Welcome to part fourteen of the plansplaining series, where I wrap up the mini-series on how simple foreign keys have huge effects on execution plans for data modifications.
We already looked at inserting data in the referencing (child) table, and at deleting data from the referenced (parent) table as well as updates in the child table. We did not and will not look at deleting from the child table or inserting in the parent table: those operations can by default never violate the foreign key constraint, so no additional logic is needed.
So that means there is only one thing left to explore: updating the parent. Perhaps surprisingly, this is actually quite complex, so it warrants an entire post of its own.
Sample tables
I’ll continue to use the same example scenario as in the previous post. Run the code below to create the Suppliers and Products tables, and put in some sample data.
DROP TABLE IF EXISTS dbo.Products, dbo.Suppliers;
GO
CREATE TABLE dbo.Suppliers
(SupplierID int NOT NULL,
SupplierName varchar(50) NOT NULL,
CONSTRAINT PK_Suppliers
PRIMARY KEY (SupplierID));
CREATE TABLE dbo.Products
(ProductCode char(10) NOT NULL,
ProductName varchar(50) NOT NULL,
SupplierID int NULL,
CONSTRAINT PK_Products
PRIMARY KEY (ProductCode),
CONSTRAINT UQ_Products_ProductName
UNIQUE (ProductName),
CONSTRAINT FK_Products_Suppliers
FOREIGN KEY (SupplierID)
REFERENCES dbo.Suppliers (SupplierID),
INDEX ix_Products_SupplierID NONCLUSTERED (SupplierID));
INSERT dbo.Suppliers (SupplierID, SupplierName)
VALUES (1, 'Supplier 1'),
(2, 'Supplier 2'),
(3, 'Supplier 3'),
(4, 'Supplier 4'),
(5, 'Supplier 5');
INSERT dbo.Products (ProductCode, ProductName, SupplierID)
VALUES ('Prod 1', 'Product number 1', 1),
('Prod 2', 'Product number 2', 2),
('Prod 3', 'Product number 3', 3),
('Prod 4', 'Product number 4', 4),
('Prod 5', 'Product number 5', 3),
('Prod 6', 'Product number 6', 1),
('Prod 7', 'Product number 7', NULL),
('Prod 8', 'Product number 8', 2),
('Prod 9', 'Product number 9', 3);
Note that this is the exact same data you would have in your tables is you followed along with the original code and all later modifications in the previous posts. So if you still have that data in your playground database, you can simply continue from there.
Updating the parent
An update to the child is, as foreign key checking goes, considered equivalent to deleting the old row and inserting a new row. I expect that updates to the parent table will be handled the same. Except that, in this case, the insert is safe and requires no testing, but the delete can cause foreign key violations. Let’s check if this is indeed the case!
UPDATE dbo.Suppliers SET SupplierID = SupplierID + 1 WHERE SupplierName LIKE '%5';
Updating a primary key value is generally considered a bad idea. And while every rule has its exceptions, this one has only very few. I won’t go into them, except to say that you should generally avoid this. But it is allowed in SQL, so SQL Server has to support it and ensure it is processed correctly. Here is the execution plan used for the query above:
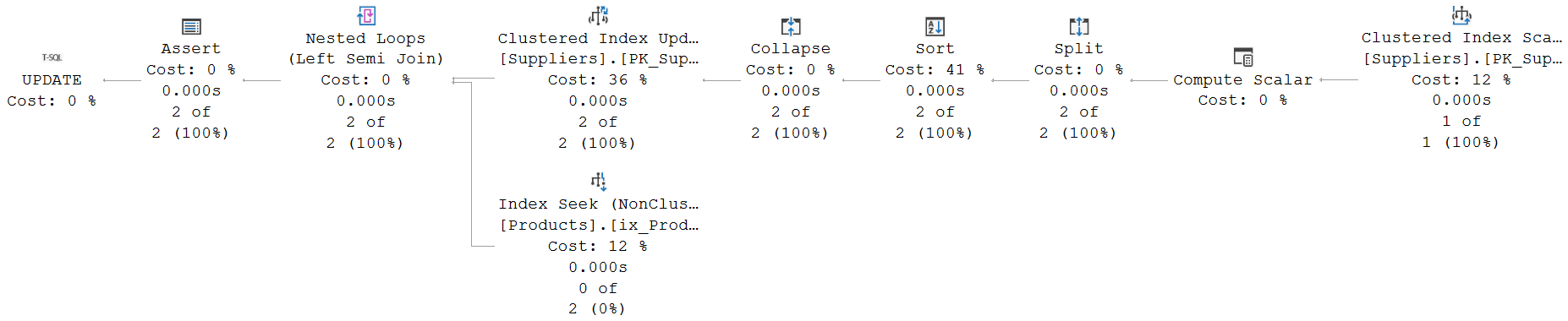
