Table Scan
Introduction
The Table Scan operator is used to read all or most data from a table that has no clustered index (also known as a heap table, or just as a heap). In combination with a Top operator, it can also be used to read just a few rows from a heap table when data order is irrelevant and there is no nonclustered index that covers all required columns.
The basic behavior of a Table Scan operator is very similar to that of the Index Scan operator when it chooses to do an IAM scan, but with a few very important differences. A heap table has no root, intermediate, and leaf level pages; it has data pages only. Each page read from the IAM is a data page and can be processed. But rows on a data page of a heap table can contain forwarding pointers, that cause out of order data access.
Visual appearance in execution plans
Depending on the tool being used, a Table Scan operator is displayed in a graphical execution plan as shown below:
|
SSMS and VS Code |
Legacy SSMS |
Plan Explorer |
Paste The Plan |
Algorithm
The basic algorithm for the Table Scan operator is as shown below:
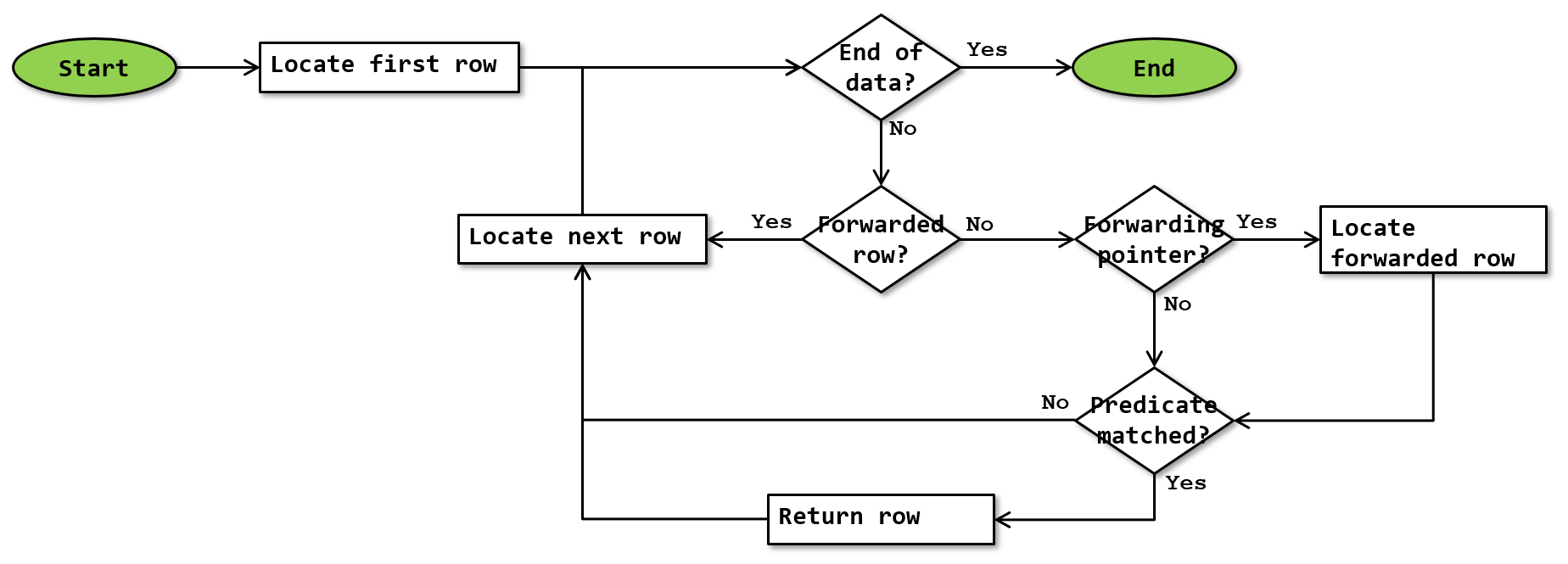 Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called. It also doesn’t include error handling for concurrency issues when a Table Scan uses READUNCOMMITTED / NOLOCK.
Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called. It also doesn’t include error handling for concurrency issues when a Table Scan uses READUNCOMMITTED / NOLOCK.
Locate first row / Locate next row
A Table Scan always uses the Index Allocation Map (IAM) to find all pages allocated to the heap table, similar to the “RowStore – Allocation Order Scan” of an Index Scan operator. To locate the first row, internal data structures (which can be seen through the sys.sysindexes view) are used to find the location of the first IAM page. It brings that page into the buffer pool, and then uses the row offset table on that page to find the location of the first row. To locate the next row, the row offset table on the current page is used to find the location of the next row; if the last row on the current page was already processed, it returns to the bitmap on the IAM page to find the next page allocated to this index, brings it into the buffer pool, and then once again uses the row offset table to find and return the first row on the page. Once it reaches the end of the bitmap without finding the next leaf page, it checks the NextPage pointer on the IAM page to find the next IAM page, brings that into the buffer pool, and then continues the process of scanning the bitmap. If no new leaf page is found and the last examined IAM page has a nil pointer in NextPage, then the end of the index data is reached and no row is returned.
Forwarded rows and forwarding pointers
In a heap, whenever existing data is updated and the new data does not fit on the page where the row is stored, the row is moved to a new page. The original location is not cleared completely; it is instead replaced by a so-called “forwarding pointer” – a pointer to the new location of the data. The row in its new location is then also marked as being “forwarded”, with a pointer to its original location added.
If a row that has already been forwarded later again is updated to not fit anymore, it will again move, but now the old location will be freed completely and the forwarding pointer in the original location will be modified to point to the new location. This means that in a heap table, every row is either in its original location, or the original location holds a forwarding pointer to the row’s current location, which itself is marked as forwarded with a pointer back to the original location.
As can be seen in the flowchart above, these markings and pointers are used by the Table Scan operator to read forwarded rows when the scan encounters the original location, and skip the forwarded rows when they are encountered in their current location. This may seem strange, since the Table Scan has no ordering guarantees for the data returned, but it’s needed for concurrency considerations as explained further below.
Predicate matched?
The Table Scan operator supports a Predicate property. When present, the logical test in this property will be applied to each row read, and only rows where the logical test results in True are returned. If no Predicate property is present, then every row is considered a match. The predicate may be pushed into the storage engine. This means that the test is done by the storage engine, after loading the page into the buffer pool but before returning it to the operator. This optimization is not shown in the flowchart above. Whether or not a predicate is pushed depends on the complexity, and is not visible in the execution plan, except when a Bitmap filter is applied. In that case only, when the “probe” internal function used to test the bitmap is enriched with the “IN ROW” parameter, the bitmap probe is pushed into the storage engine. If not, then the probing is done within the operator.
Table Scan and concurrency
As explained above, if a row in a heap table was ever updated and had to move to accommodate length of the new data, it is stored as a combination of a forwarding pointer in the original location and a forwarded row (with back pointer) in the current location. The IAM scan will of course encounter both. In order to have the row once in the results, one might think that Microsoft could have chosen to return the row when the IAM scan encounters the forwarded row, instead of returning it on encountering the forwarding pointer. However, this would introduce a serious risk of skipping rows or returning duplicate rows if a Table Scan operates while concurrent updates are in progress.
The scenarios where a duplicate row would be returned are when a row that is still in its original location is updated and needs to be forwarded, this happens after the scan has processed the original location of the row, but before it processes the new location of the row. Another scenario would be when a row that was already forwarded is updated and needs to move to another location, and that other location has not yet been processed by the scan but the old forwarded location was.
The scenarios where a row would be omitted from the results of the Table Scan would be when a row that is still in its original location is updated and needs to be forwarded, this happens before the scan processes the original location of the row, but the new location of the row is on a page that was already processed. Another scenario would be when a row that was already forwarded is updated and needs to move to another location, the old location is on a page that still has to be processed by the Table Scan, but it is moved to a page that was already processed before the scan gets there.
