Sort
Introduction
The Sort operator is used to reorder data. It reads its input data into an internal worktable, sorts it as specified, and then returns that sorted data to its parent operator.
The Sort operator supports three different logical operations:
- When the Logical Operation property is Sort, the operator does a basic sort of its input and returns the exact same data, ordered as specified in the Order By property.
- When the Logical Operation property is Distinct Sort, the operator sorts the input, but only returns a single row for each distinct set of values in the Order By columns, effectively removing duplicates.
- When the Logical Operation property is Top N Sort, the operator sorts the input, and then only returns the first N rows from the sorted results, where the value of N is found in the Top Rows property.
Please note that most of the internals of the Sort operator are totally undocumented. A lot of the information on this page is based on research that Paul White did in 2015, plus my own research and common-sense assumption.
Visual appearance in execution plans
Depending on the tool being used, a Sort operator is displayed in a graphical execution plan as shown below:
|
SSMS and VS Code |
Legacy SSMS |
Plan Explorer |
Paste The Plan |
Algorithm
The algorithm for the Sort operator consists of two phases. These are not officially documented or named by Microsoft; I call them the build phase and the final phase, in analogy of the similar phases for the Hash Match operator.
Note that in all the descriptions below, I assume an ascending sort order. When one or more of the columns in the Order By property have a descending sort order requested, then all greater than and less than tests, and all highest and lowest values, are reversed.
Seven implementations
According to Paul White, there were a total of seven implementations available for the Sort operator when he researched this in 2015. These findings are described in detail here and here.
While undocumented internals are always subject to change without notice, I assume most of Paul White’s findings are still applicable in newer versions of SQL Server.
- CQScanSortNew
This is the default implementation, used when none of the conditions for the other implementations are met. - CQScanTopSortNew
This implementation is used when the Logical Operation property is Top N Sort. - CQScanIndexSortNew
This implementation is used for sorting in DDL index building plans. It is the only implementation that can dynamically request additional memory when the Memory Grant is insufficient. However, it can still spill, because it is not guaranteed to receive the additional memory it requests. - CQScanPartitionSortNew
This implementation is used to optimize inserts into a partitioned clustered columnstore index. It implements a “soft sort”. This means that, if it runs out of memory, it will return results that are not fully sorted, rather than spilling to tempdb. That is in this case acceptable, because this sort is only in the execution plan as a performance optimization for the subsequent insert; spilling to ensure fully ordered results would cost more performance than this optimization gains and is therefore unwanted. - CQScanInMemSortNew
This implementation is only used when the data to be sorted is returned by a Constant Scan operator that returns no more than 500 rows. This threshold can be lowered based on the number of columns and their data types. Because of this size limitation, it never needs to spill to tempdb. - In-Memory OLTP (Hekaton) natively compiled procedure Top N Sort
This implementation is only used in the execution plans of natively compiled stored procedures, for Sort operators with Logical Operation Top N Sort. - In-Memory OLTP (Hekaton) natively compiled procedure General Sort
This implementation is only used in the execution plans of natively compiled stored procedures, for Sort operators with Logical Operation Sort or Distinct Sort.
Most of the information on this page describes the first two implementations, while calling out relevant differences for the next three where applicable. The last two, for natively compiled stored procedures, are briefly described at the end, along with a short section on batch mode sorting.
Build phase
The build phase is always the first phase to run. This phase normally runs as part of the Initialize() call, except for the CQScanPartitionSortNew implementation, where the build phase is run when the first GetNext() call is received.
There are two versions of the build phase. In most cases, the normal version is used. The optimized top N version is only used by the CQScanTopSortNew implementation (for a Sort operator with Logical Operation Top N Sort), and then only when the Top Rows property is 100 or less.
