Hash Match
Introduction
The Hash Match operator implements several different logical operations that all use an in-memory hash table for finding matching data. The various operations can be roughly divided into two separate groups: joins (reading data from two sources to produce a single combined stream), and aggregation (reading data from a single source to produce a new stream with aggregated or deduplicated data).
Because of this versatility, Hash Match can have either a single input or two inputs. The first input, represented at the top in a graphical execution plan, is called the build input. The optional second input is called the probe input.
When used with two inputs, Hash Match implements nine of the ten logical join operations: inner join; left, right, and full outer join; left and right semi and anti semi join; as well as union. The Union logical operation does require that the probe input is guaranteed free of duplicates, either because of trusted constraints on the base input data or by use of other operators. The algorithm requires at least one equality-based join predicate. The Hash Match operator is typically favored when the optimizer has to combine two large and unsorted inputs. The alternatives are Nested Loops (best for joining a small data stream with a cheap input), Merge Join (ideal for joining data streams that are sorted by the join key), and Adaptive Join (which can be used when the optimizer finds viable plans for both Nested Loops and Hash Match and wants to postpone the final choice until run time).
When used with a single input, Hash Match implements aggregation, using the logical operations Aggregate and Partial Aggregate. These two logical operations have mostly the same function, but Partial Aggregate uses some unique optimizations that are only possible because it is used in a local-global aggregation pattern. In the rest of this page, I use [Partial] Aggregate to refer to the common behavior, and use the explicit terms Aggregate and Partial Aggregate if I refer to just one of them.
The alternative aggregation operator, Stream Aggregate, is faster and has less overhead; but it requires the input stream to be sorted. When no efficient way to sort the input is available, the optimizer will usually favor the Hash Match operator for aggregation. Similar to Stream Aggregate, Hash Match (Aggregate) can be used without a Defined Values property, to effectively perform a DISTINCT operation. Unlike Stream Aggregate, Hash Match ([Partial] Aggregate) can not be used to compute a scalar aggregate (except in Batch Mode plans on SQL Server 2014 and up).
Hash Match (Flow Distinct) is similar to Hash Match (Aggregate) without Defined Values, so effectively doing a DISTINCT operation (as the name already suggests). It is a bit more expensive than normal Hash Match (Aggregate) but has the benefit of not being blocking. The optimizer will typically only choose Hash Match (Flow Distinct) if a row goal is active.
Visual appearance in execution plans
Depending on the tool being used, a Hash Match operator is displayed in a graphical execution plan as shown below:
|
SSMS and VS Code |
Legacy SSMS |
Plan Explorer |
Paste The Plan |
Algorithm
The basic algorithm for the Hash Match operator consists of three phases. The first two phases are called the build phase and the probe phase; these are officially documented. The third, final phase is not documented, probably because Microsoft considers it part of the probe phase. The build phase is always executed. After that, the requested logical operations determines whether or not each of the probe phase and the final phase needs to execute.
In this post you can see some nice (slightly simplified) animations showing the first two phases of the algorithm in action. Thanks, Bert!
Note that none of the flowcharts below include any of the special logic needed when the hash table tries to grow beyond the available memory. These are all explained in the section on memory usage.
Build phase
The build phase is always the first phase to run. During this phase, the first input (the “build input”) is read, and the data from the build input is stored in an in-memory hash table. No data is returned at this time. It is currently unknown whether the Build Phase processes as part of the Init() processing of the Hash Match component, or as part of first GetNext() call.
Depending on the logical operation Hash Match performs, it either uses the normal version of the build phase, or one of the two special variations.
Normal build phase
The normal algorithm for the build phase is as shown below:
 The algorithm itself is simple enough. It simply reads rows, computes a hash value from the columns in the Hash Keys Build property, and stores them, unchanged, in the specified bucket in the in-memory hash table. The complexity is in details that are not visible in this flowchart: the exact hash functions used to compute a bucket number from the input, the layout of the hash table where rows are stored, and how memory spills are handled. Some of these complexities are discussed lower on this page or in future articles.