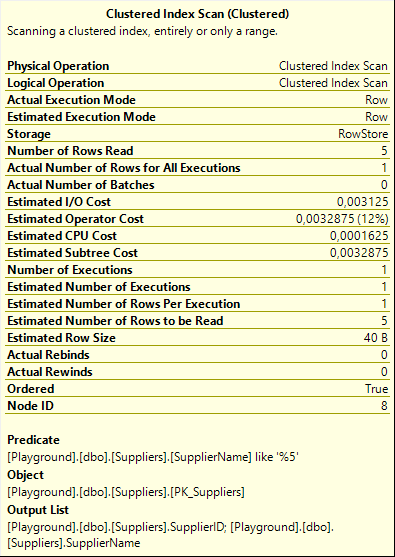 The Clustered Index Scan simply finds and returns the rows that match the WHERE clause and hence need to be updated. It does come with one small surprise: its Output List property includes the SupplierName column. Based on the query, that appears to be superfluous. The SuplierName is not used in the query, and there are also no constraints or other hidden functionality that warrants fetching this column. The reason why this column is read anyway will become clear later.
The Clustered Index Scan simply finds and returns the rows that match the WHERE clause and hence need to be updated. It does come with one small surprise: its Output List property includes the SupplierName column. Based on the query, that appears to be superfluous. The SuplierName is not used in the query, and there are also no constraints or other hidden functionality that warrants fetching this column. The reason why this column is read anyway will become clear later.
Because this update modifies the value of the clustered index key, the execution plan must always contain some form of Halloween protection. In this case, the Sort operator fulfills that role. If you experiment with other update statements, you will sometimes find execution plans that don’t need to sort the data; in those cases a Table Spool operator will be used instead, set to do the Eager Spool logical operation.
Without Halloween protection, there is always the possibility that a row is selected (by the Clustered Index Scan) for the update, then passed to the Clustered Index Update operator, where it is updated. This change might move it to another location in the clustered index, and then the Clustered Index Scan could encounter the same row twice. Depending on the exact text of the update statement, this might cause incorrect results. But even when it doesn’t, it would still do extra work, and possibly cause rows to be processed twice by triggers that might be defined on the table.
Collapse and Split
Between the Clustered Index Scan that finds rows to be deleted and the Clustered Index Update that actually updates them, you’ll find three operators that together form the “Split / Sort / Collapse” pattern. This pattern is typically used to optimize index maintenance for modifications that are estimated to affect a large number of rows. This execution plan is estimated to affect very few rows, though. As can be seen from the numbers in the execution plan, but also from some other plan choices, such as the join type. So why are these operators still here?
The answer is that, in this case, this is required for correctness. We know the exact data in the tables. We can look at the query and realize it’s going to affect a single row only. SQL Server can and does estimate this, but it cannot be sure. There could be multiple matching rows. And if that happens, then it is possible that one update removes a SupplierID value, that another update then re-introduces. That first update by itself would violate the foreign key if the value is still in use; combined with the second update, though, it is fine. And if processed in a different order, the first update would cause a duplicate in the primary key, that the second would solve, but that cannot even be stored as an intermediate state. This is why SQL Server has to use this pattern, to transform the raw updates that follow directly from the updates statement into a set of net changes. A set that will not violate the primary key, and that can be safely used for constraint checking.