Normal build phase
The normal algorithm for the build phase is as shown below:
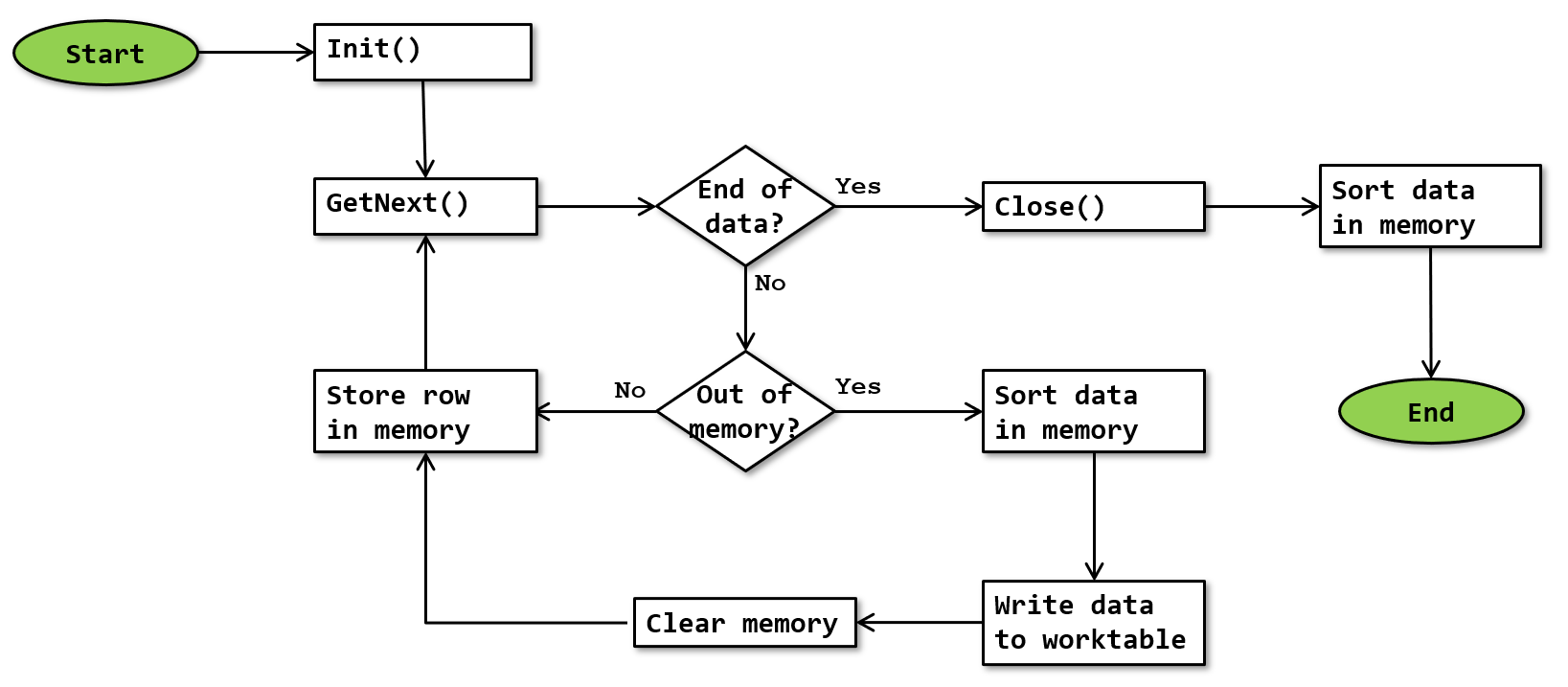 This flowchart describes both the ideal case where all data fits in the available memory, and the case when there is more data, so that the operator has to spill to tempdb.
This flowchart describes both the ideal case where all data fits in the available memory, and the case when there is more data, so that the operator has to spill to tempdb.
Sort data in memory
The normal build phase tries to read all data in memory. If there is insufficient memory, then it reads as much data in memory as fits. The data in memory is then sorted, using an algorithm that is optimized for sorting in-memory data. When Paul White researched the internals in 2015, he concluded that the algorithm used was likely a variety of the internal merge sort algorithm. If you look at the description of this algorithm on the Wikipedia page, you’ll see that it often swaps two of the values to be sorted. I assume that Microsoft’s implementation swaps pointers to the rows, rather than swapping entire rows.
For the CQScanInMemSortNew implementation, which never sorts more than 500 rows, the sorting is instead done by using quicksort qsort_s in the standard C run-time library MSVCR100.
It is of course possible that Microsoft has rewritten the operator between 2015 and now, to use different algorithms. If they did, they didn’t publicize anything about this optimization.
Out of memory?
When the operator runs out of available memory during the build phase, one of several things can happen.