The algorithm itself is simple enough. It simply reads rows, computes a hash value from the columns in the Hash Keys Build property, and stores them, unchanged, in the specified bucket in the in-memory hash table. The complexity is in details that are not visible in this flowchart: the exact hash functions used to compute a bucket number from the input, the layout of the hash table where rows are stored, and how memory spills are handled. Some of these complexities are discussed lower on this page or in future articles.
Note that the rows are marked as unread as they are read from the build input. This marker is stored along with the row in the hash table. As the other phases execute, these markers can be updated or used to check whether a row has already had any matches.
Aggregated build phase
When Hash Match performs the logical operations [Partial] Aggregate or Union, the build phase changes slightly, as below:
 The key difference with the normal build phase is that the input is not stored as is. Instead, the data stored in the hash table is a combination of the columns used for grouping (as listed in the Hash Keys Build property, and optionally in the Build Residual property; or all input columns for Union), plus “counters” for the requested aggregations (as specified in the Defined Values property for [Partial] Aggregate]). After determining the bucket where the data needs to be stored, the bucket is first scanned to find matching data. Ideally there should always be just a single row in each bucket but due to hash collisions this ideal is not always achieved. Searching the bucket is required to ensure only an actually matching row is considered as a match.
The key difference with the normal build phase is that the input is not stored as is. Instead, the data stored in the hash table is a combination of the columns used for grouping (as listed in the Hash Keys Build property, and optionally in the Build Residual property; or all input columns for Union), plus “counters” for the requested aggregations (as specified in the Defined Values property for [Partial] Aggregate]). After determining the bucket where the data needs to be stored, the bucket is first scanned to find matching data. Ideally there should always be just a single row in each bucket but due to hash collisions this ideal is not always achieved. Searching the bucket is required to ensure only an actually matching row is considered as a match.
Because this phase always runs first, and because it returns no data, it can either be processed as part of the Initialize() call, or prior to getting the first row on the first GetNext() call. For the Aggregate and Union operations, either method is possible and it’s impossible to tell which is actually used. For a Partial Aggregate, though, this phase can already return rows, and therefore has to be executed as part of the first GetNext() call. That makes it reasonable to assume that this phase executes on the first GetNext() call in all cases.
Flow Distinct build phase
Finally, for the logical operation Flow Distinct yet another (third) version of the build phase is used:
 This version is somewhat similar to the aggregated build phase. However, rather than just storing and updating counters for each group, it immediately returns the columns and uses the stored copy in the hash table to ensure that future rows with the same values are not returned. So unlike the normal and aggregated build phase, the Flow Distinct build phase actually returns rows (which as always means that control is passed and execution halted until the next call). This implies that at least this version of the build phase is executed as part of a GetNext() call, not as part of the Init() call.
This version is somewhat similar to the aggregated build phase. However, rather than just storing and updating counters for each group, it immediately returns the columns and uses the stored copy in the hash table to ensure that future rows with the same values are not returned. So unlike the normal and aggregated build phase, the Flow Distinct build phase actually returns rows (which as always means that control is passed and execution halted until the next call). This implies that at least this version of the build phase is executed as part of a GetNext() call, not as part of the Init() call.
Probe phase
The probe phase occurs after the build phase. In this phase the operator reads data from its second input, the probe input. Logical operations that have only a single input ([Partial] Aggregate and Flow Distinct) skip the probe phase. Here is the flowchart:
 This flowchart is similar to the flowchart for the build phase in that this phase, too, computes a bucket number by executing a hash function on the appropriate columns (but now from the probe input and as specified by the Hash Keys Probe property). After that it changes.
This flowchart is similar to the flowchart for the build phase in that this phase, too, computes a bucket number by executing a hash function on the appropriate columns (but now from the probe input and as specified by the Hash Keys Probe property). After that it changes.
As with the aggregated version of the build phase, the bucket is scanned for rows that actually match. Ideally the bucket should only contain rows that have matching key values, but due to hash collisions this ideal is not always achieved. Searching the bucket is required to ensure only actually matching rows are considered as matches. All operators that have a probe input use the normal version of the build phase, that stores the entire input. This implies that there may be multiple rows with the same key values in the hash table, which is why after finding a match the rest of the bucket is searched as well. (For the logical operations Right Semi Join, Right Anti Semi Join, and Union, extra matching rows are irrelevant; it is likely that the algorithm does not repeat the bucket search for these operations).
