Welcome to part twelve of the plansplaining series, where I’ll discuss foreign keys in the context of execution plans.
And just to be clear, this is not about how foreign keys and other constraints can be used to simplify execution plans and speed up query executions. That is documented in so many places that I trust you already know how important those constraints are.
No, today we’ll look at the extra work that SQL Server needs to do to ensure that your changes don’t violate any of your foreign key constraints.
Sample tables
I will use a very simple scenario for this post, with just two tables, one foreign key constraint, and a minimum amount of columns. After all, I want to investigate the mechanics; adding dozens of columns adds realism, but it also adds complexity to the execution plan that might obscure the logic that is related to enforcing the foreign key constraint.
CREATE TABLE dbo.Suppliers
(SupplierID int NOT NULL,
SupplierName varchar(50) NOT NULL,
CONSTRAINT PK_Suppliers
PRIMARY KEY (SupplierID));
CREATE TABLE dbo.Products
(ProductCode char(10) NOT NULL,
ProductName varchar(50) NOT NULL,
SupplierID int NULL,
CONSTRAINT PK_Products
PRIMARY KEY (ProductCode),
CONSTRAINT UQ_Products_ProductName
UNIQUE (ProductName),
CONSTRAINT FK_Products_Suppliers
FOREIGN KEY (SupplierID)
REFERENCES dbo.Suppliers (SupplierID),
INDEX ix_Products_SupplierID NONCLUSTERED (SupplierID));
As you see, we just have two simple tables, with Product and Supplier data, linked by a foreign key. For the sake of simplicity, I assume only one supplier for each product.
Foreign key check on insert
Inserts on the Suppliers table do not need to be checked. But we do need some data in there so we can test inserts on the Products table. Here’s the demo data I use:
INSERT dbo.Suppliers (SupplierID,
SupplierName)
VALUES (1, 'Supplier 1'),
(2, 'Supplier 2'),
(3, 'Supplier 3'),
(4, 'Supplier 4'),
(5, 'Supplier 5'),
(6, 'Supplier 6');
With this data in place, we can now insert data in the Products table, and check the execution plan to see how SQL Server checks that we don’t violate the foreign key. Note that I only insert valid data. Invalid data would cause a run-time error, and a run-time error prevents the execution plan plus run-time statistics from being returned. I can of course just look at the execution plan only without even executing the statement, but I generally prefer to add the run-time statistics when possible. That extra detail can sometimes be valid.
CREATE TABLE #Products
(ProductCode char(10) NOT NULL PRIMARY KEY,
ProductName varchar(50) NOT NULL,
SupplierID int NULL);
INSERT #Products (ProductCode,
ProductName,
SupplierID)
VALUES ('Prod 1', 'Product number 1', 1),
('Prod 2', 'Product number 2', 2),
('Prod 3', 'Product number 3', 3),
('Prod 4', 'Product number 4', 4),
('Prod 5', 'Product number 5', 5),
('Prod 6', 'Product number 6', 1),
('Prod 7', 'Product number 7', NULL),
('Prod 8', 'Product number 8', 2),
('Prod 9', 'Product number 9', 3);
INSERT dbo.Products (ProductCode,
ProductName,
SupplierID)
SELECT ProductCode,
ProductName,
SupplierID
FROM #Products;
Note that there is no actual need to use an intermediate table. I just like to vary my methods a bit. This is two statements, so obviously two execution plans. We only care about the second one:
Scan and Insert
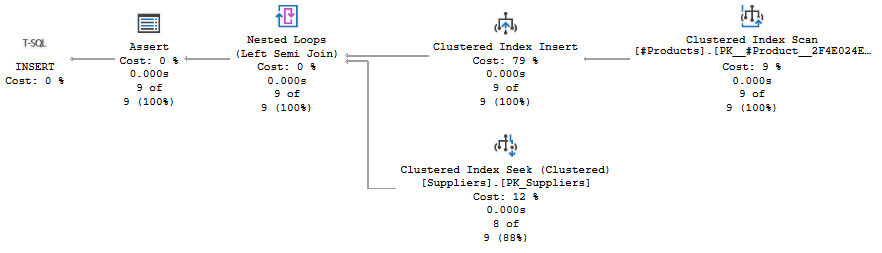
The top right of this execution plan looks very unsurprising. A Clustered Index Scan to read all rows from the #Products temporary table, and those rows are then passed to a Clustered Index Insert operator for insertion into our permanent table dbo.Products. But wait? Why is there no table or index name listed below the operator name? That’s actually because the operator has not one but three items in its Object property. When a Clustered Index Insert targets just a single index, SSMS can work out the name and show it. But when Clustered Index Insert targets multiple objects, SSMS plays it safe and displays none.
