Welcome to part fifteen of the plansplaining series. In the three previous parts I looked at the operators and properties in an execution plan that check a modification doesn’t violate foreign key constraints. That part is done. But I’m not done with foreign keys yet.
We normally expect foreign keys to throw an error on violations. But that’s actually only the default option: they can also be set to be self-correcting. This is done using the ON UPDATE and ON DELETE clauses, which provide the user with several choices on how to handle child data that would become orphaned, and hence violate the constraint, as a result of a change in the parent table.
Sample tables
Here is once more the same set of sample tables and sample data that I already used in the previous posts. I have returned to the original data. And I have, of course, changed the definition of the FOREIGN KEY constraint, to set it to be self-correcting.
DROP TABLE IF EXISTS dbo.Products,
dbo.Suppliers;
GO
CREATE TABLE dbo.Suppliers
(SupplierID int NOT NULL,
SupplierName varchar(50) NOT NULL,
CONSTRAINT PK_Suppliers
PRIMARY KEY (SupplierID));
CREATE TABLE dbo.Products
(ProductCode char(10) NOT NULL,
ProductName varchar(50) NOT NULL,
SupplierID int NULL DEFAULT (1),
CONSTRAINT PK_Products
PRIMARY KEY (ProductCode),
CONSTRAINT UQ_Products_ProductName
UNIQUE (ProductName),
CONSTRAINT FK_Products_Suppliers
FOREIGN KEY (SupplierID)
REFERENCES dbo.Suppliers (SupplierID)
ON UPDATE CASCADE
ON DELETE SET DEFAULT,
INDEX ix_Products_SupplierID NONCLUSTERED (SupplierID));
INSERT dbo.Suppliers (SupplierID, SupplierName)
VALUES (1, 'Supplier 1'),
(2, 'Supplier 2'),
(3, 'Supplier 3'),
(4, 'Supplier 4'),
(5, 'Supplier 5'),
(6, 'Supplier 6');
INSERT dbo.Products (ProductCode, ProductName, SupplierID)
VALUES ('Prod 1', 'Product number 1', 1),
('Prod 2', 'Product number 2', 2),
('Prod 3', 'Product number 3', 3),
('Prod 4', 'Product number 4', 4),
('Prod 5', 'Product number 5', 5),
('Prod 6', 'Product number 6', 1),
('Prod 7', 'Product number 7', NULL),
('Prod 8', 'Product number 8', 2),
('Prod 9', 'Product number 9', 3);
Note that, unlike the previous parts, the above is not the same as you would have if you followed along with the previous posts. So you should always run this code to set up for this fresh start.
Auto-corrupt for foreign keys
If you insert or update a row in the child table with an incorrect reference, there’s nothing SQL Server can do for you. That’s just an error, and there is no automatic correction available unless you code that logic yourself (which would probably require an INSTEAD OF trigger, patience, lengthy debugging, perseverance, and lots of booze).
But for the parent, Microsoft has you covered. When an update or delete to the parent table removes a key value that is still referenced, the foreign key can correct the situation. And you decide how. The default action, indicated by NO ACTION, is to simply refuse the modification. We looked at that in the previous parts. But there are three other alternatives.
- SET NULL means that for all rows in the child table that reference the removed parent value, the referencing column is simply changed to a NULL, making them orphans. For the example used here. The data would indicate a product for which we have no supplier, so work to be done for the purchasing department.
- The SET DEFAULT option is similar, but here the violating rows in the child get changed to the default value for the referencing columns. This is used in our example as the ON DELETE action. So when a supplier is removed, all products we purchased of them now get supplier 1, our default supplier, instead.
- And finally, CASCADE means that the change in the parent, whatever it was, gets mimicked. This can for instance be used as in our example, for an ON UPDATE action. If a key value in the parent is modified, then all children referencing that row keep referencing it, now using the new key value. For keys that are prone to change, this can be a useful option.
But with ON DELETE, the CASCADE option can be very dangerous: a simple mistake that would delete just a single row might cascade into a large scale deletion of thousands of rows, across multiple tables, if this option is overused.