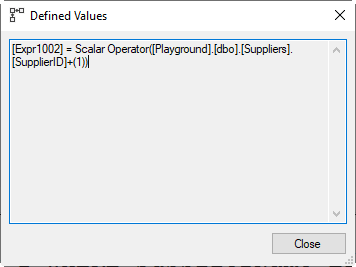 Following the operators right to left, Clustered Index Scan finds rows to be updated and returns them, including not only the SupplierID column but also the SupplierName. The Compute Scalar then adds a third column, Expr1002, which is the new value for SupplierID. The Split operator creates two new rows for each row in its input, one for a delete of the old row (SupplierID and SupplierName passed unchanged, and Action Column Act1011 set to 3 for a delete), and one for an insert of the new row (SupplierID set to Expr1002 from the input, SupplierName passed unchanged, and Act1011 set to 4). The Sort operator orders these rows; if the input contains both an insert and a delete for the same SupplierID they will come directly after each other.
Following the operators right to left, Clustered Index Scan finds rows to be updated and returns them, including not only the SupplierID column but also the SupplierName. The Compute Scalar then adds a third column, Expr1002, which is the new value for SupplierID. The Split operator creates two new rows for each row in its input, one for a delete of the old row (SupplierID and SupplierName passed unchanged, and Action Column Act1011 set to 3 for a delete), and one for an insert of the new row (SupplierID set to Expr1002 from the input, SupplierName passed unchanged, and Act1011 set to 4). The Sort operator orders these rows; if the input contains both an insert and a delete for the same SupplierID they will come directly after each other.
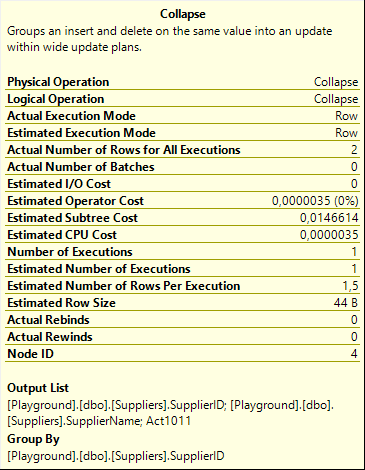 The Collapse operator then reads this sorted input, looking for combinations of a delete and an insert for the same Group By column, SupplierID in this case. It combines these combinations into one new output row, with Action Column Act1011 set to 1 (update). Instead of deleting a row with that SupplierID and SupplierName X and then inserting a new row with the same SupplierID and SupplierName Y, the two changes are collapsed into a single update to change the SupplierName from X to Y for that SupplierID. This is a very different update from what the query asked for, but the final result is the same, and that’s what counts. And because this action requires the SuplierName to be known, we now understand why this column was returned by the Clustered Index Scan.
The Collapse operator then reads this sorted input, looking for combinations of a delete and an insert for the same Group By column, SupplierID in this case. It combines these combinations into one new output row, with Action Column Act1011 set to 1 (update). Instead of deleting a row with that SupplierID and SupplierName X and then inserting a new row with the same SupplierID and SupplierName Y, the two changes are collapsed into a single update to change the SupplierName from X to Y for that SupplierID. This is a very different update from what the query asked for, but the final result is the same, and that’s what counts. And because this action requires the SuplierName to be known, we now understand why this column was returned by the Clustered Index Scan.
Unmatched rows are passed on unchanged. So the net effect of this Split / Sort / Collapse combination is that the set of updates as specified in the query is replaced with a minimal set of deletes, updates, and inserts, with the equivalent net effect. Most important here is that there can’t be a combination of a delete and insert for the same SupplierID value, which would either result in an unwarranted foreign key violation error (if processed in that order), or in a uniqueness violation (if in the other order) in the intermediate state.
An update that does more than you think
After these preparations, it’s time for the Clustered Index Update operator to finally update the rows. But wait … we just noticed how the original set of updates is translated to a combination of inserts, updates, and deletes. And yet, there is no Clustered Index Insert operator in the entire execution plan, nor a Clustered Index Delete. How does that work?
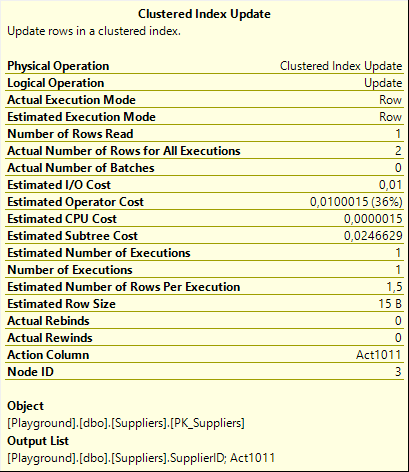 The answer is, of course, in the properties, as shown to the right here. In this case our primary interest is not the Object property (though it’s always good to know that no extra indexes are affected in this case), but the Action Column property. This property lists, in this case, Act1011. That is the action column, originally produced by the Split operator; then if and when needed modified by Collapse. Remember, this column holds, for each row, one of the values 1, 3, or 4, to represent that the row is an update, delete, or insert. By passing this column to the Clustered Index Update and setting it as the Action Column property, the Clustered Index Update will actually behave like a Clustered Index Merge operator. For each row in its input, it will check the Action Column to determine whether the row should be inserted, updated, or deleted.
