In part 30 of the plansplaining series, we’ll continue our discussion of cursor processing. I recommend first reading the previous post, where I explain all the necessary basics.
Sample query
Throughout the series, I will keep using the same sample query, that grabs some sales and product data for sales of more than 10 units, within a specified range of sales orders.
SELECT soh.SalesOrderID,
soh.OrderDate,
sod.SalesOrderDetailID,
sod.OrderQty,
sod.ProductID,
p.ProductID,
p.Name
FROM Sales.SalesOrderHeader AS soh
INNER JOIN Sales.SalesOrderDetail AS sod
ON sod.SalesOrderID = soh.SalesOrderID
INNER JOIN Production.Product AS p
ON p.ProductID = sod.ProductID
WHERE soh.SalesOrderID BETWEEN 69401 AND 69410
AND sod.OrderQty >= 10
ORDER BY p.ProductID;
When I execute this query outside of any cursor, the execution plan is rather basic:

(Click on the picture to enlarge)
This execution plan is fairly simple, and can be explained in just a few sentences. Following the data, we start at Clustered Index Seek #3, which finds the SalesOrderHeader rows with a SalesOrderID in the requested range. Nested Loops #2 then uses its Outer References property to push the SalesOrderID into Clustered Index Seek #4, which reads all the SalesOrderDetail rows that belong to those sales orders.
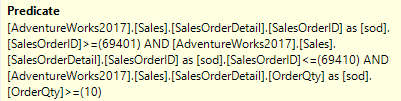 The Predicate property of this Clustered Index Seek applies the pushed down filter on the OrderQty column. Because of that extra filter, only 12 rows of the 163 that were read are returned to the Nested Loops. The Predicate property also repeats the SalesOrderID range. I don’t know why, it is fully redundant. But it doesn’t exactly hurt either. The few CPU cycles to apply this test really do not cause any measurable delay.
The Predicate property of this Clustered Index Seek applies the pushed down filter on the OrderQty column. Because of that extra filter, only 12 rows of the 163 that were read are returned to the Nested Loops. The Predicate property also repeats the SalesOrderID range. I don’t know why, it is fully redundant. But it doesn’t exactly hurt either. The few CPU cycles to apply this test really do not cause any measurable delay.
 The placement of Sort #1 might be slightly surprising. The query requests the data to be sorted by the ProductID column from the Product table (p.ProductID). But the execution plan sorts data returned by Nested Loops #2, which has only columns from SalesOrderHeader and SalesOrderDetail. And indeed, the properties of this Sort reveal that the data is not ordered by the ProductID from the Product table, but by the ProductID column from the SalesOrderDetail table instead. The explanation is fairly simple, though. The query optimizer uses the join predicate p.ProductID = sod.ProductID to know that sorting by the latter is equivalent to sorting by the former. By sorting the data before adding the extra columns from the Product table, the average row size is slightly smaller (29 bytes instead of 87 bytes), which saves on the size of the data to be sorted, and hence on the Memory Grant for the query.
The placement of Sort #1 might be slightly surprising. The query requests the data to be sorted by the ProductID column from the Product table (p.ProductID). But the execution plan sorts data returned by Nested Loops #2, which has only columns from SalesOrderHeader and SalesOrderDetail. And indeed, the properties of this Sort reveal that the data is not ordered by the ProductID from the Product table, but by the ProductID column from the SalesOrderDetail table instead. The explanation is fairly simple, though. The query optimizer uses the join predicate p.ProductID = sod.ProductID to know that sorting by the latter is equivalent to sorting by the former. By sorting the data before adding the extra columns from the Product table, the average row size is slightly smaller (29 bytes instead of 87 bytes), which saves on the size of the data to be sorted, and hence on the Memory Grant for the query.
The last steps of the execution plan, Nested Loops #0 and Clustered Index Seek #5, are really not surprising in any way. These simply are used to fetch the requested data from the Product table, based on the ProductID column. Note that this Nested Loops has its Optimized property set to False, and does not include the With Unordered Prefetch properties. This is required to preserve the order of the data that was just put in the right order by Sort #1.
Static cursor
Now that we have seen, and understand, the execution plan for the sample query, let’s include this same query in a static cursor, and check on the execution plans. Here is the code I used:
DECLARE MyCursor CURSOR
GLOBAL
FORWARD_ONLY
STATIC
READ_ONLY
TYPE_WARNING
FOR
SELECT soh.SalesOrderID,
soh.OrderDate,
sod.SalesOrderDetailID,
sod.OrderQty,
sod.ProductID,
p.ProductID,
p.Name
FROM Sales.SalesOrderHeader AS soh
INNER JOIN Sales.SalesOrderDetail AS sod
ON sod.SalesOrderID = soh.SalesOrderID
INNER JOIN Production.Product AS p
ON p.ProductID = sod.ProductID
WHERE soh.SalesOrderID BETWEEN 69401 AND 69410
AND sod.OrderQty >= 10
ORDER BY p.ProductID;
OPEN MyCursor;
FETCH NEXT FROM MyCursor;
FETCH NEXT FROM MyCursor;
CLOSE MyCursor;
DEALLOCATE MyCursor;
I have used the GLOBAL scope option, so that it is possible to step through the code one statement at a time. This option does not affect the execution plans used. The FORWARD_ONLY and READ_ONLY options are probably the most commonly used options with cursors, especially with static cursors. We will briefly look at the effect of other options for read direction and concurrency at the end of this post.