When a match is found, both rows are marked as matched. For the build row this means that the corresponding marker is updated in the hash table. The marker for the probe row is just a normal variable that is reset when a row is read, set when a match is found, and tested after the bucket search has been completed.
Final phase
Some logical operations require some additional activity after both the build and probe inputs are fully consumed. These operations are Left Outer Join, Full Outer Join, Left Semi Join, Left Anti Semi Join, Union, [Partial] Aggregate, and Union.
The algorithm for this final phase is as shown below:
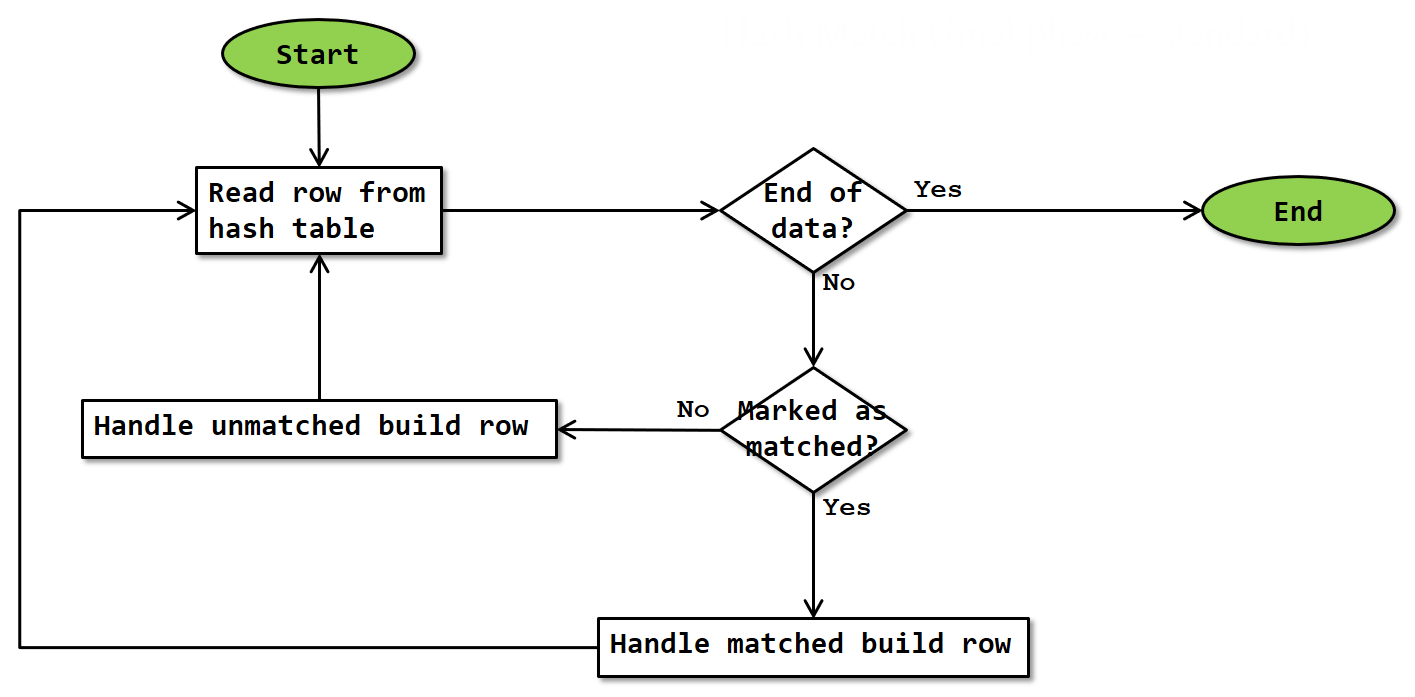
The final phase simply iterates over all the rows in the hash table. Because the final phase only runs for operations that also use the normal build phase, this corresponds to all rows from the build input, or all distinct rows from the build input for Union. They were marked as unmatched when they were added in the build phase, and during the probe phase some of them were then marked as matched. This mark now decides whether these rows will be handled as a matched row or as an unmatched row from the build input.