The CQScanIndexSortNew implementation is the only implementation that can dynamically request additional memory while it is running. If the extra memory is granted, then the build phase is no longer out of memory, and so it can just continue as normal. When the extra memory is not granted, then the operator continues just as the other implementations would when they run out of memory, by spilling to tempdb. (Note that the extra logic for this implementation is not included in the flowcharts on this page).
The CQScanPartitionSortNew implementation avoids spills by doing a “soft sort”. When out of memory, the operator sorts the subset of data that is at that time in memory, and then moves to the final phase to return that sorted subset. Once it has returned all data, it clears the memory, and then continues the build phase, which effectively is the same as restarting it. In other words, it simply starts to read and store the next batch of data in memory. (Note that the extra logic for this implementation is not included in the flowchart above).
In all other cases, the operator needs to spill to tempdb. My assumption is that the operator at this time first sorts the subset of data that is at that time in memory, and then stores that sorted data in a worktable in tempdb. After that, it clears its work memory, and then continues the build phase, which effectively is the same as restarting it. In other words, it simply starts to read and store the next batch of data in memory. If the operator runs out of memory again while reading and storing this second batch of data, it repeats this process, creating a second worktable, then a third, and so on.
Optimized build phase for Top N Sort
When the Sort operator has Logical Operation Top N Sort, and the value of N (as stored in the Top Rows property) is 100 or less, then another algorithm is used for the build phase:
 Rather than first storing all data and the sorting it, the algorithm ensures that there are never more than Top Rows values stored. As a result, this version of the algorithm consumes far less memory, and it can never spill to tempdb.
Rather than first storing all data and the sorting it, the algorithm ensures that there are never more than Top Rows values stored. As a result, this version of the algorithm consumes far less memory, and it can never spill to tempdb.
The first N rows that the operator reads are stored in memory, but in a sorted structure. I assume that this is done without moving actual rows; instead, either data in a fixed array of pointers is moved, or the sorted in-memory data is implemented as a doubly linked list so that the row can be inserted at the required position without moving data, by updating just a few pointers.
Rows after the Nth row are simply discarded when the values in their sort columns sort after those in the Nth row in storage. If they sort before the Nth row, then what was the Nth row is removed, and then the new rows is stored instead, again in the correct location in the sorted internal structure.
This effectively implements the insertion sort algorithm.
I assume that this is done without moving actual rows; instead, either data in a fixed array of pointers is moved, or the sorted in-memory data is implemented as a doubly linked list so that the row can be inserted at the required position without moving data, by updating just a few pointers.
In theory. it would be possible to first collect N elements unsorted, then sort them, e.g. using quicksort, or any other sort algorithm; and then continue with insertion sort for the rest of the input. However, since this algorithm is only used for values of N up 100, the amount of performance gained that way would be extremely low (in the order of microseconds), at the expense of a huge increase in complexity. Because of that, I assume that Microsoft has chosen to keep the algorithm simple and use insertion sort right from the start.
Final phase
The final phase is executed after all data (or, in the case of CQScanPartitionSortNew, the current batch of data) is read in memory (plus tempdb, if and as needed) and sorted. All that is left to do is to return the data.
Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called. It also doesn’t show what happens when the Sort operator has to spill recursively.
 When no data was spilled to tempdb (or when a batch of sorted data is returned by CQScanPartitionSortNew), the operator simply returns the data that is already sorted in memory, while skipping duplicates if the Logical Operation is Distinct Sort. When data did spill during the build phase, then there are now one or more worktables that each hold a part of the data, sorted, while the last batch of data is in memory, also sorted. The final phase reads all those sources at the same time, constantly returning the row from the source that sorts before the rows from all other sources.
When no data was spilled to tempdb (or when a batch of sorted data is returned by CQScanPartitionSortNew), the operator simply returns the data that is already sorted in memory, while skipping duplicates if the Logical Operation is Distinct Sort. When data did spill during the build phase, then there are now one or more worktables that each hold a part of the data, sorted, while the last batch of data is in memory, also sorted. The final phase reads all those sources at the same time, constantly returning the row from the source that sorts before the rows from all other sources.
Read first row(s)
At the start of the final phase, the operator always reads the first row from the sorted data in memory. If the operator spilled during the build phase, then one or more sorted worktables have been created in tempdb, and the operator reads the first row from each of those as well.