 The names in the Object property show that this Clustered Index Insert inserts new data where we expect it, in PK_Products, the clustered index on the Products table. But it simultaneously adds the same rows in two other indexes as well, in ix_Products_SupplierID and UQ_Products_ProductName. These are both actually nonclustered index, yet the Clustered Index Scan can add rows to them.
The names in the Object property show that this Clustered Index Insert inserts new data where we expect it, in PK_Products, the clustered index on the Products table. But it simultaneously adds the same rows in two other indexes as well, in ix_Products_SupplierID and UQ_Products_ProductName. These are both actually nonclustered index, yet the Clustered Index Scan can add rows to them.
This plan choice is the result of a cost based decision. When the optimizer estimates a low number of rows to be inserted, as in this case, it will add all nonclustered indexes as extra objects to be maintained in the Object property of the Clustered Index Insert, also known as “narrow plan”. Because the estimated number of new rows is low, SQL Server will insert rows in whatever order they are processed. Further down in this post, we’ll look at an example of the alternative, a “wide plan”.
Nested Loops
 The Clustered Index Scan returns the 9 rows it inserts to its parent, a Nested Loops. And this Nested Loops has some interesting properties, as you can see in the screenshot on the right. For starters, there is the Probe Column property. The logical operation is listed as a Left Semi Join, but the presence of a Probe Column means it’s actually doing a probed left semi join instead of a normal left semi join. (See here for an explanation of the difference). The result of the probe operation is passed to the parent operator in the Probe Column: Expr1008.
The Clustered Index Scan returns the 9 rows it inserts to its parent, a Nested Loops. And this Nested Loops has some interesting properties, as you can see in the screenshot on the right. For starters, there is the Probe Column property. The logical operation is listed as a Left Semi Join, but the presence of a Probe Column means it’s actually doing a probed left semi join instead of a normal left semi join. (See here for an explanation of the difference). The result of the probe operation is passed to the parent operator in the Probe Column: Expr1008.
There’s also a property called Pass Through. The full value is not visible in the screenshot, but if you run the code, check this property in the execution plan, and remove the four-part naming and all the brackets, you’ll see that it boils down to a test on “SupplierID IS NULL”. When Nested Loops has a Pass Through property, it evaluates this test for each row from the outer (upper) input and when the result is True it simply passes the row unchanged, without even bothering to check the inner (lower) input.
In this specific example, the reason for this Pass Through condition is that a foreign key is defined on SupplierID, but SupplierID allows NULL values. A foreign key constraint does not affect NULL values, so for any row that has a NULL here the actual check on the foreign key condition (which is what the inner input of the Nested Loops does) can simply be skipped.
In the Output List property, you see that Expr1008, the Probe Column is returned. But you also see another column, called Pass1009. This is the pass-through indicator, a bit column that is set for rows that met the Pass Through property and hence didn’t execute the inner input. Both Expr1008 and Pass1009 are also included in the Defined Values property, but curiously both without a definition. For Expr1008 this makes sense: it being listed as the Probe Column should be sufficient to know how it is defined. For Pass1009 this is more surprising. I don’t know whether Nested Loops has hardcoded logic that uses the column name to determine that this column is the pass-through indicator, or whether this is stored in the actual internal representation of the execution plan but not properly translated when outputting it in XML form. Either way, the only way for us to know this is to look at the column name.
Seek and Assert
The inner input of the Nested Loops is a Clustered Index Seek. I’m not going to show its properties here, and not going to waste a lot of words on it. It simply tries to find a row in the Suppliers table, based on the SupplierID in the row it just inserted in the Products table. This makes sense. After all, the foreign key on Products tells SQL Server to only accept Products if the SupplierID exists in the Suppliers table, and the best way to check for its existence is to try to read it.
You may have noticed in the execution plan shown above that even though there are nine rows inserted in Products, this Clustered Index Seek returns just 8 rows. That is, in this case, not caused by the seek failing to find a row. The properties of the Clustered Index Seek will tell you that it only executed 8 times. The Pass Through property on the Nested Loops operator caused it to not even try to find a match for product number 7: it was added with SupplierID NULL, and the Pass Through property tells Nested Loops not to execute its inner input if SupplierID is NULL.