The execution plan
As explained in the previous post, the execution plans are presented in different ways depending on whether you only request the execution plan, or whether you actually execute the code while requesting the execution plan with run-time statistics to be returned. For this post, I will look at the execution plan only, because it has a few extra “pseudo” operators that are not included in the execution plan with run-time statistics. When using execution plan only, the plans for the OPEN, FETCH, CLOSE, and DEALLOCATE statements are not in any way interesting, so I will only show the execution plan for the DECLARE CURSOR statement:

(Click on the picture to enlarge)
Let’s start from the left. The top left pseudo operator is called “Snapshot” in this case. A rather surprising name. In the next parts of this series, you will see that all other cursor types (dynamic, keyset, and fast forward) all have a top left operator that matches their name, so I would have expected the name “Static” here. But instead, it is called “Snapshot”. Truth be told, “Snapshot” does reflect what a static cursor does, as will become clear during the rest of this post.
Population Query
The top part of the execution plan shows the so-called “Population Query”, which will actually be executed when the OPEN CURSOR runs. On the far right of this subtree, we see an exact copy of the execution plan we got when just running the query outside of a cursor. So this part of the execution plan produces all the results for the cursor. Even the rows that we will eventually never read, because the code just does two FETCH statements and then closes the cursor again.
To the left of that already familiar fragment, we see a few extra operators. Following the data (right to left), we first see a Segment operator. Its Group By property is empty, which means that this operator is only included as a technical requirement for the Sequence Project to the left of it. The Defined Values property of this operator shows that this computes a row_number, and since the Segment didn’t create any actual segments, it is equivalent to a ROW_NUMBER() without a PARTITION BY specification. (See this post for a longer explanation of this pattern).
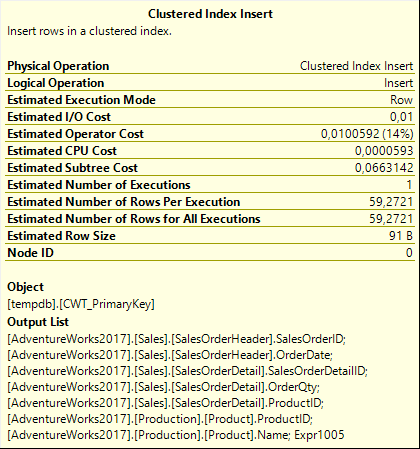 Sequence Project then returns all columns from the SELECT list of the cursor, plus the just computed row number, to its parent, a Clustered Index Insert. The properties of this operator show that the target is a weirdly named object in tempdb. We expect a four-part name here (database, schema, table, and index name). But here, we see only two parts: tempdb.CWT_PrimaryKey. Which is of course very strange. And if you try to query this object, you’ll find that you can’t. SQL Server claims there is no object named tempdb.CWT_PrimaryKey.
Sequence Project then returns all columns from the SELECT list of the cursor, plus the just computed row number, to its parent, a Clustered Index Insert. The properties of this operator show that the target is a weirdly named object in tempdb. We expect a four-part name here (database, schema, table, and index name). But here, we see only two parts: tempdb.CWT_PrimaryKey. Which is of course very strange. And if you try to query this object, you’ll find that you can’t. SQL Server claims there is no object named tempdb.CWT_PrimaryKey.
 The Predicate property, which you can find in the full properties list, maps the columns from the input to columns in the target table. There is no big surprise here. It lists exactly the eight columns that are returned by Sequence Project to Clustered Index Insert: the seven columns requested by the cursor, plus the Expr1005 column with the computed row number. However, these columns have different names in the table. The seven output columns are named COLUMN0 through COLUMN6, and the row number is stored in a column named ROWID.
The Predicate property, which you can find in the full properties list, maps the columns from the input to columns in the target table. There is no big surprise here. It lists exactly the eight columns that are returned by Sequence Project to Clustered Index Insert: the seven columns requested by the cursor, plus the Expr1005 column with the computed row number. However, these columns have different names in the table. The seven output columns are named COLUMN0 through COLUMN6, and the row number is stored in a column named ROWID.
