Index Spool
Introduction
The Index Spool operator is one of the four spool operators that SQL Server supports. It retains a copy of all data it reads in an indexed worktable (in tempdb), and can then later return subsets of these rows without having to call its child operators to produce them again.
The Index Spool operator is quite similar to Table Spool, except that Index Spool indexes its data, giving it the option to return a subset, and Index Spool lacks the option to read data from a spool created by another operator. The other two spool operators are quite different: Row Count Spool is optimized for specific cases where the rows to be returned are empty, and Window Spool is used to support the ROWS and RANGE specifications of windowing functions.
An Index Spool is sometimes called a “Nonclustered Index Spool”. This is a confusing and misleading terminology, because the storage structure imposed on the worktable is actually that of a clustered index.
A typical use case of an Index Spool is to gain performance when doing multiple passes over a table with a predicate that is not supported by an existing index. A very specific use case of Index Spool, combined with a Table Spool operator, is the “stack spool” used for recursive processing.
Execution modes
An Index Spool operator can function in two different execution modes, as determined by the Logical Operation property:
- Eager Spool:
On the first execution, an eager spool first reads and stores the entire input when the first row is requested, then returns only the first row that matches the Predicate property; it then returns the remainder of the matching rows from the indexed worktable as more rows are requested. Subsequent executions read and return the same or a different subset of rows from the worktable, without ever having to execute the child nodes again. - Lazy Spool:
On the first execution, a lazy spool reads, stores, and immediately returns a single row; it repeats this as more rows are requested. The rows read during this execution will always match the Predicate Subsequent executions read and return the requested subset of rows from the worktable if they exist; otherwise they read, store, and return additional rows by calling their child operator.
An Index Spool does not have the ability to operate as a “consumer” (see Table Spool for more details). However, it is possible for a consumer Table Spool to read data from an Index Spool – so far I have only seen this in the case of a stack spool.
Visual appearance in execution plans
Depending on the tool being used, an Index Spool operator is displayed in a graphical execution plan as shown below:
|
SSMS and VS Code |