When a Table Scan operates under readuncommitted isolation level (which includes the NOLOCK hint), or when concurrent updates are impossible (due to either a table level lock or the table being on a read only filegroup), the Table Scan could choose to skip forwarding pointers and process forwarded rows instead. Under readuncommitted isolation level that could still return incorrect data, but the isolation level allows for it. When no concurrent updates are possible, then there is no risk of incorrect results due to forwarded rows moving. However, Microsoft have chosen not to implement this extra logic. Regardless of isolation level and risk of concurrent updates, the Table Scan will always skip forwarded rows and follow forwarding pointers as the IAM scan encounters them.
Specifically under readuncommitted isolation level, there is a (very small) chance that a concurrent update causes a forwarded row to move just at the same time as the Table Scan processes the forwarding pointer in the original location. In this case, a race condition might cause a run-time error, unless Microsoft protects the affected pages with latches during the time it takes to move the forwarded row to its new location and update the forwarding pointer in the original location. Since I have never heard of a case of a readuncommitted Table Scan causing a run-time error under these circumstances, I suspect that these latches are indeed used.
Table Scan on a memory-optimized table
The description above applies when a Table Scan targets a rowstore table that has no clustered index (a so-called heap table). However, a Table Scan can also target a memory-optimized table. That changes the access method.
The data of a memory-optimized table is stored in a structure that is called “varheap”. The internal structure of varheaps is not documented. Based on my research, I have found out that a varheap consists of one or more memory blocks, each 64 MB in size (on the systems where I checked it, at the time I checked it – since this is undocumented, it is subject to change without notice, and it might differ between hardware architectures). These memory blocks are connected using pointer chains.
A Table Scan on a memory-optimized table will start at the first memory block, read and return the rows in there (if they are valid for the current transaction, and if the Predicate if any is matched). Once it reaches the end of the memory block, Table Scan follows the pointer to the next memory block, and repeats the process.
For a more in-depth discussion of this varheap structure, see this blog post.
Operator properties
The properties below are specific to the Table Scan operator, or have a specific meaning when appearing on it. For all other properties, see Common properties. Properties that are included on the Common properties page but are also included below for their specific meaning for the Table Scan operator are marked with a *.
(Note that most of these properties are exactly the same as for the Index Scan operator; they are repeated here for ease of use).
| Property name | Description |
|---|---|
| Actual Number of Rows Read | This is the number of rows that was read by the operator as it was navigating the heap. In a parallel execution plan, this property shows a breakdown of rows on each individual thread. The difference between this property and the Actual Number of Rows property represents the number of rows that was read but not returned due to the Predicate property, or because the parent operator stopped asking for more rows before the end of data was reached. Note that this property may report incorrect values when the Predicate property contains a PROBE. Only available in execution plan plus run-time statistics. When the actual number of rows read is equal to zero, this property is omitted. |
| Actual Partition Count | This is the number of partitions within a partitioned table that were accessed at least once during execution. Only available in execution plan plus run-time statistics and only when the Partitioned property is included and set to True. |
| Actual Partitions Accessed | This property lists all the partitions within a partitioned table that were accessed at least once during execution. In the execution plan XML, this is actually stored as one or more PartitionRange elements, each with a Start and End property. In tools such as SSMS, this is displayed as a semicolon separated list of ranges, where every single-partition range is displayed as a number instead. So for instance, “2-4;7;10-11” represents that partitions 2, 3, 4, 7, 10, and 11 were accessed at least once. Only available in execution plan plus run-time statistics and only when the Partitioned property is included and set to True. |
| Defined Values * | For a Table Scan, this property lists the columns read from the index and returned to the calling operator. It is therefore the same as the Output List property. |