If instead of NULL, I had attempted to insert a value that doesn’t exist, then the Number of Executions would not have been reduced, but the Actual Number of Rows for All Executions would have been less. However, in that case the query would abort before finishing, so we would not have been able to see that execution plan.
 For rows that do not satisfy the Pass Through test, Nested Loops does execute the Clustered Index Seek, and the result (row found or no row found) is passed in the Probe Column to its parent operator: Assert. The only important property of this operator is its Predicate. This is a logical test that evaluates to either NULL, or an integer value. If the result is NULL, the row is simply passed. But if a non-NULL result is found, Assert will abort the query with a run-time error, forcing a rollback of the transaction, and display an error message. (What error message cannot be determined from the execution plan).
For rows that do not satisfy the Pass Through test, Nested Loops does execute the Clustered Index Seek, and the result (row found or no row found) is passed in the Probe Column to its parent operator: Assert. The only important property of this operator is its Predicate. This is a logical test that evaluates to either NULL, or an integer value. If the result is NULL, the row is simply passed. But if a non-NULL result is found, Assert will abort the query with a run-time error, forcing a rollback of the transaction, and display an error message. (What error message cannot be determined from the execution plan).
The test here is (reformatted for readability):
CASE
WHEN (NOT Pass1009)
AND Expr1008 IS NULL
THEN 0
ELSE NULL
END
So in other words: if the pass-through indicator is not set (the Clustered Index Seek was actually executed), and the result of that Clustered Index Seek was that no row was found (Probe Column not set), then the value 0 is returned, causing the query to fail with an error message. In all other cases (which may be either no need to check that the supplier exists, or it was checked and a row was found), the Predicate is NULL and no run time error occurs. For this row. The check is of course repeated for every row. And just a single violation will stop execution, roll back the entire transaction, and show an error message.
Do I look wide in this plan?
As mentioned above, the choice for the narrow plan shown above is made by the optimizer, based on expected number of rows to be inserted. Once that estimate exceeds a certain threshold, we will instead get a so-called “wide plan”, where rows are first inserted into the Clustered Index only, the sorted to match the natural order of a nonclustered index and then passed to a (nonclustered) Index Scan. And this can be repeated multiple times if there are more nonclustered indexes. Let’s see if we can force that. I’ll first generate a much bigger amount of input by simply cross joining the temporary table we already have a few times to itself:
SELECT p1.ProductCode,
p1.ProductName,
p1.SupplierID
INTO #p2
FROM #Products AS p1
CROSS JOIN #Products AS p2
CROSS JOIN #Products AS p3
CROSS JOIN #Products AS p4
CROSS JOIN #Products AS p5;
This creates over 59,000 rows in #p2. More than enough to trigger a wide plan, if we want to insert it into dbo.Products:
INSERT dbo.Products (ProductCode,
ProductName,
SupplierID)
SELECT ProductCode,
ProductName,
SupplierID
FROM #p2;
However, the data in #p2 has lots of duplicates in the ProductCode and ProductName columns, so any attempt to actually execute this query fails with violations of the primary key and the unique constraint. And when a query fails, the execution plan plus run-time statistics is not returned. But we can just ask SQL Server to show us the execution plan only, without actually executing the query:

In this execution plan you see how the data is sorted before it is passed into the Clustered Index Insert, then sorted to a better order for the Index Insert on ix_Products_Supplier_ID. The Table Spool operators are used to make the same data available in another branch of the execution plan, where it is sorted in yet another order before being inserted in the UQ_Products_ProductName table.
For the actual foreign key check, the basic logic is the same, but the operators used are different. Again, cost-based decisions. For just 9 rows, a Nested Loops operator into a Clustered Index Seek is okay. For 59,000 rows, that same strategy would be horribly slow.
Merge Join
In this case, the inserted rows are already sorted by SupplierID, as part of the optimization for the Index Insert in ix_Products_SupplierID. The Suppliers table has a clustered index on the SuppliersID column, so using a Clustered Index Scan with the Ordered property set to True ensures that this data is also sorted by SupplierID. That enables the optimizer to use a Merge Join to combine the two streams.