Cascading update
As mentioned last week, updating a primary key is seldom a good idea. But reality happens. Sometimes the column that makes perfect sense to use as a primary key just happens to be mutable. Sometimes you choose to use a meaningless generated number as the primary key so you never have to change, and then your company is in a merger, two databases need to be integrated, and that other databases uses an artificial key as well.
Whatever the reason, in our example “Supplier 2” really needs to have their SupplierID value changed:
UPDATE dbo.Suppliers SET SupplierID = 7 WHERE SupplierName = 'Supplier 2';
There’s not much data in the demo table, and it’s easy to see that this change impacts two products, Prod 2 and Prod 8. Both of them are supplied by this supplier. With a normal foreign key, the update above would fail and be rolled back. But we have configured the foreign key for autocorrect: ON UPDATE CASCADE. So the same change made to the parent will also be made to the child.

And this is how that change is made. A few of the elements look familiar after the previous posts. But some other elements are new. Let’s take a look!
Modifying the parent
The top row of the execution plan is for the actual change. The update itself is relatively simple. The WHERE clause uses an unindexed column, so finding the affected rows requires a Clustered Index Scan in this case; it returns only the SupplierID column. The Compute Scalar then computes a new column, Expr1007, and sets it to the constant value 7. That is the new SupplierID value as specified in the update query. The Table Spool acts as Halloween protection, but in this case also serves a secondary purpose that I’ll cover later. The Clustered Index Update then modifies the data in the clustered index. There are no other indexes that need to be modified, so that’s about it. If there had been no foreign key constraint, then this upper branch of the execution plan would have been the entire execution plan.
But in this case, the Sequence operator ensures that, once all affected rows have been modified, the lower branch starts to execute. This is where the foreign key action happens.
Cascading to the child
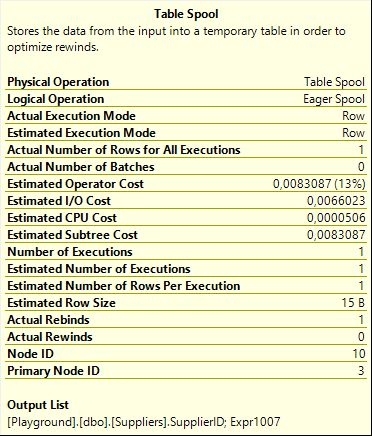 On the second input of the Sequence, each operator calls its child until the Table Spool on the far right is called. This operator has no child. When you see a Table Spool in an execution plan that does not have a child operator, you always need to check its properties, specifically the Primary Node ID property. This is the node ID of another spool operator in the execution plan. In this case, the Primary Node ID of this Table Spool is 3, which is a reference to the Table Spool in the upper input of the Sequence operator, not to the third Table Spool operator in this execution plan (which is also on this second input to Sequence).
On the second input of the Sequence, each operator calls its child until the Table Spool on the far right is called. This operator has no child. When you see a Table Spool in an execution plan that does not have a child operator, you always need to check its properties, specifically the Primary Node ID property. This is the node ID of another spool operator in the execution plan. In this case, the Primary Node ID of this Table Spool is 3, which is a reference to the Table Spool in the upper input of the Sequence operator, not to the third Table Spool operator in this execution plan (which is also on this second input to Sequence).
This Primary Node ID property tells us that this Table Spool reads data from the worktable generated by the spool operator that has Node ID equal to 3. We already know that that Table Spool stores the original and new SupplierID for all rows to be updated. So this means that, after the upper branch ensured that the actual update was done, we now once more can read all affected rows, with both the original and the new SupplierID value. This is the secondary function of this Table Spool that I alluded to above.
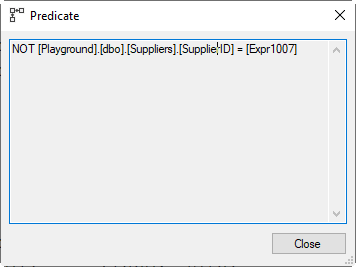 These rows are then first passed through a Filter operator that checks whether the two columns read from the spooled worktable are actually different. The query could in theory affect a row that already had SupplierID 7 and set it to 7 again. The actual update still needs to be carried out in such a case, that’s why the upper branch doesn’t include logic to filter these cases. But the actions on this lower branch are apparently only needed when the value actually changed, so rows that were no real change are discarded here.