| Estimated Number of Rows to be Read | This is an estimate of the number of rows that will be read by the operator as it is scanning the heap. In most cases this will be equal to the estimated total number of rows in the table, except when there are other operators in the execution plan that can result in this operator not being called anymore before the end of the data is reached. The difference between this property and the Estimated Number of Rows or Estimated Number of Rows Per Execution property represents the number of rows that is estimated to be read but not returned due to the Predicate property. Note that this property is computed without taking the effect of a row goal (if any) into account. If the EstimateRowsWithoutRowGoal property is present, then you need to compare that, instead of the Estimated Number of Rows, to the Estimated Number of Rows to be Read property for a proper assessment of the estimated selectivity of the Predicate. |
| Forced Index | This property is set to true if the use of the heap was forced through an index hint in the query. |
| ForceScan | This property is set to true if the query used a FORCESCAN hint to force the use of a scan operator even if the optimizer would rather use a seek operator. |
| NoExpandHint | This property is set to true if the NOEXPAND hint was used in the query to force the optimizer to use indexes on an indexed view. |
| Object | This property names the table that is being scanned by the Table Scan operator, using three part naming (database, schema, table) and optionally followed by a table alias. The subproperties of the Object property represent the alias and the three name parts separately, but also includes some additional properties:
|
| Ordered | This property is always set to False for a Table Scan. |
| Partitioned | This property is present and set to True when the index read by the Table Scan is a partitioned index. |
| Predicate | When present, this property defines a logical test to be applied to all rows that are read by the Table Scan. Only rows for which the predicate evaluates to True are returned. When possible, the Table Scan operator will push this predicate into the storage engine to prevent extra roundtrips between the operator and the storage engine. Note that a Predicate on a Table Scan does not reduce the amount of rows that is touched by the operator. The difference between the Actual Number of Rows (for All Executions) and the Number of Rows Read property (or their estimated counterparts) shows how many rows were read but not returned. This can be used to gauge how useful an index would be that supports the predicate. |
| Seek Predicates | The Seek Predicates property can only appear on a Table Scan operator if the Object scanned is a partitioned table, and it only supports equality or inequality conditions on an internal column called PtnIdnnnn, where nnnn is a 4-digit number that is unique within the execution plan. This implements partition elimination, where only the indicated partition(s) of the table are scanned. |
| Table Cardinality | This property shows the number of rows in the table when the plan was last compiled. |
Implicit properties
This table below lists the behavior of the implicit properties for the Table Scan operator.
| Property name | Description |
|---|---|
| Batch Mode enabled | The Table Scan operator supports both row mode and batch mode execution. |
| Blocking | The Table Scan operator is non-blocking. |
| Memory requirement | The Table Scan operator does not have any special memory requirement. |
| Order-preserving | For a rowstore (heap) table, the Table Scan operator returns data in the order of the pages in the IAM. For a memory-optimized table, the order will be based on the index used, which is selected at run-time. In both cases, the order of rows is considered to be an unreliable order for the purpose of order in the execution plan. |
| Parallelism aware | When the Table Scan operator is running in a parallel section of an execution plan, it uses the “Parallel Page Supplier” method described here. |
| Segment aware | The Table Scan operator is not segment aware. |
Change log
(Does not include minor changes, such as adding, removing, or changing hyperlinks, correcting typos, and rephrasing for clarity).
June 15, 2020: Added.
September 20, 2020: Added the Seek Predicates property, that can be used on these operators if the object scanned is partitioned; added a warning about potentially incorrect information in the Number of Rows Read property when a PROBE Predicate is used; added information on Table Scan on a memory-optimized table.
April 12, 2021: Added the Partitioned property, that is present and set on these operators if they target a partitioned index or heap.
May 9, 2021: Added an important note about how the Estimated Number of Rows to be Read property interacts with a row goal.
November 2, 2023: Added subproperties for the graph worktables that are used in SHORTEST_PATH evaluations.
April 14, 2024: Added the Actual Partition Count and Actual Partitions Accessed properties.
January 7, 2026: Renamed Number of Rows Read property to Actual Number of Rows Read property, and slightly modified its description.
May 12, 2026: Corrected the description for memory optimized nonclustered hash indexes.