Index Insert
Introduction
The Index Insert operator is used to insert rows in a nonclustered index. The rows to be inserted are produced by the operator’s child subtree, and returned to its parent. Index Insert operators are typically used in wide update plans only; when the optimizer chooses to use a narrow update plan, it will modify all nonclustered indexes in the Table Insert or Clustered Index Insert operator.
An Index Insert operator that targets a columnstore index is represented in the execution plan XML as a regular Index Insert operator, with the Storage subproperty of the Object property set to ‘ColumnStore’. But SSMS (and most other tools) then represent this operator as a Columnstore Index Insert operator in the graphical execution plan. To match the representation of the execution plan that most people use, I’ll focus the descriptions below on how Index Insert operates when the Storage property is ‘RowStore’, and call out relevant differences on the separate Columnstore Index Insert page.
It is, as far as currently known, not possible for an Index Insert operator to target a memory-optimized index. All execution plans for inserting data in a memory-optimized table, use a narrow plan, with just a single Table Insert operator to modify the data for all indexes, per row.
Visual appearance in execution plans
Depending on the tool being used, an Index Insert operator with the Storage property not equal to ColumnStore is displayed in a graphical execution plan as shown below:
|
SSMS and ADS |
Legacy SSMS |
Plan Explorer |
Paste The Plan |
Algorithm
The basic algorithm for the Index Insert operator is as shown below:
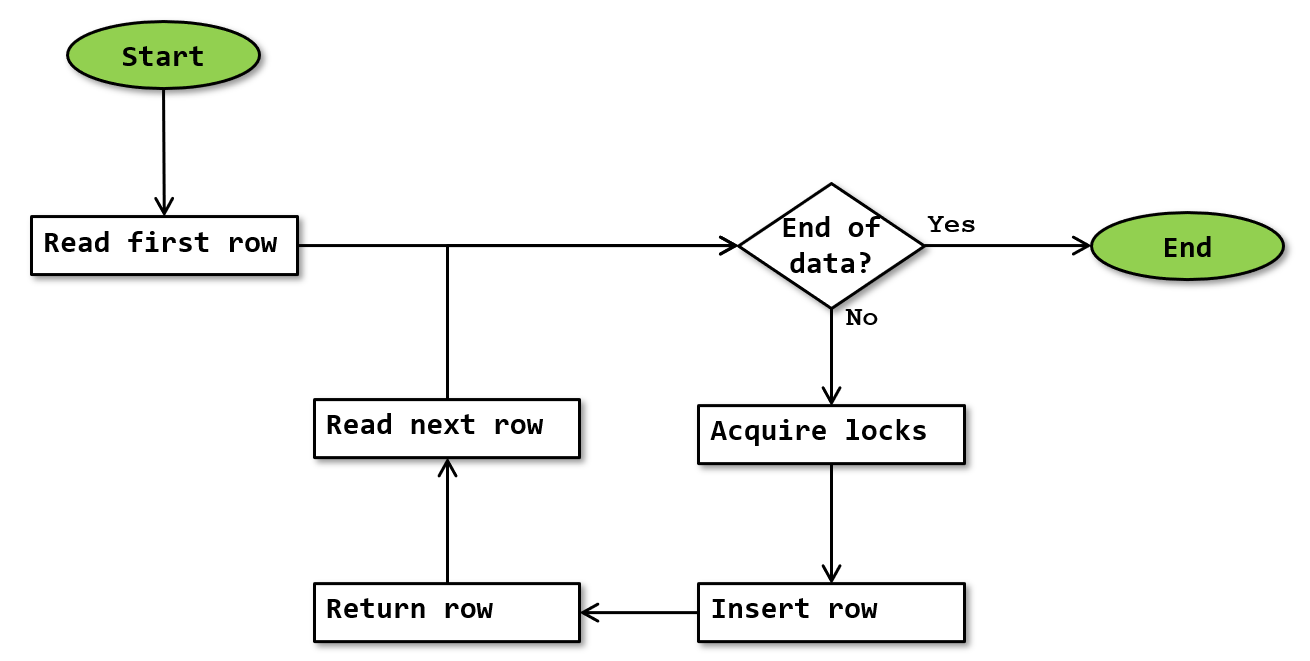 Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called.