These rows are then first passed through a Filter operator that checks whether the two columns read from the spooled worktable are actually different. The query could in theory affect a row that already had SupplierID 7 and set it to 7 again. The actual update still needs to be carried out in such a case, that’s why the upper branch doesn’t include logic to filter these cases. But the actions on this lower branch are apparently only needed when the value actually changed, so rows that were no real change are discarded here.
The remaining rows are then passed to a Nested Loops operator, that calls an Index Seek on the Products table. In previous plans we looked at, for “regular” foreign key checking, we saw the same pattern all the time; but then it was always a semi join: SQL Server only had to check whether or not (at least) one matching row exists. Here, we see an Inner Join. So now SQL Server doesn’t just check whether there is a matching row, it actually finds all matching rows, returning the ProductCode of each product supplied by the supplier we just updated.
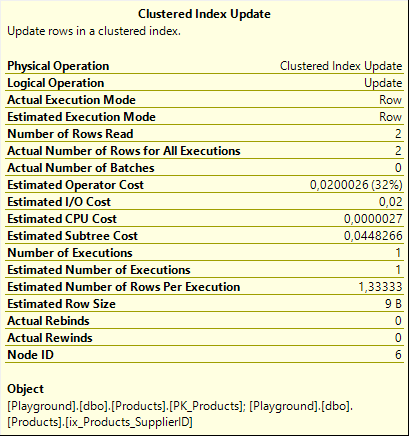 The rows returned by the Nested Loops include just two columns: ProductCode (of each product that references a supplier that was updated), and Expr1007 (the new SupplierID assigned to that supplier). These are then passed to a Clustered Index Update that targets the Products table, but that actually (as you can see in the Object property) affects a nonclustered index in addition to the clustered index. So this is another case where, based on the estimated number of rows affected, SQL Server chooses a narrow plan.
The rows returned by the Nested Loops include just two columns: ProductCode (of each product that references a supplier that was updated), and Expr1007 (the new SupplierID assigned to that supplier). These are then passed to a Clustered Index Update that targets the Products table, but that actually (as you can see in the Object property) affects a nonclustered index in addition to the clustered index. So this is another case where, based on the estimated number of rows affected, SQL Server chooses a narrow plan.
I did skip one operator in the above explanation. The Clustered Index Update changes the SupplierID column in the table, so Halloween protection is needed here too, to prevent the Index Seek returning incorrect results. That’s why we see yet another Table Spool operator here. This spool is actually included only for Halloween protection and does not serve any additional purpose.
So all in all, we see that the execution plan first does the actual modification, while storing affected rows in a spool. It then reads the affected rows, ignores those that were no actual change, then for the ones that are searches all rows in the child table that need to be updated for the ON UPDATE CASCADE action, and updates them (using Halloween protection).
Delete with default
For the demo tables in this post, I have set the ON DELETE action different than the ON UPDATE action. This enables me to show even more interesting internals of modification processing in the same demo setup. The foreign key is specified with ON DELETE SET DEFAULT, and in order to make that work I also had to supply a default constraint to the child table. This ensures that whenever a parent row is deleted that would leave children orphaned, those orphans are then reassigned to a new parent, based on the child’s table default constraint.
