Stream Aggregate
Introduction
The Stream Aggregate operator is one of the two operators that perform aggregation on their input. It has a single input and a single output, and typically the number of rows in its output is far less then in its input because it returns just a single row for each group of rows in the input.
Stream Aggregate is the most effective of the two aggregation operators. However, it requires its input data to be sorted by the grouping columns. Often this means that a Stream Aggregate can’t be used without adding an extra Sort operator. This extra sorts increases the total plan cost. In such cases, the optimizer tends to choose the alternative aggregation operator, Hash Match.
Visual appearance in execution plans
Depending on the tool being used, a Stream Aggregate operator is displayed in a graphical execution plan as shown below:
|
SSMS and VS Code |
Legacy SSMS |
Plan Explorer |
Paste The Plan |
Algorithm
The basic algorithm for the Stream Aggregate operator is as shown below:
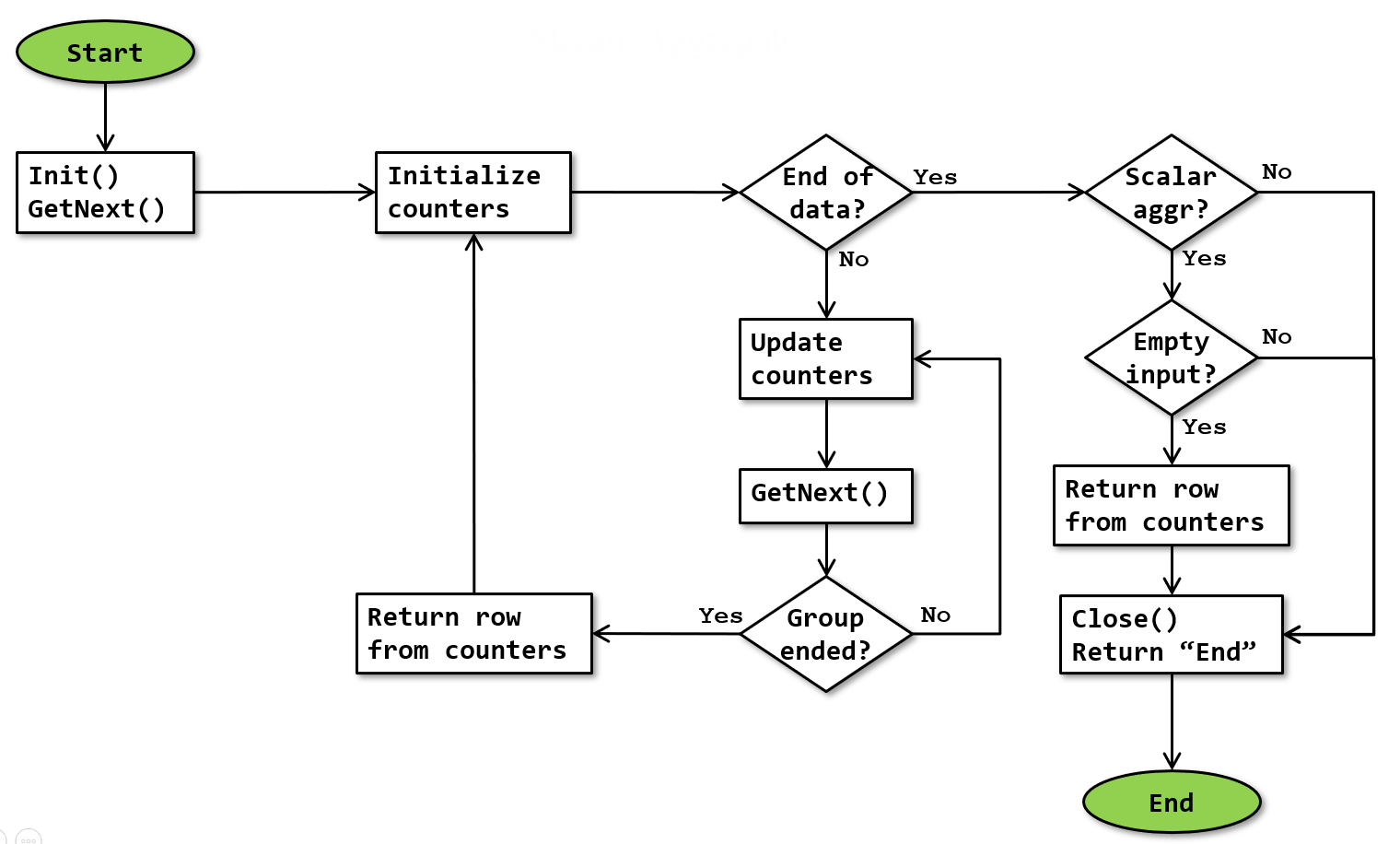 Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called. The additional processing for subtotals and grand totals (described below) is also not shown in this flowchart.
Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called. The additional processing for subtotals and grand totals (described below) is also not shown in this flowchart.
The flowchart shows how the operator processes the data from the input. The rows for a group are accumulated in internal counters and returned as soon as the group is complete. The optimizer ensures that the input data is sorted by the Group By columns. That means that all rows for a single group are adjacent in the input stream; as soon as a group is ended its data can be returned and a new group started. The end of a group is detected by encountering either a new value in a Group By column or (obviously) be reaching the end of the input data. At that point, the accumulated aggregations for the “previous” group are returned and the counters are reset in preparation for a new group.
Scalar aggregation
When the operator has no Group By property, a scalar aggregation (a single row with the aggregation of all input rows) is requested. Processing is mostly the same as for “normal” (grouped) aggregation; obviously since all data is now a single group, the group only ends at the end of all input. However, when there are no rows in the input, a scalar aggregate still has to return a row, with the initial values of the aggregate counters. This is ensured by testing, after the end of input, whether a scalar aggregate was requested, and if so whether the input was empty. (The latter test might be done by looking at the counter values, or a dedicated Boolean internal variable might be used).
Counter details
The flowchart above shows when “internal counters” are initialized, updated, and returned as a row. In these internal counters, the following data is tracked:
- The value of each of the columns in the Group By property for the group of rows currently being processed. In “Initialize counters”, these counters are set equal to the values in the current row. In “Update counters”, they are not changed. In “Same group?”, they are compared to the values in the current row to determine whether the current row belongs to the same group. (And because the ANSI standard states that for the purpose of grouping all null values are to be considered part of a single group, null values are considered equal in this specific case).
- The “work in progress” values of all the aggregate functions that need to be computed by the operator, as specified in the Defined Values How these counters are set in “Initialize counters” and updated in “Update counters” is specified in the table of all aggregate functions.
Window aggregation
A Stream Aggregate operator adapts its behavior if its direct descendant is a Window Spool operator. This pattern is used for aggregates that use an OVER clause with an (explicit or implicit) ROWS or RANGE specification (to specify frame of rows within the window defined by PARTITION BY) to define aggregation over a framed window of rows. In this case:
- the Group By expression is always the WindowCount column returned from the Window Spool;
- the Output List property contains a lot of columns from the input, that are defined in the Defined Values property using the ANY aggregate function; and
- the Output List property also contains a few new expressions defined using other aggregate functions.
In this case, the first row received within each group skips the “Update counters” step. This is an extra row produced by Window Spool, with the “current row”. The “Update counters” step needs to be skipped in this case because this row is an extra copy; updating the counters for this row would result in a double count (if the current row is part of the defined window), or result in counting it once (if it should not be counted at all because it is not part of the defined window). Since the ANY counters are set on initialization, they do take their values from this first row.
If fast-track optimization is enabled or when a RANGE specification is used, the “Initialize counters” step processes as normal, resetting all counters, for only the first group in a segment. For later groups in the same segment, the counters for columns defined with the ANY function are initialized again, but all other counters are left unchanged.
For a ROWS specification without fast-track optimization, the “Initialize counters” always processes as normal, resetting the counters for all columns.
ROLLUP processing (Adding subtotals and grand totals)
For queries that specify a ROLLUP, CUBE, or GROUPING_SETS specification on the GROUP BY clause (or the deprecated equivalent syntax using WITH ROLLUP or WITH CUBE), but possibly for other use cases as well, the Rollup Information property can be added to this operator to specify that it has to do rollup processing instead of its normal processing. Rollup processing returns the aggregated results, but adds additional rows with subtotals and grand totals to the results.
