Split
Introduction
The Split operator is typically used to optimize update processing, usually in combination with Collapse and Sort operators. This operator splits rows that represent an update into two rows each, representing a delete and an insert. Input rows that already represent a delete or an insert are passed unchanged.
In cases where the input data contains both a current and an old version of the data, the old version will be included in the output row that represents the delete, and the current version will be included in the output row that represents the insert.
Visual appearance in execution plans
Depending on the tool being used, a Split operator is displayed in a graphical execution plan as shown below:
|
SSMS and VS Code |
Legacy SSMS |
Plan Explorer |
Paste The Plan |
Algorithm
The basic algorithm for the Split operator is as shown below:
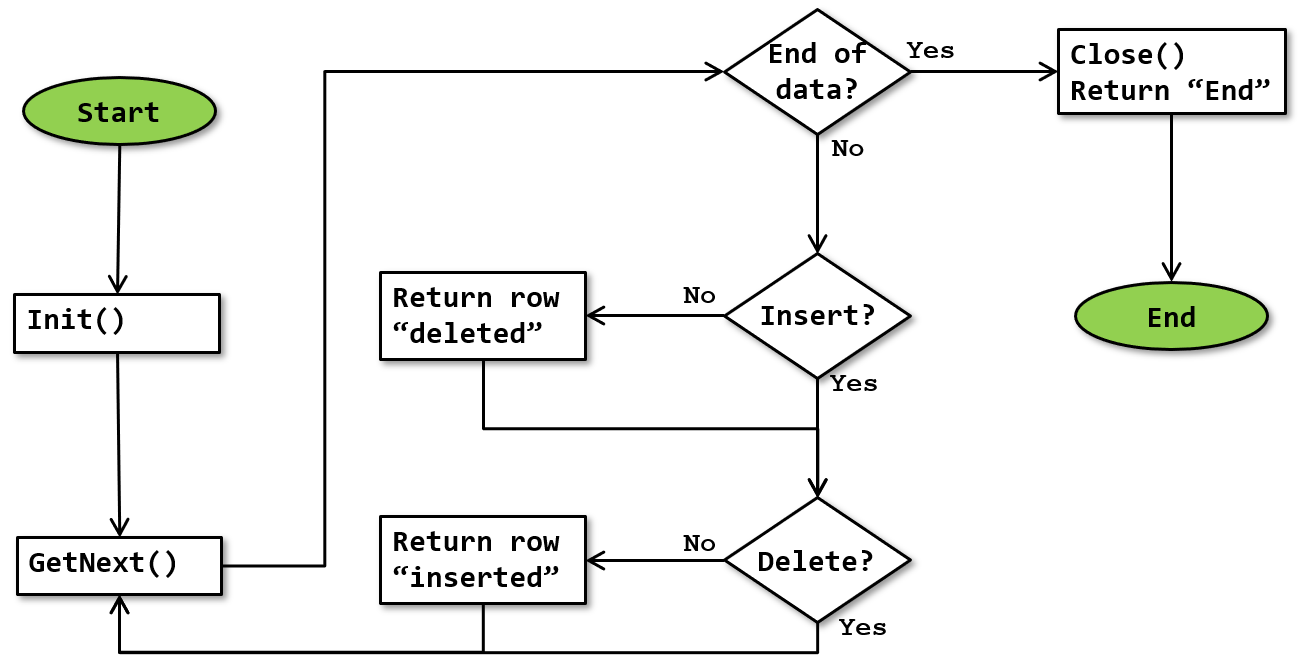 This flowchart is drawn on the assumption that, when an update row in the input is translated into a delete row and an insert row, they are retuned in that order, which is the most likely order. But so far there has not been any conclusive proof that this is indeed the case; in theory the inserted row could be returned before the deleted row.
This flowchart is drawn on the assumption that, when an update row in the input is translated into a delete row and an insert row, they are retuned in that order, which is the most likely order. But so far there has not been any conclusive proof that this is indeed the case; in theory the inserted row could be returned before the deleted row.
Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called.
Action Column
The Split operator is one of a few operators that support a so-called Action Column to clarify what type of modification a row represents. In the case of the Split operator, the action column is always present in the output data. The input data may or may not include an action column; if it is it always has the same column name as the output action column.
The known values and their meaning for the action column (for any operator, not just for Split) are:
- 1: Update
- 3: Delete
- 4: Insert
It is currently unknown whether there are more possible values. Based on what the Split operator does, its output will of course only use values 3 and 4 (delete and insert).