DELETE dbo.Suppliers WHERE SupplierID = 3;
I decided to keep the delete query itself as simple as possible. Even so, the execution plan already has ample complexity:
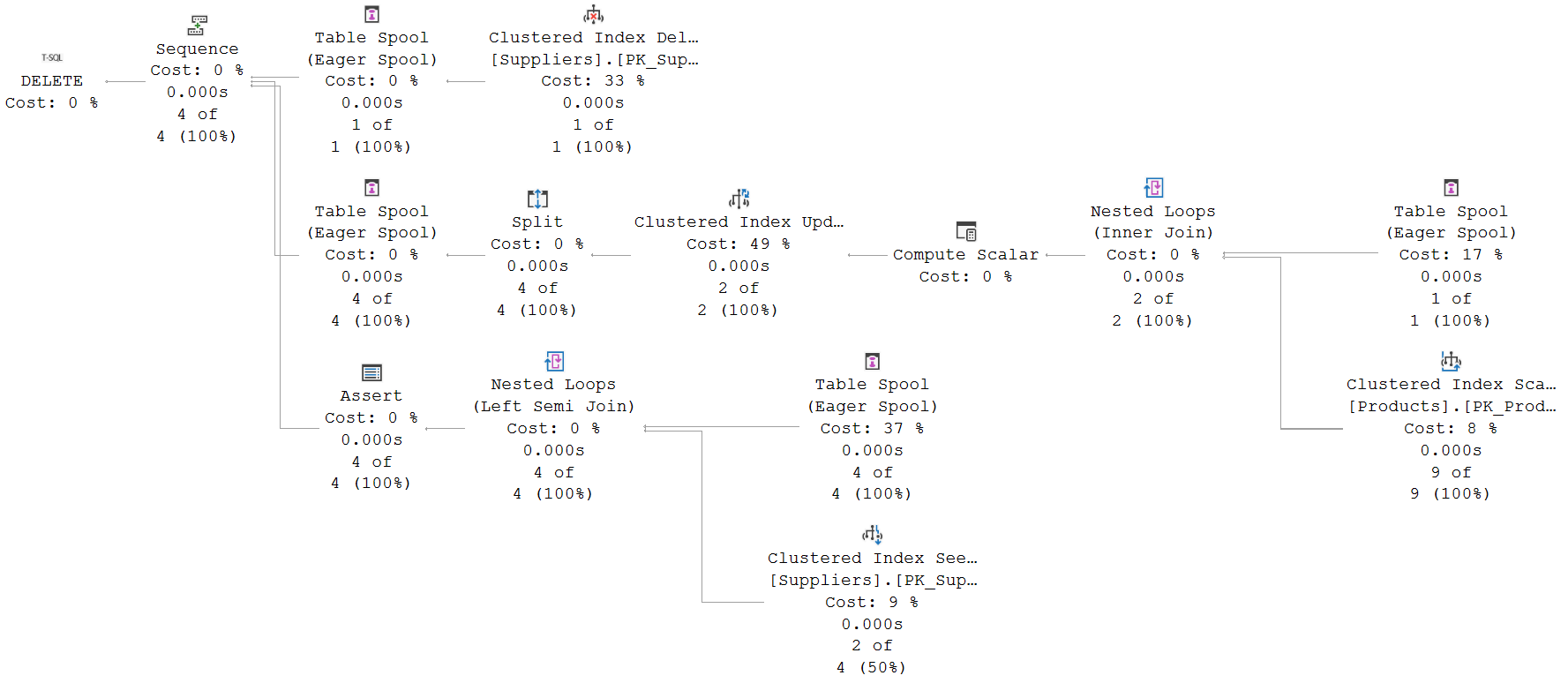
So in this case we see a Sequence operator that has not two but three inputs (and a slight visual bug in how the lines toward it are drawn, but let’s pretend Microsoft will one day actually fix that). That seems to be a lot of work, for such a simple delete!
The top line
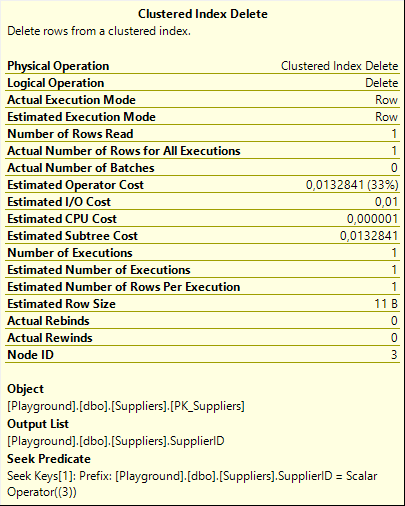 The top line is actually really simple. The Clustered Index Delete doesn’t need an input in this case, because it can use its own Predicate property to find the row to be deleted. It finds that row, and if found it deletes it and then passes a row with just a single column, the SupplierID of the just deleted row, to its parent.