Note that this flowchart is a simplification. It doesn’t show that execution stops whenever a row is returned, and resumes where it was upon next being called.
Acquire locks
Before inserting data, the Index Insert operator will always acquire the necessary locks (or verify that it already has them). Which locks exactly are taken depends on the isolation level of the transaction, but it is never possible to completely eliminate all locking on data modifications.
This operator does not release the locks it takes, nor does any other operator in the same execution plan. Locks for data modifications are always held until the end of the transaction.
A full discussion of locking strategies used for the various transaction isolation levels is beyond the scope of this website.
Insert row
The Index Insert operator doesn’t do any constraint checking. The optimizer ensures that foreign key and check constraints are checked if the new data might violate them. Primary keys and unique constraints are not explicitly checked; SQL Server creates a unique index for each such constraint, and the storage engine ensures an error is raised as soon as data is written to the index that would cause a duplicate entry.
Return row
Like any operator, Index Insert is invoked by calling its GetNext() method. And like any other operator, it responds my returning a row, with the columns listed in the Output List property. Most of the time these will be some or all of the values just inserted, although additional columns from the input that are not inserted into the index may also be passed on.
These output rows can be used by parent operators for additional logic, such as constraint checking or propagating the changes to other indexes, indexed views, etc.
Operator properties
The properties below are specific to the Index Insert operator, or have a specific meaning when appearing on it. For all other properties, see Common properties. Properties that are included on the Common properties page but are also included below for their specific meaning for the Index Insert operator are marked with a *.
| Property name | Description |
|---|---|
| DMLRequestSort | When set to true, the insert operation might qualify for minimal logging if additional conditions apply. Details of those additional conditions and the requirements for DMLRequestSort to be true can be found here. |
| Object | The index that the Index Insert operator will insert rows to, using four part naming (database, schema, table, index). The subproperties of the Object property represent the four name parts separately, but also include these additional properties:
|
| Partitioned | This property is present and set to True when the target of the Index Insert is a partitioned index. |
| Predicate | Maps columns from the input stream to the columns in the index indicated by the Object property, or sets these columns to hardcoded values or variables from the query text. |
| WithUnorderedPrefetch | This property is present (and set to true) when prefetching is requested and order doesn’t need to be preserved. Exact details of prefetching in the context of an Index Insert operator are unknown at this time. The assumed effect of prefetching is that the operator issues an asynchronous request to the storage system to insert each row, then immediately continues with the next. Rows are returned to the parent operator in the order in which the storage system completes the requests, which might be different from the order in which the rows are read by the operator. When this property is not present, no prefetching is used. |
Implicit properties
This table below lists the behavior of the implicit properties for the Index Insert operator.
| Property name | Description |
|---|---|
| Batch Mode enabled | The Index Insert operator supports row mode execution only. |
| Blocking | The Index Insert operator is non-blocking. |
| Memory requirement | The Index Insert operator does not have any special memory requirement. |
| Order-preserving | The Index Insert operator is fully order-preserving when no prefetching is used. When the WithUnorderedPrefetch property is present and true, then the Index Insert operator is not order-preserving. |
| Parallelism aware | The Index Insert operator does not support parallelism. It can only be used in a serial plan, or in a serial section of a parallel plan. |
| Segment aware | The Index Insert operator is not segment aware. |
Change log
(Does not include minor changes, such as adding, removing, or changing hyperlinks, correcting typos, and rephrasing for clarity).
May 30, 2021: Added.
April 1, 2022: Added additional information about the IndexKind subproperty of the Object property, and about the Partitioned property.
December 12, 2023: Added additional information about the OnlineInbuildIndex subproperty of the Object property.