Legacy SSMS |
Plan Explorer |
Paste The Plan |
Algorithm
The basic algorithm for the Index Spool operator is as shown below:
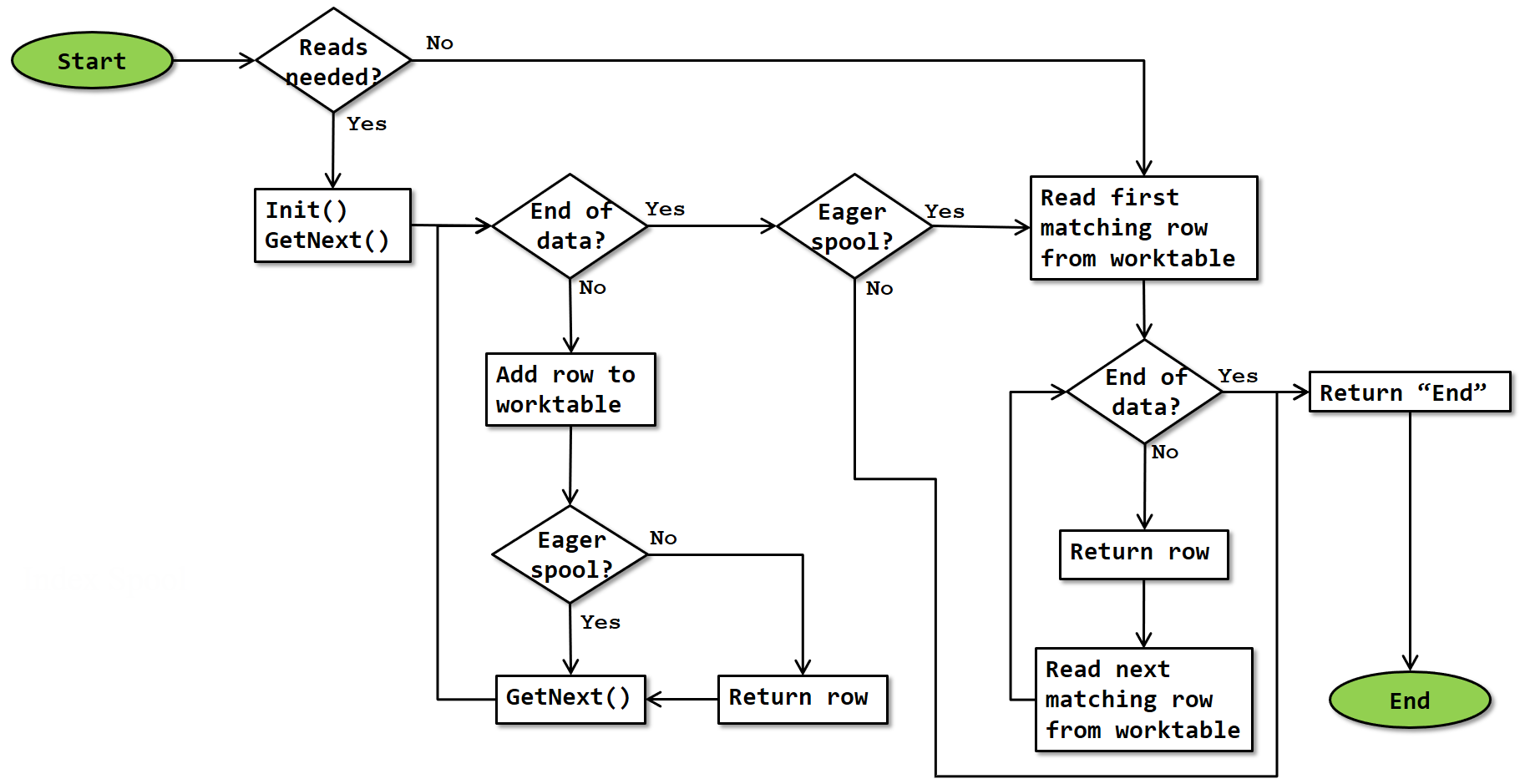 Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called. It also does not show that the operator’s input is closed when the operator itself is closed.
Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called. It also does not show that the operator’s input is closed when the operator itself is closed.
Reads needed?
For the first execution of an Index Spool, reads are always needed. For an eager Index Spool, reads are not needed for any later executions. However, for a lazy Index Spool that may be executed more than once, the situation is complex. Unlike the regular Table Spool, Index Spool does not properly mark rebinds and rewinds and can hence not use this distinction to determine whether it would be required to execute its input (and even if it did, it would still be possible to receive a rewind using a value in the Seek Predicate property has been seen before, in which case the input should not be executed again).
I have so far not seen any occurrences of a lazy Index Spool on the inner input of a Nested Loops operator (which is the only situation where the operator would execute more than once). Perhaps the operator does not even support a lazy spool operation in that case, in which case there is never a need to determine whether or not to execute its input.
If it is supported, then I assume that it uses some way to determine whether or not the value in the Seek Predicate property has been seen before. One such way would be to simply check for matching data in the worktable, though this would introduce the risk of false negatives (if a value produces no rows, then passing in this value multiple times would result in redundant executions of the input). Another way would be to keep track of all values passed in, though it is unclear where this information would be stored.
If you ever see an execution plan that uses the Index Spool operator with a Lazy Spool operation on the inner side of a Nested Loops, then please let me know so I can research this further.
Add row to worktable
An Index Spool stores its data in a worktable. This worktable is structured as a clustered index on all of the columns that are mentioned in the Seek Predicate property.
Read first / next matching row from worktable
For reading the first matching row from the worktable, the clustered index is navigated, using the same method as a Clustered Index Seek, to find the first row in the worktable for which the Seek Predicate property. If no matching row is found, then it is considered “end of data”.