The top line is actually really simple. The Clustered Index Delete doesn’t need an input in this case, because it can use its own Predicate property to find the row to be deleted. It finds that row, and if found it deletes it and then passes a row with just a single column, the SupplierID of the just deleted row, to its parent.
This parent is a Table Spool. In this case it appears not to be there for Halloween protection. Or, rather … well, we’ll get to that. For now, it appears this spool operator is only there to make the deleted rows available for processing by the lower branches, once the Sequence operator executes those.
And yes, I write rows, plural. In this case, the WHERE clause of the query is on the primary key column, so there can never be more than one row affected. But a lot of the elements in the execution plans for modifications use standard patterns. Based on the estimated number of rows, the optimizer can change things such as order of operators, join type used, etc. But the basic pattern will still be there.
In this specific case the Table Spool will never store more than a single row. But the same pattern can be used in execution plans that affect more rows, and that’s why I describe it in more generic terms.
The second line (most of it)
On the right side of the second line, we see the same pattern we saw for the update example above: a Table Spool to read all rows that were deleted by the operators in the top line, and a Nested Loops into an Index Seek to find the rows in the Products table that are now violating the foreign key constraint because the reference the supplier just deleted.
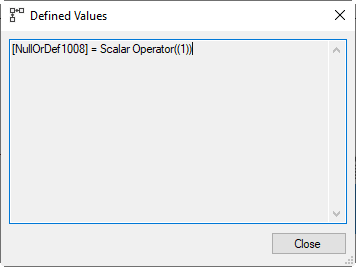 These rows are then passed through a Compute Scalar, where a new column is computed. The column is called NullOrDef1008, and its value is set to 1. The name of this column betrays that this standard pattern is used for both ON DELETE SET DEFAULT and ON DELETE SET NULL. In the latter case, the NullOrDef1008 column would be set to NULL. But here it is set to 1, the value used in the default constraint for the SupplierID column in the products table.
These rows are then passed through a Compute Scalar, where a new column is computed. The column is called NullOrDef1008, and its value is set to 1. The name of this column betrays that this standard pattern is used for both ON DELETE SET DEFAULT and ON DELETE SET NULL. In the latter case, the NullOrDef1008 column would be set to NULL. But here it is set to 1, the value used in the default constraint for the SupplierID column in the products table.
The output of this is then passed to a Clustered Index Update. Totally unsurprising, this operator uses the ProductCode in its input to locate the rows to update, and the NullOrDef1008 column as the new value for the SupplierID of those rows. So this is where the ON DELETE SET DEFAULT action happens. After this we should be done, right?
So why are there still more operators on this line? And what does the third input of the Sequence operator do?
The rest of the second line, and the third
To answer those questions, let’s quickly look at the remaining operators. After updating the SupplierID in the Products table, the Clustered Index Update returns a row with this SupplierID as the only column. This is passed through a Split operator, which breaks the update up into a delete and an insert. This is particularly interesting: Clustered Index Update returns only the new SupplierID value, so when this Split operator splits the update into a delete and an insert, it can’t provide the correct “old” SupplierID in the row created for the delete. The row will be created, but with what data? Better hope this row gets discarded later!
The rows coming from the Split are passed to a Table Spool, to store them for later use. Use, in this case, by another Table Spool: the one on the far right of the third input of the Sequence operator. (I didn’t include screenshots of the properties, but if you check the execution plan you will see that the Primary Node Id of the Table Spool on the third line matches the Node ID of the Table Spool on the second line).