Logical operations
The Hash Match operator always uses the algorithms described above, regardless of the requested logical operation. Some of the steps behave differently for each logical operation. How each logical operation is performed is described below. (Note that for the build and final phases, the normal version will be used unless explicitly stated otherwise).
Inner Join
For an inner join, Hash Match uses the build phase and the probe phase.
Within the probe phase, “Handle matching rows” returns the combined data to the calling operator. “Handle unmatched probe row” does nothing. The matched marker in the hash table is not used. Based on observed memory usage, I assume that Microsoft actually avoids storing the marker in this case.
Left Outer Join
For a left outer join, all phases are needed: the build phase, the probe phase, and the final phase.
Within the probe phase, “Handle matching rows” returns the combined data to the calling operator. “Handle unmatched probe row” does nothing; its associated logic has no effect and may or may not be skipped during processing.
In the final phase, “Handle unmatched build row” returns a row (the row from the build input, with null vales for the columns from the probe input). “Handle matched build row” does nothing.
Right Outer Join
The right outer join operation uses the build phase and the probe phase.
Within the probe phase, “Handle matching rows” returns the combined data to the calling operator. “Handle unmatched probe row” now also returns data, from the probe input and with null values for the columns from the build input. The matched marker in the hash table is not used. Based on observed memory usage, I assume that Microsoft actually avoids storing the marker in this case.
Full Outer Join
A full outer join requires all three phases: the build phase, the probe phase, and the final phase.
Within the probe phase, both “Handle matching rows” and “Handle unmatched probe row” return data to the calling operator. In the latter case, null values are supplied for columns from the build input.
In the final phase, “Handle unmatched build row” returns the row from the build input, with null vales for the columns from the probe input; “Handle matched build row” does nothing.
Left Semi Join
For the left semi join operation, all three phases are executed.
During the probe phase, neither “Handle matching rows” nor “Handle unmatched probe row” return any data. All rows from the probe phase are read, matching rows in the hash table are marked, but no data is returned.
In the final phase, “Handle matched build row” returns the row from the build input; “Handle matched build row” does nothing.
Left Semi Join (probed)
As far as currently known, Hash Match does not support a probed version of the left semi join operation.
Left Anti Semi Join
The left anti semi join operation runs almost exactly the same as the left semi join: it executes all three phases, does not return any data during the probe phase, and uses the final phase to return rows. In this case, it is obviously “Handle unmatched build row” that returns a row and “Handle matched build row” that doesn’t.
Right Semi Join
For a right semi join operation, only the build phase and the probe phase are needed.
Within the probe phase, “Handle matching rows” returns the probe row. After that it immediately continues to “Probe: GetNext()”, without looking for and processing additional matching rows in the hash table (shown as a dotted line in the flowchart). “Handle unmatched probe row” does nothing in this case. The matched marker in the hash table is not used. Based on observed memory usage, I assume that Microsoft actually avoids storing the marker in this case.
Right Anti Semi Join
For a right anti semi join operation, only the build phase and the probe phase are needed.
Within the probe phase, “Handle matching rows” does not return any row, and it immediately continues to “Probe: GetNext()”, without looking for and processing additional matching rows in the hash table (shown as a dotted line in the flowchart). “Handle unmatched probe row” does return a row. The matched marker in the hash table is not used. Based on observed memory usage, I assume that Microsoft actually avoids storing the marker in this case.
Union
The Hash Match (Union) logic is slightly limited. The Union operation, like the UNION SQL keyword is intended to return a distinct set of rows from a combination of two inputs. It has to remove duplicates from the first input, duplicates from the second input, and duplicates that appear due to combining the sets. Hash Match (Union) can do two of those: it can detect and remove duplicates within the build input and rows that are identical in both inputs, but it is unable to detect and remove duplicates in the probe input. If Hash Match (Union) is used in an execution plan, the probe input will either come from data that due to constraints is guaranteed to have no duplication, or the probe input uses other operators to remove duplicates before inputting the data into the Hash Match operator.
The Union operation uses the special aggregated version of the build phase, followed by the probe and final phase.