Find smallest Order By value
If no data was spilled and no worktable was used, then the smallest value is always from the current row from the in-memory data. When worktables were used, then SQL Server compares the values in the Order By columns of the current rows from the in-memory data and each of the worktables and finds the one that sorts first. In the case of a tie, any of the tying rows can be selected. It is unknown which one is selected in such a case. The end of data signal from any of these inputs is considered to be last regardless of sort order, hence the smallest Order By value will only be end of data when all inputs are depleted.
Distinct Sort / Duplicate row
If the Distinct property is true, then the operator compares the data in all Order By columns of the row that was identified to have the smallest values to the values in the last returned row. If they are the same (and for purposes of this comparison, two NULL values are considered equal), then the row is a duplicate and should not be returned. In that case, the Return row step is skipped, but the steps after that to read the next row are still executed.
Read row from memory / from worktable n
After returning (or skipping) the row with the smallest Order By value, the operator reads the next row from only the input where this row originated from. So if the smallest Order By value was found in memory, then the next row from the in-memory data is read. But if the smallest Order By value was in any of the worktables, then it reads the next row from only that worktable.
Recursive spilling
If the number of worktables is above a certain threshold, the final phase adds an extra step that is not shown in the flowchart. This step uses the same procedure to combine data from a subset of the worktable, plus optionally the in-memory data, to create a new, larger sorted worktable in memory, that effectively replaces all the input worktables. It keeps combining worktables this way until the number of sorted sets drops below the threshold and the final pass can be done to return the sorted data.
Sorting in natively compiled stored procedures
For In-Memory OLTP (Hekaton) natively compiled procedures, the Sort operator does not use any of the five implementations described above. Instead, it uses two different implementations, one for regular Sort, and another one for Top N Sort.
Regular Sort and Distinct Sort in natively compiled stored procedures
For regular Sort in a natively compiled stored procedure, the operator first stores the data in multiple smaller batches, that are each sorted using the standard quicksort algorithm (qsort_s). After that, priority queues are used to merge those batches.
Since SQL Server 2016, Distinct Sort is also supported in natively compiled stored procedures. This uses the same sorting algorithm, so (like Distinct Sort in row mode execution plans) it does not remove duplicates while reading or sorting. Instead, duplicate rows are skipped when the sorted data is returned.
Top N Sort in natively compiled stored procedures
The algorithm for Top N Sort in natively compiled stored procedures can be used for values of N up to 8192. This limit can be reduced when there are additional joins and aggregations in the execution plan.
This algorithm inserts data into a priority queue during its build phase. Similar to row mode Top N Sort, only the first N rows are retained in this process. Once all data is stored, the standard quicksort algorithm (qsort_s) is used to complete the sorting.
Batch mode sort
Since SQL Server 2016, the Sort operator can also execute in batch mode. At this time, nothing is known about the internals of the Sort operator when it is running in batch mode. However, we do know that a batch mode Sort can dynamically request extra memory when the Memory Grant is insufficient, but also that it can still spill to tempdb when its requests for extra memory are denied.
Because batch mode execution gains performance by processing one batch at a time, it is likely that a batch mode Sort sorts each batch as soon as it is read, then stores the sorted batch in main memory, and merges the sorted batches when rows are returned. This may or may not use a recursive process, similar to how worktables in tempdb are merged when Sort spills.
While regular Sort and Top N Sort are both supported in batch mode, I have not been able to create an execution plan with a batch mode Distinct Sort. So I assume that Distinct Sort is not supported in batch mode.
Erik Darling has found that a batch mode Sort that spills to tempdb can cause a much worse performance hit than an equivalent spill of a row mode Sort. Paul White provides an explanation for this extreme slowdown.
Rebinds and rewinds
A Sort operator on the inner input of a Nested Loops operator executes multiple times, and every execution is reported as either a rebind, or a rewind. A rebind means that the sort buffer (data in memory plus data in spilled worktables, if any) is cleared, the child operator is reinitialized, and rows are once more requested, stored, sorted, and the returned. A rewind means that the data currently in the sort buffer is used to return the same data again, without executing the child subtree.
Paul White has discovered that, even when a Sort operator reports a rewind, it actually in reality often performs a rebind. A reported rewind is only actually a rewind when either the number of rows in the sort buffer is zero or one, or the CQScanInMemSortNew implementation is used. For other implementations, when two or more rows are in the sort buffer, the Sort operator always rebinds. The only way to detect this in an execution plan plus run-time statistics is that the Number of Executions property of the child operator is in this case higher than the Actual Rewinds property of the Sort operator. The difference is the number of reported rewinds that were actually rebinds.