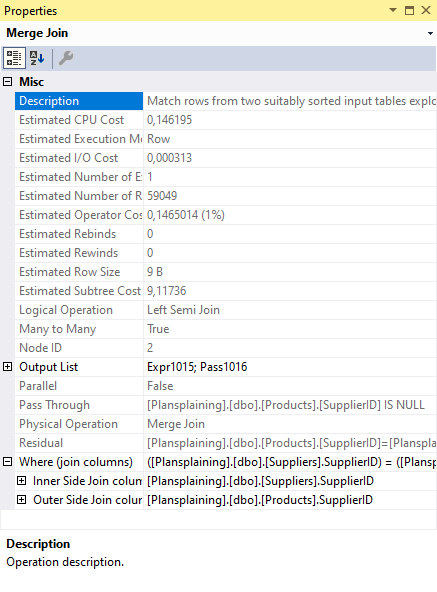 Like the Nested Loops operator in the narrow plan, this Merge Join appears to use the Left Semi Join logical operation. But also like the Nested Loops, the operator actually performs a probed left semi join. For a Nested Loops operator, this is directly visible in the execution plan. For a Merge Join, this is not the case. The only indication of the probed operation in the SSMS representation of the execution plan, or for that matter in the underlying XML, is the presence of an output column that is not available in any of the inputs, and for which no formula is specified in the Defined Values property (which, in fact, is not even included in this case).
Like the Nested Loops operator in the narrow plan, this Merge Join appears to use the Left Semi Join logical operation. But also like the Nested Loops, the operator actually performs a probed left semi join. For a Nested Loops operator, this is directly visible in the execution plan. For a Merge Join, this is not the case. The only indication of the probed operation in the SSMS representation of the execution plan, or for that matter in the underlying XML, is the presence of an output column that is not available in any of the inputs, and for which no formula is specified in the Defined Values property (which, in fact, is not even included in this case).
A second similarity is that this Merge Join also has a Pass Through property, with the same condition as before, to avoid testing the foreign key relationship if the SupplierID is set to NULL. And we also see a columns named Pass1016 in the Output List. Where this column was listed without definition in Defined Values of the Nested Loops, there simple is no Defined Values on this Merge Join. But other than that small visual difference, the logic for this column is the same.
A Nested Loops can use the Pass Through expression to avoid executing the inner input when it is not needed. That kind of performance saving is not possible for a Merge Join; this operator has to read through all rows of both inputs. But the Pass Through expression does have the effect that the Merge Join will not even bother to look for matches on rows that meet the condition; it simply passes them unchanged.
Conclusion
We looked at how a foreign key affects the execution plan of an insert query. The functional description is a mere one-liner: check whether the inserted value exists in the referenced table and roll back the transaction with a runtime error if it doesn’t.
But there are some quite interesting optimizations at work to do this test as efficiently as possible. We saw how the optimizer uses the expected number of rows to determine how to best maintain the indexes on the table, and how that same number of rows also influences the choice for the proper join type to use. We also saw how the execution plan uses a special variation on the semi join algorithm, the probed semi join, to check whether an inserted value exists in the referenced table. And we also saw how a Pass Through expression is used to avoid checking referential integrity for NULL values.
I do want to point out that, even though verifying constraints does add extra work on data modifications, you should still always defined all the constraints that follow from the business rules. Maintaining referential integrity in other ways is always even more expensive. And though not properly maintaining integrity at all will indeed speed up your modifications by a bit, you can be almost certain that you’ll have inconsistent data very fast, and a huge headache to cleanse the issues after the fact.
Inserting is just one piece of the story, though. What about deleting data? What about updates? That, and more, will be the topic of a later plansplaining post.






{kind=link}
{kind=link}
5 Comments. Leave new
[…] already looked at inserting data in the referencing (child) table, and at deleting data from the referenced (parent) table as well […]
[…] to part fifteen of the plansplaining series. In the three previous parts I looked at the operators and properties in an execution plan that check a […]
The first sentence of the first paragraph under Scan and Insert says “The top left of this execution plan looks very unsurprising. “. Don’t you mean top right?
Yikes. That should not have gone past my proof-reading.
Thanks for pointing it out. I have already edited the post to fix this mistake.
[…] four posts on data modifications, building on the more generic discussion of data modification in the previous four posts. Later posts will look at data retrieval and some specific […]