During the build phase, whenever a row is found that has “new” values in the input columns (“new” meaning that these values not seen before, and no row has been loaded for them in the hash table), “Initialize counters” allocates a new row with those values. There are no aggregation counters in this case. This row is then added to the hash table. Because there are no aggregation counters in this case, the “Update counters” step effectively does nothing for a Union.
The probe phase returns only rows from the probe input that do not exist in the build input. It works exactly the same as for right anti semi join: “Handle matching rows” does not return any row, and it immediately continues to “Probe: GetNext()”, without looking for and processing additional matching rows in the hash table (shown as a dotted line in the flowchart). “Handle unmatched probe row” does return a row.
After the probe phase, the final phase runs. This phase returns all rows that are stored in the hash table, regardless of whether or not there was a matching row in the probe input. Note that duplicates from the build input, if any, were already removed during the build phase.
The matched markers in the hash table are not used for Union. Based on observed memory usage, I assume that Microsoft actually avoids storing the marker in this case.
[Partial] Aggregate
The [partial] aggregate operations do not have a probe input, so they do not use the probe phase. They do use the special aggregated version of the build phase, followed by the final phase.
During the build phase, whenever a row is found that has “new” values in the grouping columns (“new” meaning that these values not seen before, and no row has been loaded for them in the hash table), “Initialize counters” allocates a new row. The values for the grouping columns are set to the corresponding values in the current row from the build input. The aggregation counters are set to the correct initial value for the aggregate functions requested. This row is then added to the hash table.
In “Update counters”, the aggregation counters in the matching entry in the hash table (which was either just added, or existed before and may have been updated multiple times already) are updated as needed for the aggregate function requested.
It is important to point out that, in order to comply with ANSI standards for aggregation, grouping, and DISTINCT, the “Match found?” test in the aggregated build phase considers null values to be equal to each other.
The final phase goes over the hash table and returns each row from “Handle unmatched build row”. The row returned is not actually a copy of a row from the build input, it is a new row, generated in the build phase from the values in the grouping columns and the aggregation counters. Since there is no probe phase, the rows in the bucket will never be marked as matched, so “Handle matched build row” cannot even execute in this case. Based on observed memory usage, I assume that Microsoft actually avoids storing the marker in this case.
Aggregation details
As far as known, Hash Match ([Partial] Aggregate) supports the same list of aggregation functions as the Stream Aggregate operator. The logic used to compute the aggregation results, by choosing an appropriate initial value and then updating it with every match, is also the same. The only difference is that Stream Aggregate computes and returns one value of the grouping columns at a time, with the aggregation counters in simple variables. Hash Match ([Partial] Aggregate) on the other hand does the same computation for each value in the grouping columns at the same time, storing the intermediate values of the aggregation counters in the hash table.
See Aggregate Functions for a full list of supported aggregate functions, and how the counters are initialized and updated for each of them.
Flow Distinct
The Flow Distinct operator uses only one phase, the build phase – not the normal version but the special version for Flow Distinct.
As it reads rows from the build input, it constantly checks to see if a row with the same values is already stored in the hash table. If it is, the row is a duplicate of row processed and returned earlier and is discarded. If it is not, then the row is returned and stored in the hash table, to ensure that future rows with the same value can be detected as duplicates and rejected.
Special considerations
Batch mode
Hash Match is one of the operators that can run in batch mode. This means that (a) a GetNext() call to Hash Match returns not a single row but a batch of rows (usually between 500 and 1000), (b) Hash Match is able to receive batches of rows from its child operators (if the child operator supports it), and (c) a special version of the code, optimized for batch processing, is used. (Batch mode will be described in detail at a later time).
In SQL Server 2012, Hash Match supports batch mode only for two logical operations: Inner Join and [Partial] Aggregate. More logical operators were added in later versions. Most logical operators are known to be supported in SQL Server 2017, though batch mode has not yet been confirmed for the Union and Flow Distinct operations.
Scalar aggregate
In batch mode only, Hash Match (Aggregate) can be used without specifying grouping keys in a Hash Keys (Build) property, to produce a scalar aggregate. This option was introduced in SQL Server 2014, to ensure that simple aggregation queries without a GROUP BY clause would be able to run in batch mode. Internals of how exactly this is implemented are unknown at this time.