For the CQScanPartitionSortNew implementation, this behavior actually makes sense. When out of memory, it sorts and returns data in memory at that time, then clears the memory and continues to read and later sort and return the rest of the data. Since some of the data returned is no longer in the sort buffer, a rewind would return incomplete results in this case.
But for the other implementations, I see no clear reason. Paul White speculates that rewinding sort results is expensive, “due to the underlying sorting machinery”. I don’t think that tells the whole story. After all, that same “sorting machinery” also has to be repeated on a rebind, in addition to re-executing the child subtree. So my own theory is that there is something in the internals of how the Sort operator works that can cause incorrect results on a rebind of more than one row. Perhaps there is some mechanic that releases memory, or spilled worktables, once that part of the data has been returned. In that case, a rewind could no longer return that same data. But it would, in my opinion, make far more sense to not release anything until the operator is reinitialized or closed, so that a rewind is always possible.
Operator properties
The properties below are specific to the Sort operator, or have a specific meaning when appearing on it. For all other properties, see Common properties. Properties that are included on the Common properties page but are also included below for their specific meaning for the Sort operator are marked with a *.
| Property name | Description |
|---|---|
| Distinct | This property is True when the Logical Operation is Distinct Sort, and False otherwise. |
| Internal Debugging Information * | This property exposes some internal information about the sort algorithm used. It is only exposed in execution plans when trace flag 8666 is active. Since this is an undocumented trace flag, it should never be used in production code, unless specifically requested by Microsoft support staff. For a Sort operator, the Internal Debugging Information exposes four sub-properties:
|
| Logical Operation * | The requested logical operation. Supported values are Distinct Sort, Sort, and Top N Sort. The differences and similarities for each are described in the main text. |
| Order By | A list of one or more columns, each with an Ascending or Descending specification, to determine the order of the rows in the output. When there are multiple rows in the data with the same values in all Order By columns, then their order is undefined. (Or, when the Logical Operation is Distinct Sort, the row returned from that set is undefined). |
| Partition ID | When this property is present, the sort is partitioned. Data for each partition is sorted separately. This is typically used when data needs to be inserted in a partitioned index. |
| Top Rows | This property is only included when the Logical Operation is Top N Sort. It stores a positive integer, specifying the maximum number of rows to be returned. When Top Rows is 100 or less, the CQScanTopSortNew implementation uses a different algorithm for the build phase, as explained in the main text. |
| Warnings | When present, this property signals that data was spilled to tempdb during the build phase and provides details on the extent of spilling. Only available in execution plan plus run-time statistics. |
Implicit properties
This table below lists the behavior of the implicit properties for the Sort operator.
| Property name | Description |
|---|---|
| Batch Mode enabled | The Sort operator supports row mode in all versions. Batch mode execution is supported since SQL Server 2016, except for the Distinct Sort Logical Operation. Nothing is known at this time about the internals of a batch mode Sort, but the main text does include some speculation. |
| Blocking | The Sort operator is fully blocking. |
| Memory requirement | The Sort operator ideally needs sufficient memory to store the entire build input, or to store Top Rows rows for a Top N Sort when Top Rows is 100 or less, or any Top N Sort in a natively compiled stored procedure. If insufficient memory is available, data is, in most cases, spilled to tempdb which causes a massive performance hit. See the main text for more details. |
| Order-preserving | The Sort operator imposes the order as specified in the Order By predicate on the data it returns. |
| Parallelism aware | The Sort operator is not parallelism aware. |
| Segment aware | The Sort operator is not segment aware. |
Change log
(Does not include minor changes, such as adding, removing, or changing hyperlinks, correcting typos, and rephrasing for clarity).
July 17, 2023: Added.
August 4, 2023: Added a paragraph to clarify that in some cases, reported rewinds are in reality rebinds (thanks, Paul!).
September 9, 2023: Improved flowchart and description of the optimized build phase for Top N Sort.
November 9, 2024: Added the Warnings property to the property list. (I still can’t believe that I forgot that one!).
May 12, 2026: Updated with changes since SQL Server 2016. Added description of recursive sort spill.