Collapse
Introduction
The Collapse operator is typically used to optimize update processing, usually in combination with Split and Sort operators. This operator combines combinations of rows that represent a delete and an insert for the same key value (or set of key values in the case of a multi-column key) into a single row that represents an update. Other rows are passed unchanged.
In order for the operator to work correctly, the input data needs to be sorted by the key column(s), and within that by operation (delete before insert).
It is currently not known whether this operator has any built-in logic to handle multiple inserts and/or deletes for the same key value. All descriptions on this page are based on the assumption that the input stream does not handle such duplicates – in other words, I assume that this operator expects as most one delete and one insert for each distinct key value.
Visual appearance in execution plans
Depending on the tool being used, a Collapse operator is displayed in a graphical execution plan as shown below:
|
SSMS and VS Code |
Legacy SSMS |
Plan Explorer |
Paste The Plan |
Algorithm
The basic algorithm for the Collapse operator is as shown below:
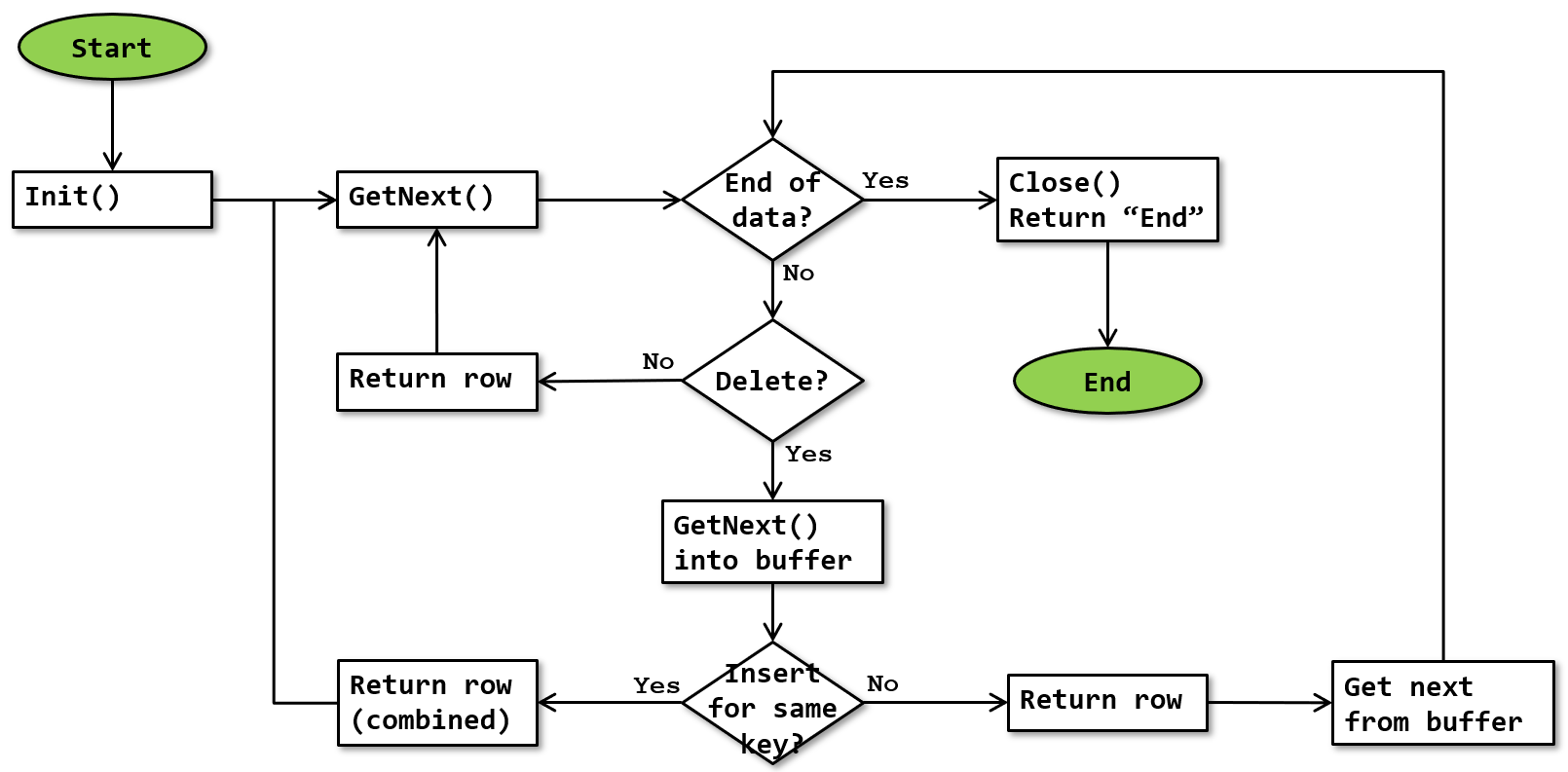 This flowchart is drawn on the aforementioned assumption that at most one delete and one insert per distinct key value can be in the input stream.