Aggregate pushdown
Aggregate pushdown is an optimization, introduced in SQL Server 2016, where aggregation of rows in compressed rowgroups of a columnstore index can be done locally in a Columnstore Index Scan operator. This can only happen when that Columnstore Index Scan is the direct child of the Hash Match (Aggregate) operator, and both have to run in batch mode. Several other restrictions apply as well.
The exact process of aggregate pushdown is not described in detail. But what I have found suggests that the Columnstore Index Scan first scans and aggregates all compressed rowgroups, and then sends this to the Hash Match operator, which stores this in the hash table. After this, the Columnstore Index Scan returns the uncompressed data from the delta rowgroups (if any), which are then processed as normal by the Hash Match operator, to get the correct final result of all data in the columnstore index.
There is also a feedback mechanism that can cause aggregate pushdown to be turned off after processing part of the data, in cases when it turns out not to be effective enough. See here for more details.
Apart from the presence of the Actual Number of Rows Aggregated Locally property on the Columnstore Index Scan operator in the execution plan plus run-time statistics, there is nothing in the execution plan to show that aggregate pushdown is being used. I assume that this information must be available in the internal execution plan, because the Hash Match operator must know that it will first receive pre-aggregated results, instead of only individual rows. But apparently, that information is not exported to the XML representation of the execution plan.
Blocking
The Hash Match operator is usually described as “semi-blocking”. However this is not always correct; the blocking or non-blocking behavior of Hash Match is actually different depending on the logical operation. Spilling can also affect the blocking level, as described below.
Semi-blocking
For most operations, Hash Match is indeed semi-blocking. During the build phase, rows are read from the build input but no output is produced; this is the blocking part. After that, during the probe phase, the operator switches to streaming behavior as it reads rows from the probe input and immediately returns data. For some logical operations, the final phase returns some extra rows that can only be returned after processing the entire probe input.
The full list logical operations where this semi-blocking behavior applies is: Inner Join, Left Outer Join, Right Outer Join, Full Outer Join, Right Semi Join, Right Anti Semi Join, and Union. Union is actually even more blocking than the other logical operations, since only non-matching rows from the probe input are returned immediately; data that is in both inputs is not returned until the final phase, when the entire probe input has already been processed.
Non-blocking
The Flow Distinct operation, as the name suggests, is fully streaming (aka “flowing”). This is obvious from the implementation: unlike any of the other logical operations, Flow Distinct actually returns rows during the build phase, and returns them at the earliest possible time. It does not have a probe or final phase.
Fully blocking
A few logical operations return no data at all until the final phase, when both the build and the probe input have been consumed. This makes these operations fully blocking.
For the Left Semi Join and Left Anti Semi Join operations, the build phase loads data from the build input in the hash table, the probe phase processes the probe input to mark rows in the hash table as matched, and the final phase then returns either all matching or all non-matching rows.
The [Partial] Aggregate logical operations have only a build phase and a final phase. The build phase, processes data and stores in in the hash table without returning anything. Once the build input is fully processed, the final phase can return all these rows.
Memory usage
Since the Hash Match operator stores the entire build input (or, in the case of [Partial] Aggregate or Flow Distinct, one row per value of the grouping columns) in an in-memory hash table, it needs a large amount of memory to work with. The requested memory is computed when the execution plan is compiled and stored in the Memory Grant property of the execution plan. Since that property applies to the entire execution plan, it represents the (estimated) memory requirement of all operators in the execution plan – or at least all that need their memory concurrently.
The memory requirement of individual operators is not stored in the execution plan, though you can sometimes reverse engineer this from the Memory Grant of the plan as a whole and the Memory Fractions properties of the individual operators. This will be the subject of a future article.
You might expect the memory grant computation for a Hash Match to be based on the expected size (Estimated Number of Rows multiplied by Estimated Row Size) of the build input. However, empirical evidence shows that the expected size of the probe input is also, to an extent, taken into account. Since [Partial] Aggregate and Flow Distinct do not store the entire input but effectively store only the output in the hash table, the expected size of the output is used for those logical operations. Other than the above, no exact details for the memory grant computation of Hash Match are known at this time.