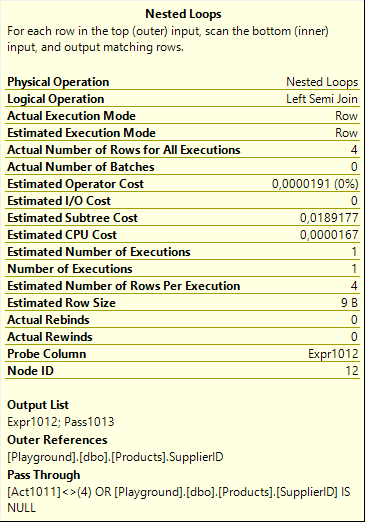 And what happens then is actually the exact same pattern we already saw in one of the earlier posts in this series. The Nested Loops does a probed semi join, but not for all rows: the Pass Through property means the semi join is skipped when Act1011 is not equal to 4, or when SupplierID is NULL. So the semi join only actually executes the Clustered Index Seek on its inner input when it processes a row that represents an “insert” (remember, this is data produced by the Split operator, that replaced each update with a delete and an insert) of a row with a non-NULL SupplierID. For those rows, existence of the supplier is checked, and relayed to the parent in the Probe Column, Expr1012. All other rows are passed unchanged, with Pass1013 set to True.
And what happens then is actually the exact same pattern we already saw in one of the earlier posts in this series. The Nested Loops does a probed semi join, but not for all rows: the Pass Through property means the semi join is skipped when Act1011 is not equal to 4, or when SupplierID is NULL. So the semi join only actually executes the Clustered Index Seek on its inner input when it processes a row that represents an “insert” (remember, this is data produced by the Split operator, that replaced each update with a delete and an insert) of a row with a non-NULL SupplierID. For those rows, existence of the supplier is checked, and relayed to the parent in the Probe Column, Expr1012. All other rows are passed unchanged, with Pass1013 set to True.
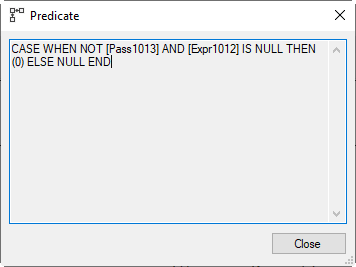 And then the Assert operator checks its Predicate condition, so it can abort the operation when Pass1013 is not True, and Expr1012 is NULL. In other words, when the row retrieved from the Table Spool represents an insert of a non-null SupplierID that was not found in the Suppliers table. So these operators are combined simply the same pattern we saw before, for checking violation of a foreign key by new data in the child.
And then the Assert operator checks its Predicate condition, so it can abort the operation when Pass1013 is not True, and Expr1012 is NULL. In other words, when the row retrieved from the Table Spool represents an insert of a non-null SupplierID that was not found in the Suppliers table. So these operators are combined simply the same pattern we saw before, for checking violation of a foreign key by new data in the child.
But … why?
We know what those last operators do, and we know how they do it. But one question remains. Why are they even there?
Remember, we gave the foreign key constraint an ON DELETE action, to make it self-correcting. We saw that the execution plan includes all operators to ensure that data violating the constraint is indeed corrected. So why this check? Does SQL Server not trust its own operators to work correctly? That is of course not the case. However, SQL Server does have other trust issues. To be very specific, it does not trust you to set up a correct default value.
Let’s review what the execution plan does. It finds and deletes the rows in the parent table as specified in the update statement. It checks to see if this causes any rows in the child table to be orphaned. If that’s the case, then it reassigns those orphans to a new parent, based on the default constraint. And that’s where the distrust starts. Is that default valid? Does a row in the parent exist with a key value equal to the parent? If not, then the orphaned children would be assigned to a new parent that also doesn’t exist and the data would still be in violation of the foreign key constraint. That should never happen. The ON DELETE action cannot fix it in this case. So now, throwing an error is indeed the only viable option.
If you want to see this in action, rerun the original setup code but change the default value to one that doesn’t exist in the Supplier table, e.g. 0. Now you will see that this delete fails. It first changes the SupplierID in the supplier table. Then it changes the SupplierID of the now orphaned products. But since they are then still in violation of the constraint, the transaction gets rolled back after all, and an error is throws.