Old and new column pairs
The Split operator processes rows that represent inserts, updates, and deletes. For updates, both the old and the new value of some of the columns may be required. These are passed in as separate columns. The mapping of old and new values for the same column is not visible in the execution plan, I assume that this is an oversight in the process to export the execution plan from its internal representation to the XML format used externally. In many cases, the new value is in a column named after the corresponding column in the table (typically using the four-part naming scheme consisting of database name, schema name, table name, and column name), and the old value is in a column that has the same column name followed by the suffix “_OLD” (typically using single-part naming). This is not always the case, though.
For all pairs of columns in the input that adhere to this naming convention, the Split operator will treat the two columns as representing the old (before update) and new (after update) values of the data. All remaining columns in the input are then treated as containing new values for columns where the old value is not needed, or as helper columns for use elsewhere in the execution plan and where no corresponding old value of the helper column is needed.
Sometimes the input to the Split operator can contain a mix of updates, deletes, and inserts, for instance in an execution plan for a MERGE statement, or in complex update plans for tables that participate in indexed views. In those cases, the rows that represent inserts will have only NULL markers in the old columns, and the rows that represent deletes will have only NULL markers in the new columns.
Insert? / Delete?
It is currently not fully known how the Split operator determines what type of operation a row represents. The main theories are:
- If an action column is available in the input, the value in that column is used to determine whether the row is an insert (4), update (1), or delete (3). If no action column is available, then all rows are assumed to be updates.
- Look at the old and new data in the available column pairs. If all old values are null, then assume the row to be an insert; if all new values are null then assume it to be a delete, and else assume it to be an update. A possible optimization for this logic would be to look at just one of the column pairs, for a column that does not allow nulls. A weakness in this method is that it is not guaranteed to be 100% correct if all column pairs are for nullable columns, however I have so far not seen any execution plans where that could cause incorrect results.
- Use method 1 if an action column is available in the input; use method 2 if not.
Based on the execution plans I have seen so far, I assume that method 1 is always used. All execution plans that I have seen where no action column was in the input were for cases where the input could only contain updates. However, I have not yet studied enough execution plans with a Split operator to be confident to claim this as the truth.
Return row “deleted”
When the input row represents either a delete or an update, this action returns a row that represents a delete. Columns in the output row are determined as follows:
- The Action Column is always set to 3 (delete).
- For old and new column pairs in the input, pass the old version of the input in the corresponding current column in the output of the Split. This implies that the new value is overwritten and not passed to the parent operator.
- Any remaining columns in the Output List retain the value from their like-named columns in the input, without any change.
Return row “inserted”
When the input row represents either an insert or an update, this action returns a row that represents an insert. Columns in the output row are determined as follows:
- The Action Column is always set to 4 (insert).
- Any remaining columns in the Output List retain the value from their like-named columns in the input, without any change. This includes old and new column pairs, which implies that the new value is passed unchanged and the old value is ignored.
Operator properties
The properties below are specific to the Split operator, or have a specific meaning when appearing on it. For all other properties, see Common properties. Properties that are included on the Common properties page but are also included below for their specific meaning for the Split operator are marked with a *.
| Property name | Description |
|---|---|
| Action Column | The name of the column that represents whether the row represents an update (1), a delete (3), or an insert (4). This column always appears in the Output List, where it can only be a delete (3) or an insert (4); it sometimes also appears in the Output List of the child operator, and hence in the input of the Split operator. |
| Defined Values * | The name of the column in the output data (the Output List of this operator itself) that represents whether the row represents a delete (3) or an insert (4). |
| Output List * | As described in the main text, columns in the input data (the Output List of the child operator) may include column names with the suffix “_OLD”, that hold the value these column had prior to updating or deleting the row. This naming convention is not guaranteed. |
Implicit properties
This table below lists the behavior of the implicit properties for the Split operator.
| Property name | Description |
|---|---|
| Batch Mode enabled | The Split operator supports row mode execution only. |
| Blocking | The Split operator is non-blocking. |
| Memory requirement | The Split operator does not have any special memory requirement. |
| Order-preserving | The Split operator is fully order-preserving. |
| Parallelism aware | The Split operator is not parallelism aware. |
| Segment aware | The Split operator is not segment aware. |
Change log
(Does not include minor changes, such as adding, removing, or changing hyperlinks, correcting typos, and rephrasing for clarity).
February 20, 2019: Added.
March 18, 2019: Huge rewrite after I found out that there is not always an action column in the input. I thought it needed this action column to determine how to treat each row, now I have removed that theory and replaced it with a few alternatives.
December 3, 2020: Updated with some new information on the mapping of “old” versus “new” values in updated rows.