each execution, regardless of whether it is a rebind or a rewind, is handled the same. It reads and returns the first row from the worktable that is made and maintained by the spool operator referenced in this operator’s Primary Node ID property. After being called again it continues with the rest of that worktable.
The worktable used by a consumer Table Spool is normally created by another Table Spool operator. There is one exception to this: a Table Spool that has the With Stack property set to True typically reads rows from a worktable that is created by an Index Spool.. This is described in more detail below.
Special cases
The algorithm as described above does not include three special cases. These are described below.
Segmented input
The Table Spool operator is segment aware. If the input includes a segment column, the behavior of the operator changes to store only the current segment in the worktable, and return only a single row for that segment. In other words:
- After reading a row and storing it in the worktable, it immediately reads the next row. If the segment column does not indicate a new segment, it stores this row in the worktable and repeats this step. If the segment column does indicate a segment change, then that row is temporarily put aside in operator memory and the operator returns one of the rows from the worktable (it is not known which row) to its parent.
- When the parent operator then calls the Table Spool again, it clears out the worktable, stores the row that was set aside in operator memory in the worktable, then continues to read and store rows as described above.
- When the child row signals end of data, the Table Spool operator returns one of the rows from the worktable (it is not known which row) to its parent.
A Table Spool that processes segmented input is always displayed with “Lazy Spool” as the logical operation. The actual behavior can be described as halfway in between eager and lazy, because it does not eagerly store all input but also does not pass each row immediately as it is being read. It stores an entire segment and then returns a single row to represent this segment. Often this is then combined with a Nested Loops operator that uses a consumer Table Spool to re-read the individual rows from that segment.
Top parent operator
If a Table Spool is called by a Top operator, it passes a count of the number of rows stored to that Top operator. This information exchange is not in any way visible in the execution plan itself.
This is typically used for a Top operator that has its Is Percent property set to True. The Table Spool will be an eager builder in this case. After storing all the data from its input, it passes the number of rows to the Top operator, so that the requested number of rows can be computed from the rowcount and the Top Expression property of Top.
Stack spool
A stack spool is a special type of spool. In execution plans, a stack spool is represented as an Index Spool in lazy builder mode and a Table Spool in consumer mode, both with the With Stack property set to True.
The behavior of the Index Spool in this combination is described on the Index Spool page. For an understanding of the Table Spool part of this combination, it suffices to know that the Index Spool in this case adds rows to a worktable that is indexed in such a way that the last added row is always located at the last position in the worktable.
The Table Spool part of a stack spool has the same basic function as any consumer Table Spool, with two exceptions. The first is that the Table Spool remembers which row it has read last; when called to return a new row it will now first delete the row it had read on the previous call before reading and returning a row. This is, as far as I know, the only case where a Table Spool in consumer mode can actually modify the worktable it reads from.
The second difference is that the Table Spool part of a stack spool does not read rows in the order in which they were added. Instead it will always read and return the most recently added row from the worktable. This is done after deleting the row returned by the previous GetNext() call.
Note that execution plans that use stack spools typically are built to interweave GetNext() calls to the two spool operators. As such, it is for instance possible that first rows 1 to 4 are stored, then row 4 is read, rows 5 and 6 are then added, then row 4 is deleted and row 6 is read, and after that row 6 is removed and row 5 is read. And so on.
Operator properties
The properties below are specific to the Table Spool operator, or have a specific meaning when appearing on it. For all other properties, see Common properties. Properties that are included on the Common properties page but are also included below for their specific meaning for the Table Spool operator are marked with a *.
| Property name | Description |
|---|---|
| Actual I/O Statistics * | Since this property only reports reads and not writes, there is no direct way to see how many logical writes were done. However, every write starts with traversing the B-tree index from the top to the last page to find the location to add the row, so every row written to the worktable adds an amount of logical writes equal to the then current number of levels in the clustered index on the worktable. This property always reports zero for all subproperties when the Table Spool is a consumer. In this case, the logical reads that were incurred from executing the operator are actually included in the Actual I/O Statistics of the related builder (as indicated by the Primary Node ID property). |
| Logical Operation * | Can be Eager Spool or Lazy Spool, as described above. |
| Output List * | Because this property specifies the list of columns to be returned, it is also used to define the columns to be stored in the worktable. |
| Primary Node ID | For consumer mode only, this property references the Node ID property of a Table Spool or Index Spool operator. The Table Spool will return rows stored in the worktable of that referenced spool operator. |
| With Stack | This property is present (and set to true) when the Table Spool acts as the consumer part of a stack spool. This is described in more detail in the main text. |
Implicit properties
This table below lists the behavior of the implicit properties for the Table Spool operator.
| Property name | Description |
|---|---|
| Batch Mode enabled | The Table Spool operator supports row mode execution only. |
| Blocking | The Table Spool operator is fully blocking when it executes as an eager producer; in other execution modes it is non-blocking. |
| Memory requirement | The Table Spool operator does not have any special memory requirement. |
| Order-preserving | A “normal” Table Spool operator is fully order-preserving within a single execution. The Table Spool part of a stack spool is not order-preserving; it always starts with the last-added row, basically inversing the order in which rows were added. |
| Parallelism aware | The Table Spool operator does not support parallelism. It can only be used in a serial plan, or in a serial section of a parallel plan. |
| Segment aware | The Table Spool operator is segment aware. This is described in more detail in the main text. |
Change log
(Does not include minor changes, such as adding, removing, or changing hyperlinks, correcting typos, and rephrasing for clarity).
November 7, 2018: Added.
November 15, 2018: Small correction to the flowchart in the “Actual Logic” section.
November 18, 2018: Correction to the “Order-preserving” property.
November 18, 2020: Corrected wrong information about behavior of this operator in parallel execution plans.
November 10, 2023: Added additional explanation about idiosyncrasies of its Actual I/O Statistics property.