The answer is, of course, in the properties, as shown to the right here. In this case our primary interest is not the Object property (though it’s always good to know that no extra indexes are affected in this case), but the Action Column property. This property lists, in this case, Act1011. That is the action column, originally produced by the Split operator; then if and when needed modified by Collapse. Remember, this column holds, for each row, one of the values 1, 3, or 4, to represent that the row is an update, delete, or insert. By passing this column to the Clustered Index Update and setting it as the Action Column property, the Clustered Index Update will actually behave like a Clustered Index Merge operator. For each row in its input, it will check the Action Column to determine whether the row should be inserted, updated, or deleted.
You might now wonder why SQL Server uses a Clustered Index Update operator that effectively does a merge, and why it doesn’t use the Clustered Index Merge operator instead. I have been wondering that myself as well. And while I don’t know for sure, I do have two theories. One is that this pattern for processing updates to a primary key column already existed before the MERGE keyword, and hence the Merge operators, was added; and that this optimization pattern was simply left unchanged. But that would not explain why those new Merge operators were even added at all, if the Update operators can do the same thing. So I have more confidence in my second theory, which is that there are some subtle behaviour differences between a Clustered Index Merge and a Clustered Index Update with an Action Column, and that those difference are important when, for instance, functionality such as triggers is in play. One day I will investigate how triggers affect update and merge plans, but not today.
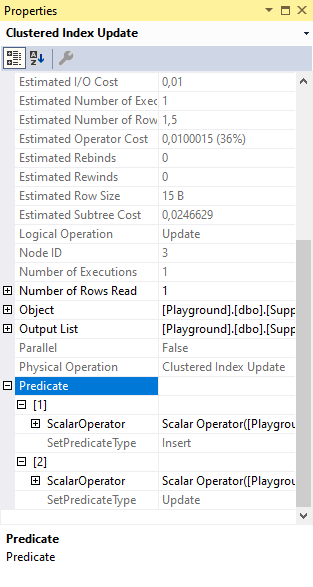 In the full properties list of the Clustered Index Update, you see that the Predicate property is a bit more complex as well. The screenshot to the right shows that it is actually a set of two scalar operators, each with their own SetPredicateType. Not visible in the screenshot (for obvious reasons when you follow along with the code on your own system) is the content of these two scalar operators.
In the full properties list of the Clustered Index Update, you see that the Predicate property is a bit more complex as well. The screenshot to the right shows that it is actually a set of two scalar operators, each with their own SetPredicateType. Not visible in the screenshot (for obvious reasons when you follow along with the code on your own system) is the content of these two scalar operators.
The first one, with SetPredicateType = Insert, reads “Scalar Operator(SupplierID = RaiseIfNullUpdate(SupplierID), SupplierName = RaiseIfNullUpdate(SupplierName))”. This is the predicate used when the Action Column indicates that an insert is needed. An insert obviously has to supply data for all columns, and that’s what this expression does. The RaiseIfNullUpdate is a special internal function that causes execution to stop, throw an error, and rollback the transaction if an attempt is made to insert a NULL in a column that doesn’t allow it.
The second one, with SetPredicateType = Update, reads (simplified): “Scalar Operator(SupplierName = RaiseIfNullUpdate(SupplierName))”. So this sets only the SupplierName, for the updates that are produced by the Collapse operator (which, as explained, are actually the result of combining a delete and an insert that the Split created from the original updates). The SupplierID column obviously doesn’t need to be set for this case, since this is for updating an existing row.
Constraint check
The foreign key constraint is, once more, verified by a Nested Loops operator into an Index Seek. As expected, the same pattern we also saw when we looked at the delete statement. But there is one important difference, as can be seen in the screenshot on the right. The delete plan we looked at in the previous post did not use a Pass Through property, even in the (really rare and esoteric) cases where the referenced value can be null and it would save a bit of performance, simply because it isn’t needed for correctness.