For reading the next matching row from the worktable, the next row (in the logical order imposed by the clustered index) from the worktable is read, and then the Seek Predicate property is evaluated. If it is true the row is returned; if it is false no row is returned (“end of data”).
Stack spool
A stack spool is a special type of spool. In execution plans, a stack spool is represented as an Index Spool in lazy spool mode and a Table Spool in consumer mode, both with the With Stack property set to True.
The behavior of the Table Spool in this combination is described on the Table Spool page. For an understanding of the Index Spool part of this combination, it suffices to know that the Table Spool not only reads data from the worktable, but also removes the rows it has read.
The Index Spool part of a stack spool always executes once, as a lazy spool. This means that it never reads its own worktable, it only stores rows there for the Table Spool part to read.
Because the Index Spool part of a stack spool does not read its own worktable, it does not need a Seek Predicate property. That implies that this property cannot be used to determine the index columns for the worktable. Instead, the worktable of a stack spool is always structured as a clustered index on a single column that represents the recursion level. This column is computed by other operators within the execution plan, and will be the first column in the Output List property.
Parallelism
Most spool operators do not support parallelism. When multiple threads all write to the same worktable at the same time, the risk of contention is too high. (In theory, the operators could be built to use separate worktables per thread, as long as the optimizer ensures correct thread affinity for all data in all sections of the execution plan where the spool is used. But as far as I know this is not currently the case).
Index Spool is a “sort of” exception to this rule. When the Logical Operation is Eager Spool, Index Spool can be used in a parallel section of an execution plan. But it does not truly run in parallel. Its child operators will be marked as parallel, but they are only executed on a single thread. Index Spool requests and stores rows on the first thread that activates it. On all other threads, the operator simply waits until that first thread is done. Once the spool is built, the Index Spool can further execute in parallel, returning data from its worktable on all threads.
For an Index Spool with Logical Operation equal to Lazy Spool, parallelism is as far as I know not supported at all.
Operator properties
The properties below are specific to the Index Spool operator, or have a specific meaning when appearing on it. For all other properties, see Common properties. Properties that are included on the Common properties page but are also included below for their specific meaning for the Index Spool operator are marked with a *.
| Property name | Description |
|---|---|
| Logical Operation * | Can be Eager Spool or Lazy Spool, as described above. |
| Output List * | Because this property specifies the list of columns to be returned, it is also used to define the columns to be stored in the worktable. |
| Seek Predicate | When reading rows from the worktable, this property determines which of the rows stored in it are returned. The worktable columns that are mentioned in this property are used as the key columns for the clustered index on the worktable. |
| With Stack | This property is present (and set to true) when the Index Spool acts as the builder part of a stack spool. This is described in more detail in the main text. |
Implicit properties
This table below lists the behavior of the implicit properties for the Index Spool operator.
| Property name | Description |
|---|---|
| Batch Mode enabled | The Index Spool operator supports row mode execution only. |
| Blocking | The Index Spool operator is fully blocking when it executes as an eager spool. The Index Spool operator is non-blocking when it executes as a lazy spool. |
| Memory requirement | The Index Spool operator does not have any special memory requirement. |
| Order-preserving | A “normal” Index Spool operator is fully order-preserving within a single execution. The Index Spool part of a stack spool is fully order-preserving. |
| Parallelism aware | The Index Spool operator is parallelism aware when running an Eager Spool operation. The details of this are described above. As far as I know, the Index Spool operator does not support parallelism for a Lazy Spool operation; this version can only be used in a serial plan, or in a serial section of a parallel plan. |
| Segment aware | The Index Spool operator is not segment aware. |
Change log
(Does not include minor changes, such as adding, removing, or changing hyperlinks, correcting typos, and rephrasing for clarity).
November 18, 2018: Added.
January 31, 2019: Added a description of the “limited parallelism awareness” of this operator, and made two minor single-word changes. Thanks to Erik Darling for sharing the execution plan that made me discover this!
November 18, 2020: Corrected wrong information about behavior of this operator in parallel execution plans.