This flowchart is drawn on the aforementioned assumption that at most one delete and one insert per distinct key value can be in the input stream.
Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called.
Action Column
The Collapse operator is one of a few operators that support a so-called “action column” to clarify what type of modification a row represents. In the case of the Collapse operator, the action column is always present in both the input and the output data, with the same name in both.
The known values and their meaning for the action column (for any operator, not just for Collapse) are:
- 1: Update
- 3: Delete
- 4: Insert
It is currently unknown whether there are more possible values. Based on what the Collapse operator does, its input should be expected to only have values 3 and 4 (delete and insert).
The Collapse operator does not have a property that explicitly specifies which of the columns in its input and output represent the action column to use for its operation. This is probably inferred from the name (“Actnnnn” or “Actionnnnn” where nnnn is a four-digit number)
Read-ahead buffer
The only way to determine whether the “current” row has to be combined with the “next” row is by reading the next row. And this has to be done before the current row is fully processed.
This means that the Collapse operator, unlike most other operators, occasionally holds two rows in its working memory. The current row is always available in the normal working area, but when needed the next row can already be read in a temporary holding area, the “read-ahead buffer”.
The operator requires some extra memory for this read-ahead buffer, but because it is never more than a single row this extra memory is still considered part of the normal operator working memory; it is not included in the memory grant computation for the execution plan.
Delete? / Insert for same key?
The Collapse operator only needs to do something special for combinations of subsequent rows in the input stream where the first row represents a delete (Action Column = 3) and the second row represents an insert (Action Column = 4) for the same key value (determined by the Group By property). Note that in this specific case the test for the same key value is based on distinctness, not on equality; this means that nulls in the key column(s) will not be considered to be different from each other.
So for each row read, the operator first looks at the Action Column to verify whether it is a delete; if not then the row is simply returned unchanged and the next row is read. If the Action Column of a row does indicate a delete, then the next row from the input is read into the read-ahead buffer, so that the operator can verify whether it is an insert for the same key value (and hence the two rows need to be combined), or an delete or insert for a different key value.
GetNext() into buffer / Get next from buffer
When the operator encounters a row that represents a delete and may potentially need to be combined with the next row (if it is an insert for the same key value), it reads the next row by doing a regular call to its child’s GetNext() method, but stores the returned row in a special memory area called the read-ahead buffer, instead of in the normal working area. It can then look at the values in the read-ahead buffer to determine whether or not the rows can be combined. If they do, then the operator returns a single row using the combined values from the current row and the row in the read-ahead buffer.
If the row in the read-ahead buffer cannot be combined with the current row, then the operator will simply return the current row unchanged and then move the data from the read-ahead buffer to the current row data, then resume processing for that row.
Return row (combined)
When the input row represents a delete and the next row (in the read-ahead buffer) represents an insert for the same key value, then a single row is returned that represents an update. Columns in the output row are determined as follows:
- The action column is always set to 1 (update).
- All key columns in the Output List are either retained from the current row, or copied from the corresponding data in the read-ahead buffer. Since these have the same value in both, there is no way to tell which version is used, and there would be no difference anyway.
- All non-key columns in the Output List are copied from the corresponding data in the read-ahead buffer. These are the inserted values.
The result of the above is that a delete / insert combination for the same key value is combined to be an update for that key value, passing only the new values. The values from the deleted row (which are now conceptually the pre-update values) are not available in the output of the Collapse operator. If the execution plan needs these later, it will typically use a Table Spool operator or other method to be able to reproduce these values later.
Operator properties
The properties below are specific to the Collapse operator, or have a specific meaning when appearing on it. For all other properties, see Common properties. Properties that are included on the Common properties page but are also included below for their specific meaning for the Collapse operator are marked with a *.
| Property name | Description |
|---|---|
| Group By | The name of the column, or set of columns, that represent the key for the collapse operator. Any pair of rows that represent a delete and an insert and have the same value in all Group By columns will be replaced with a single row that represents an update. |
| Output List * | As described in the main text, the Output List of both the Collapse operator and its child operator should include a column named Actnnnn or Actionnnnn (where nnnn is a four-digit number) that is used to signal whether rows represent a delete, an insert, or an update. |
Implicit properties
This table below lists the behavior of the implicit properties for the Collapse operator.
| Property name | Description |
|---|---|
| Batch Mode enabled | The Collapse operator supports row mode execution only. |
| Blocking | The Collapse operator is non-blocking. |
| Memory requirement | The Collapse operator uses a small bit of extra memory for the read-ahead buffer, but this is still considered part of the normal operator memory and not included in the execution plan’s memory grant. |
| Order-preserving | The Collapse operator is fully order-preserving. |
| Parallelism aware | The Collapse operator is not parallelism aware. |
| Segment aware | The Collapse operator is not segment aware. |
Change log
(Does not include minor changes, such as adding, removing, or changing hyperlinks, correcting typos, and rephrasing for clarity).
March 8, 2019: Added.