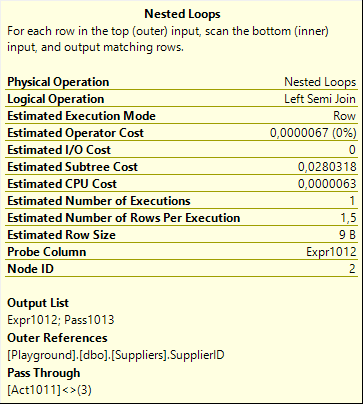 But this time, the optimizer did set the Pass Through property. When Act1011, the Action Column used in the Clustered Index Update (and computed by Split, Sort, and Collapse) is not equal to 3 (delete), the Index Seek on the inner input of the Nested Loops is bypassed, and the Pass1023 column is set so that the Assert operator knows the Pass Through condition was met for this row. So for modifications that, after the split, sort, collapse, were net updates or inserts, nothing gets checked. Inserts in the parent table can never cause a violation of the foreign key constraint after all. And the rows that are net updates after this pattern are updates to the SupplierName, as explained above; the SupplierID is unchanged, so this of course also cannot violate that constraint.
But this time, the optimizer did set the Pass Through property. When Act1011, the Action Column used in the Clustered Index Update (and computed by Split, Sort, and Collapse) is not equal to 3 (delete), the Index Seek on the inner input of the Nested Loops is bypassed, and the Pass1023 column is set so that the Assert operator knows the Pass Through condition was met for this row. So for modifications that, after the split, sort, collapse, were net updates or inserts, nothing gets checked. Inserts in the parent table can never cause a violation of the foreign key constraint after all. And the rows that are net updates after this pattern are updates to the SupplierName, as explained above; the SupplierID is unchanged, so this of course also cannot violate that constraint.
Only when a SupplierID value was actually deleted from the table, the foreign key might be violated. So in that case, and in that case only, the Index Seek does get called to check if there are any referencing rows. And because the Nested Loops runs as a probed Left Semi Join, it stops immediately after finding the first matching row, or after searching and finding no matching rows. The result of this existence check gets passed to the parent operator in the Probe Column: Expr1012.
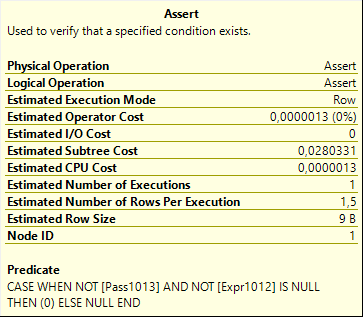 Finally, the Assert operator uses both the Pass1023 column (to know whether the foreign key was checked at all) and the Expr1012 column (the result of that foreign key check) to stop execution, rollback the transaction and throw an error if something in the statement caused the foreign key constraint to be violated.
Finally, the Assert operator uses both the Pass1023 column (to know whether the foreign key was checked at all) and the Expr1012 column (the result of that foreign key check) to stop execution, rollback the transaction and throw an error if something in the statement caused the foreign key constraint to be violated.
Conclusion
Updates to a primary key column are a bad idea. Especially if that primary key is referenced by a foreign key constraint.
But they are still possible. And when used, SQL Server produces a really interesting execution plan to ensure the update is executed as it should, without unexpected errors, and with the expected errors if the update would violate a constraint. I learned a lot from diving into the details. I hope you did too.
We now explored all variations of checking whether a foreign key was violated and throwing an error if that it the case. But there is still more to explore related to foreign keys. The most common use case for foreign keys is to prevent modifications that violate business rules. But they can also be used to automatically fix other data, using the ON DELETE and ON UPDATE action specification. We will look at the effects of those options on execution plans for modifications in the next plansplaining post.






{kind=link}
{kind=link}
3 Comments. Leave new
[…] Hugo Kornelis conclues a mini-series on foreign key constraints: […]
[…] to part fifteen of the plansplaining series. In the three previous parts I looked at the operators and properties in an execution plan that check a modification doesn’t […]
[…] data modifications, building on the more generic discussion of data modification in the previous four posts. Later posts will look at data retrieval and some specific […]