Putting this all together, we see that, when a static cursor is opened, SQL Server executes the entire query, collects all the results, computes an additional row number for each row, and stores those results in an internal and weirdly named temporary table. Although not visible from the execution plan, my assumption is that the row number column that is computed in Expr1005 is used as the key column for the clustered index.
And this explains why the top left operator of this execution plan is not called “Static”, but “Snapshot”. Because that is exactly what the Population Query part of this plan does. It runs a query to populate a rather unconventionally named internal object in tempdb with a full snapshot of all data that is visible through the cursor.
Fetch Query
 The Fetch Query, which is used whenever a FETCH statement is executed, is a lot simpler for this cursor. It is just a single Clustered Index Seek, and its properties show that it reads a single row from the internal temporary table that was created and filled with a snapshot of the data in the Population Query.
The Fetch Query, which is used whenever a FETCH statement is executed, is a lot simpler for this cursor. It is just a single Clustered Index Seek, and its properties show that it reads a single row from the internal temporary table that was created and filled with a snapshot of the data in the Population Query.
The columns returned are all eight columns that were inserted in the temporary table. This is slightly surprising. After all, the Fetch Query pseudo-operator represents the client, but we do not get to see the computed row numbers in the ROWID column when we execute the FETCH statements. So apparently, this last column is somehow removed from the result set before it is returned to the client, even though that is not visible in the execution plan.
The Seek Predicates property determines which row to return. It is a filter on the ROWID column, which confirms that this is indeed the clustered index key for the internal temporary table. The query then only returns the row where this ROWID column is equal to the current value of the undocumented internal scalar function FETCH_RANGE(0). In the provided sample, that uses a FORWARD_ONLY cursor and hence can only use FETCH NEXT, the value of FETCH_RANGE(0) will be 1 for the first FETCH statement, 2 for the second, and so on.
This is the entire reason why the Population Query had to add that extra column with a row number to the results, before storing it in a temporary table: so that it can use the position of the row in the result set of the entire cursor to fetch the correct row from the saved snapshot.
Read direction and concurrency
The description above is for the most commonly used options for read direction and concurrency for a static cursor: FORWARD_ONLY and READ_ONLY. But the effect of changing these options is really very minor, as you can see when you look at the execution plans for this batch:
DECLARE MyCursor CURSOR
GLOBAL
SCROLL -- Changed
STATIC
OPTIMISTIC -- Changed
TYPE_WARNING
FOR
SELECT soh.SalesOrderID,
soh.OrderDate,
sod.SalesOrderDetailID,
sod.OrderQty,
sod.ProductID,
p.ProductID,
p.Name
FROM Sales.SalesOrderHeader AS soh
INNER JOIN Sales.SalesOrderDetail AS sod
ON sod.SalesOrderID = soh.SalesOrderID
INNER JOIN Production.Product AS p
ON p.ProductID = sod.ProductID
WHERE soh.SalesOrderID BETWEEN 69401 AND 69410
AND sod.OrderQty >= 10
ORDER BY p.ProductID;
OPEN MyCursor;
FETCH NEXT FROM MyCursor;
FETCH NEXT FROM MyCursor;
CLOSE MyCursor;
DEALLOCATE MyCursor;
Most of this query batch is unchanged. I only changed the read direction to SCROLL, and the concurrency option to OPTIMISTIC.
 If you look at the execution plans, you will see … no differences at all! However, there are actually some differences there. Or, rather, there is one difference there. In order to find it, you’ll have to look at the full properties list of the Snapshot pseudo-operator, as shown in the screenshot on the right.
If you look at the execution plans, you will see … no differences at all! However, there are actually some differences there. Or, rather, there is one difference there. In order to find it, you’ll have to look at the full properties list of the Snapshot pseudo-operator, as shown in the screenshot on the right.
Near the bottom, you see the Forward Only property, which in this screenshot is set to False. If you change the code back to use FORWARD_ONLY instead of SCROLL as the read direction option, then this property will change to True. And that is really the only change you will find between the execution plans for the original code and the modified code.
Note that you will not see any differences in the Fetch Query plan. Not even when you use any of the other FETCH options (FETCH FIRST, FETCH LAST, FETCH PRIOR, FETCH ABSOLUTE n, or FETCH RELATIVE n). The value of FETCH_RANGE(0) will be set to the appropriate value by SQL Server before the FETCH query is executed, but this is not exposed in any way in the execution plans.
“But what about the concurrency option?”, I hear you think. Yeah, there is that. Check again in the screenshot with the properties of the Snapshot pseudo-operator above. Near the top, there is the Cursor Concurrency property. And it is set to … ReadOnly! Which surprised me. I double checked the official documentation (*), and while it does mention that SCROLL_LOCKS is not allowed for a STATIC cursor, it has no such provision on OPTIMISTIC. I also checked the Messages tab after running my code, but there was no warning that the cursor type was changed. However, a quick test I ran confirmed that, despite all this, the OPTIMISTIC option is in fact fully ignored for a STATIC cursor. It is always READ_ONLY, and any attempt to update or delete rows with the WHERE CURRENT OF MyCursor option will fail.