For each aggregate function in the Output List, multiple internal counters are used, depending on the Highest Level subproperty of the Rollup Information property. The required extra rows, as indicated in the Rollup Levels subproperty, are returned when one or more of the Group By columns change, and then only the appropriate counters are reset, while the counters for other rollup levels are left unchanged.
The Output List property may include one additional column, named ‘Grp’ plus a 4-digit number that is unique within the execution plan. This column is an integer, and its set bits show the rollup level. It is not specified in the Defined Values property.
For instance, a Stream Aggregate operator has columns Expr1001, Expr1002, and Expr1003 as its Group By columns, the Rollup Information specifies that the Highest Level is 3, and the Rollup Levels are 0, 1, and 3. The Output List property specifies a grouping column Grp1004. In this case, Stream Aggregate accumulates data until Expr1003 changes, and then returns data aggregated by Expr1001, Expr1002, and Expr1003 as rollup level 0, with Grp1004 equal to 0. When Expr1002 changes, an extra row is returned as rollup level 1, with Expr1003 set to NULL and Grp1004 set to 1 (bit 0 is set). When Expr1001 changes, no extra row is returned, because rollup level 2 is not specified in the Rollup Information property. After reading and returning the last individual row, Stream Aggregate then not only returns the last rollup level 0 and rollup level 1 rows, but now also returns a row with the grand total: rollup level 3, with Expr1001, Expr1002, and Expr1003 all set to NULL, and Grp1004 set to 7 (4+2+1, because bits 2, 1, and 0 are all set).
Operator properties
The properties below are specific to the Stream Aggregate operator, or have a specific meaning when appearing on it. For all other properties, see Common properties. Properties that are included on the Common properties page but are also included below for their specific meaning for the Stream Aggregate operator are marked with a *.
| Property name | Description |
|---|---|
| Defined Values * | Names and definition for each of the aggregations that is computed within the Stream Aggregate operator. When this property is empty, no aggregation is done and the Stream Aggregate operator effectively performs a DISTINCT operation. |
| Group By | Lists the columns from the input stream that define the group boundaries. The output will contain one row for each distinct combination of values in these columns. When this property is missing, a single row with scalar aggregation results is returned. |
| Output List * | The Output List of a Stream Aggregate is always equal to zero or more of the columns in the Group By property, followed by all of the columns in the Defined Values property. |
| Rollup Information | When this property is present, the operator returns additional rows with subtotals and grand totals to the output stream. This is described above. This property has two subproperties:
|
Implicit properties
This table below lists the behavior of the implicit properties for the Stream Aggregate operator.
| Property name | Description |
|---|---|
| Batch Mode enabled | The Stream Aggregate operator supports row mode execution only. |
| Blocking | The Stream Aggregate operator is non-blocking. Note that obviously it has to read all rows for a group before it can return the single row for that group, but because it does not return any other rows this is not considered blocking. For a scalar aggregation, Stream Aggregate will (obviously) block because it is impossible to return correct results without processing the entire input. |
| Memory requirement | The Stream Aggregate operator does not have any special memory requirement. The internal counters are stored in the standard working memory that all operators get assigned. |
| Order-preserving | The Stream Aggregate operator is fully order-preserving. |
| Parallelism aware | The Stream Aggregate operator is not parallelism aware. |
| Segment aware | The Stream Aggregate operator is not segment aware, except when Stream Aggregate has a Window Spool as its child. In that case, the input must be segmented, as described above. |
Change log
(Does not include minor changes, such as adding, removing, or changing hyperlinks, correcting typos, and rephrasing for clarity).
May 31, 2018: Added.
September 20, 2020: Added description of the special behavior when used in combination with a Window Spool operator; added information about how the ANY aggregate function works.
November 18, 2020: Improved description of the interaction with Window Spool for windowed aggregates; corrected wrong information about behavior for windowed aggregates with a RANGE specification.
December 3, 2020: Moved the list of all aggregate functions to a separate page.
November 10, 2023: Added the Rollup Information property and a description of the additional work for rollup processing (to add subtotals and grand totals); clarified the processing of this operator for aggregation of a framed window (OVER clause with implicit or explicit ROWS or RANGE specification).
December 12, 2023: Corrected the flowchart to return correct results for a scalar aggregate and improved the description of scalar aggregation computation in the text.
May 29, 2026: Full rewrite of the section on rollup processing and the description of the Rollup Information property.