Storage structures 6 – JSON indexes
No Comments
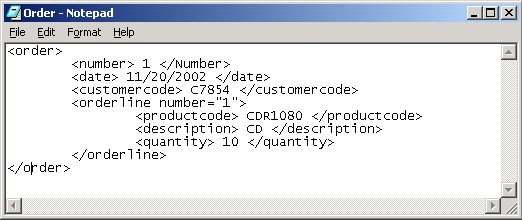
It’s time to continue the series on internals of storage structures. I already covered the more standard storage types in the parts about on-disk rowstore, columnstore indexes, memory-optimized storage, and memory-optimized columnstores, and in the last episode of this series I started to cover specialized storage structures by looking at XML indexes. Microsoft introduced limited JSON support in SQL Server 2016. However, it took until SQL Server 2025 before the native json data type and JSON indexes were introduced. So let’s look at how these work under the cover. I have so far not played with JSON data. So I…
Read More