So we will have to look at the execution plans for updateable cursors, as well as for the actual updates for those cursors later, when we look at cursor types that actually allow this.
(*) Note that I have submitted a pull request to get the DECLARE CURSOR documentation updated, so by the time you read this, this documentation bug might already be fixed, and the limitation that a STATIC cursor can only be READ_ONLY is hopefully listed.
Summary
So now we know how a STATIC cursor works. The Population Query, which runs when the cursor is opened, retrieves a complete snapshot of all the data that is at that point in time visible through the cursor, adds a row number to each row, and stores it in tempdb. And every subsequent FETCH statement uses the Fetch Query, which simply uses the requested position in the cursor (passed in through the FETCH_RANGE(0) internal function) to find and return the requested row from that temporary table.
In many cases, a STATIC cursor is the fastest option. But not always. When the result set of a cursor has a billion rows, but your code opens it, fetches the first ten rows, and then closes the cursor again, then choosing STATIC will be dramatic for performance. And you now know why. It will first assemble the entire billion-row result set. Then store it in tempdb. And then, after retrieving only the first ten rows, delete it again. As you will see in the later parts, other cursor options might be more efficient in this case.
However, do not let performance considerations lure you into choosing a cursor type that is incorrect for your application. If you absolutely do not want to see any changes to the underlying data that were committed after the cursor was opened, then you simply need to use STATIC. And if you absolutely do need to see those changes, then you’ll probably have to use DYNAMIC (or perhaps KEYSET).
First make sure that your code returns the expected results. Only worry about performance once that is the case, and never make performance improvements at the expense of (potentially) returning incorrect results!
As always, please let me know if there is any execution plan related topic you want to see explained in a future plansplaining post and I’ll add it to my to-do list!






{kind=link}
{kind=link}
5 Comments. Leave new
May I have probably stupid question about locks? For what part/s of the cursor phases are the shared locks for population query taken? If not only shared locks, what other types of locks? Thanks…
Hey Jiri,
This is an excellent question! And while not directly related to execution plans, the focus of this post, I decided to do some testing to figure this out. Please note that this is based on observation. I could check locks in between statements, and during the OPEN statement (by using a very slow query). But other statements finish so fast that I could not see locks taken during that statement.
I experimented with cursor code without transaction (as in this post) and inside a transaction, at different isolation levels. Here is what I found.
1. When the batch is submitted, then if there is no cached execution plan for the batch, Sch-S locks are taken during compilation.
2. When the OPEN statement executes, locks are taken depending on the transaction isolation level. Only IS locks on the objects for read uncommitted. Read committed adds page level IS locks (and I assume key level S locks but they last too briefly to be seen). Repeatable read adds lasting key level S locks, and serializable changes those to RangeS-S locks. All these locks last until the end of the transaction, or until the end of the statement in case of an implied transaction. (Snapshot and read committed snapshot do not take locks at all).
Somewhat surprisingly, I never saw locks on the temporary table that stores the snapshot. I assume that SQL Server knows that this object can only be accessed by the current SPID and hence does not need to be protected from concurrency problems, so no locking is needed.
3. Consistent with the above, I also saw no locks being used during the FETCH statement. Which makes sense, of course, since it only reads from that temporary table that is exclusive to the connection and hence does not need locks.
My conclusion based on these observations is that a static read only cursor requests all the same locks that a regular query execution would, at the time the OPEN statement runs (which is when the query is actually executed and the results are stored in an internal temporary table). These locks are held just as long as they normally would: until the end of the transaction, or if there is no explicit transaction then until the end of the statement.
Many thanks Hugo. Theory says that under Read Committed isolation level under explicitely invoked transaction S locks should be taken for the duration of the statement. If I interpret your observation correctly while cursor is open inside such transaction S locks are held until the end of it. Which is a difference. I could and would test it for my self because that, if proofed, would be another argument against cursors in comparison with set based attitude.
According to my observation with XE events lock_acquired + lock_released.
For STATIC READ ONLY cursor inside transaction
BEGIN TRAN
DECLARE CURSOR
GLOBAL
FORWARD_ONLY
STATIC
READ_ONLY
OPEN
WHILE
WAITFOR
CLOSE
DEALLOCATE
COMMIT
S lock is acquiered and released during OPEN phase and thats it. Locks are kept just for the statement.
While changing to LOCAL FAST_FORWARD type of cursor short KEY S locks occurs during every FETCH phase.
[…] We’re at part 33 already, and I’m still looking at cursors. After discussing the basics, static cursors, dynamic cursors, and keyset cursors, I will now look at the last of the cursor types: the fast […]