Spilling
As described above, the memory grant is computed based on estimated cardinalities. If at runtime the actual cardinality (or the actual average row size) is much larger, the execution engine might run out of memory. Barring a few very specific exceptions, it is not possible to allocate extra memory once the execution plan has started, so when a Hash Match operator runs out of memory it has to use tempdb as temporary storage in order to finish its work. This process is called spilling. A Hash Warning event is raised whenever this happens; this event can be caught with Extended Events. If the execution plan plus run-time statistics (actual execution plan) of a query is captured, then the spill is also exposed as a warning on the affected operator.
Spilling always happens during the build phase, as this is the only phase that adds rows to the hash table. (Other phases only read the hash table and optionally change the value of the matched marker and the aggregation counters, but this never increases the required memory).
When Hash Match spills, the hash table is split into two or more partitions. For all but one of these partitions, the current data in the hash table is stored in tempdb and then released from memory. The build phase then continues; new rows are either added to the hash table in memory or stored in tempdb for later processing. The same happens during the probe phase: rows from the probe input are either processed immediately using the partition of the hash table that is in memory, or stored in tempdb for future processing. After the probe and final phase are done, the algorithm then switches to the next partition, using the data in tempdb to repeat the process.
Because all partitions except the first are processed after both inputs were fully read, this effectively changes the Hash Match operator to be fully blocking. However, for optimization purposes the optimizer assumes that no spilling will occur, so it assume the “normal” (non-spilling) blocking level for the requested logical operation.
The above is a severe simplification. A much more detailed description of the spilling process is planned for a future article.
Partial Aggregate
A Hash Match (Partial Aggregate) differs from the “normal” Hash Match (Aggregate) in how it handles memory usage and spilling. For Partial Aggregate, the operator always only requests a fixed, minimal amount of memory, based on the fact that this logical operation is only used when the optimizer expects a relatively small number of groups. If it does run out of memory, the operator does not spill. Instead, it simply stops adding rows to the hash table. Input rows for which the Hash Keys (Build) hash to a value already in the hash table are still aggregated in the counters of that row, but input rows that hash to a new value are simply passed unaggregated. Or rather, as a group of just that row.
This behavior actually means that the Partial Aggregate logical operation has the potential to return data that could be considered incorrect. The reason this is possible is because a Partial Aggregate logical operation is only used in a context where the partially aggregated data is later further aggregated to result in a final, “global” aggregate. So any of these “errors” where the partial aggregation leaves some of the data unaggregated will be fixed later in the execution plan anyway.
Operator properties
The properties below are specific to the Hash Match operator, or have a specific meaning when appearing on it. For all other properties, see Common properties. Properties that are included on the Common properties page but are also included below for their specific meaning for the Hash Match operator are marked with a *.
| Property name | Description |
|---|---|
| BitmapCreator | When this property is present and set to true, the Hash Match operator creates a batch mode bitmap at the end of the build phase, based on the contents of the hash table. The name of the bitmap table is listed in the Defined Values property. This is only possible for Hash Match running in batch mode. Introduced in SQL Server 2014. |
| Build Residual | For [Partial] Aggregate and Flow Distinct, this list the full set of columns that need to be equal for rows to be aggregated together. Only used when the columns defined in Hash Keys Build allow for hash collisions. |
| Defined Values * | For [Partial] Aggregate, this lists the names and definition for each of the aggregations that is computed within the operator. When the property is empty, no aggregation is done and the Hash Match ([Partial] Aggregate) operator effectively performs a DISTINCT operation.For Union, this lists, for each output column, the two corresponding input columns. For all other operations, this is empty unless the BitmapCreator property is true. |
| Estimated CPU Cost * | Specifically for Hash Match, the Estimated CPU Cost is not purely a measure of CPU ticks expected to be required; it also includes the cost of the memory grant. This is probably because there is no separate property in execution plans to weigh the cost of the estimated memory usage. |
| Estimated I/O Cost * | For a Hash Match operator this would normally be zero, since a Hash Match doesn’t do any I/O. The exception is when, during estimation, the optimizer estimates that more memory will be needed for the hash table then is available on the system. In such cases, the requested memory grant will be adjusted to fit within what is available on the server, and the Estimated I/O Cost property holds the cost of the expected spills to tempdb. |
| Hash Keys Build | Lists the columns from the build input that are used as input to the hash function to determine the correct bucket for these rows. Not included for Union (which always uses all columns). |
| Hash Keys Probe | Lists the columns from the probe input that are used as input to the hash function to determine the correct bucket for these rows. Not included for [Partial] Aggregate and Flow Distinct (which have no probe input) or Union (which always uses all columns). |
| Logical Operation * | The requested logical join type. Possible values are Inner Join, Left Outer Join, Right Outer Join, Full Outer Join, Left Semi Join, Left Anti Semi Join, Right Semi Join, Right Anti Semi Join, Union, Aggregate, Partial Aggregate, and Flow Distinct. |
| Probe Residual | This list the full set of conditions that needs to be met for a row from the probe input to be considered a match with a build row (in the hash table). Only used when the columns defined in Hash Keys Build and Hash Keys Probe allow for hash collisions, or when the query includes additional non-equality based conditions. Not used for [Partial] Aggregate and Flow Distinct (which have no probe input), or for Union (which always compares all columns). |
| Warnings | When present, this property signals that data was spilled to tempdb during the build phase and provides details on the extent of spilling. Only available in execution plan plus run-time statistics. |
Implicit properties
This table below lists the behavior of the implicit properties for the Hash Match operator.
| Property name | Description |
|---|---|
| Batch Mode enabled | The Hash Match operator supports both row mode and batch mode execution. Most of the descriptions on this page are for row mode execution. Specifics for batch mode are described in a separate section. |
| Blocking | Hash Match can be a semi-blocking, non-blocking, or fully blocking operator, depending on the logical operation requested. Hash Match becomes fully blocking if a memory spill occurs. Details are explained above. |
| Memory requirement | The Hash Match operator ideally needs sufficient memory to store the entire build input (for the join operations and Union), or for the entire result set (for Aggregate and Flow Distinct) in the hash table. If insufficient memory is available, data is spilled to tempdb which causes a massive performance hit. For the Partial Aggregate operation, spilling does not occur. See the main text for more details. |
| Order-preserving | As long as Hash Match does not spill to tempdb, the order of the probe input is preserved for the operations Inner Join, Right Outer Join, Right Semi Join, and Right Anti Semi Join, and the order of the build input is preserved for Flow Distinct. Other operations and other inputs do not conserve input. When spills to tempdb do occur, no order is preserved in any case. Because it is impossible to guarantee no spills for these logical operations, the optimizer considers Hash Match to be not order-preserving. |
| Parallelism aware | The Hash Match operator is not parallelism aware. |
| Segment aware | The Hash Match operator is not segment aware. |
Change log
(Does not include minor changes, such as adding, removing, or changing hyperlinks, correcting typos, and rephrasing for clarity).
May 31, 2018: Added.
January 3, 2019: Corrected a mistake in the list of implicit properties (two join types were erroneously listed as order-preserving).
January 14, 2019: Added links to blog posts by Bert Wagner with animated visualization of the algorithms.
February 10, 2019: Added some additional information on whether the build phase runs during Init() processing or during the GetNext() processing (thanks, Martin).
June 20, 2020: Added extra information on Estimated CPU Cost and Estimated I/O Cost properties.
November 18, 2020: Removed wrong information and added corrected description of the Partial Aggregate logical operation. (Thanks, Paul!).
June 1, 2023: Corrected the description of the BitmapCreator property to reflect that they create a bitmap at the end of the build phase rather than during the build phase.
August 23, 2023: Found and corrected a severe mistake in the described internals of the Union Logical Operation. Also added additional information on tracking of matches for some Logical Operations.
September 19, 2023: Added clarification of difference between batch-mode bitmaps and row-mode bitmaps, with links to deeper explanation.
November 10, 2023: Small correction to the flowchart for the aggregated build phase (a direct result of the correction I made to the text in August 23, 2023); small extra clarification of the actions for Logical Operation Union.
January 7, 2025: Added information about batch mode aggregate pushdown; added some additional details about flow distinct; clarified the information on order preservation.