Another scenario, more complex, is when we delete multiple rows from the parent table, and the row that happens to be the one that the default points to. This case is the reason why, previously, I mentioned that one of the spool operators does provide some kind of Halloween protection. Without it, there can be scenarios where a single delete removes multiple rows; and the exact order of processing causes first some new orphaned to be reassigned to another parent, after which that parent itself is removed. I don’t think there are scenarios where this could cause actual incorrect results (at least I am not able to find any), but it’s definitely possible to waste huge amounts of work to change data in the child table that then later needs to be rechecked and then causes a violation. The Halloween protection the spool provides prevents that.
Not optimal?
If you are as critical as I am, you may have noticed a lot of wasted performance tuning opportunities in this execution plan. There are two locations where data is stored in a table spool. One is needed for Halloween protection, the other is not. Both have the ability to present their data to multiple readers, but neither does.
And then there is a split that changes each update into a delete (that is not even correct!) and an insert, discards the delete, then does a check for the insert. Why not simply do the check for the update directly?
I may be wrong. I may be overlooking something (and please tell me in the comments if I do). But based on what I know, I think the execution plan below (that I created using cut and paste in a graphics editor) would process the delete with the same results in all cases, but a bit more efficient.

Starting at the far right, we would have a Clustered Index Delete to remove the affected parent row(s) and return their data to its parent, a Table Spool (now for Halloween protection only). The rightmost Nested Loops finds the child rows that have become orphans, and passes them to a Compute Scalar and Clustered Index Update to reassign them to the default parent. The Clustered Index Update then returns these rows to another Nested Loops, that has a Pass Through for SupplierID IS NULL, and checks existence of the supplier otherwise; the Assert then checks the result.
So why does the optimizer not use this plan? I have a few theories, but I’ll share only the one I consider the most likely. I think that data modification plans are hugely based on standard patterns. If multiple foreign keys are involved, they all need to be on a separate input to a Sequence operator, and so they all need to get their data from a Table Spool. So the standard pattern is to just create that Table Spool. And then just put each foreign key check on its own line. And because some of those checks might need inserted data only, others need deleted data only, the Split is also part of the standard patten. No special cases are required. Each foreign key check is on its own line, and starts with a set of inserts and deletes that is equivalent to the actual data change.
Add a few more constraints to the demo table, and you will see that the Split and the Table Spool operators suddenly become much more useful, or even required. My alternative above only works for this specific case. It cannot be generalized.
The optimizer looks at execution plans and tries to modify them for better performance. But it has its limitations. Some things are always safe, such as changing join order or pushing a filter in a branch. Some things are not always safe. Removing an eager spool without knowing whether it’s needed for Halloween protection is very unsafe. Removing a Split as I did is only safe when you have a full understanding of what is done with the data later. That would require a lot of logic in the optimizer, and Microsoft have clearly not built that.
Conclusion
We looked at two types of self-correcting behavior of foreign key constraints, using the ON UPDATE and ON DELETE specifications. We did this in a very simple setup with just two small tables.
In more realistic databases, the complexity can quickly increase. A table might have foreign keys to multiple parents. One of those parents might in turn be the child in yet another foreign key relationship. All of those foreign keys can be set to throw errors on violation, or to be self-correcting. And if you have lots of self-correcting foreign keys, then what appears to be a simple change to a single table might potentially affect hundreds of rows, in multiple tables, due to the change cascading through all the foreign keys.
The execution plans for such modifications will reveal all that happens, or that might potentially happen. As you have seen in this post and the three previous ones, SQL Server uses mostly standard patterns that it combines as needed to guarantee the correct end result.
In the next plansplaining post, I plan to look at the execution plans for modifications on temporal tables.





{kind=link}
{kind=link}
4 Comments. Leave new
I’m guessing that “And finally, CASCASE means that the change in the parent, whatever it was, gets mimicked.” was intended to say CASCADE?
As for ON DELETE SET DEFAULT you might steal from the Kimball direction in building dimensional tables. A dimension row was always added with a -1 key value to indicate a NOT FOUND condition. In your example the reference value might be -1 because that is more likely to be seen as something to fix. Since most people start surrogate identity keys at 1 and increment, a default of 1 is not an obvious signal. And the description in the reference table might be ‘FIX ME’. Then rows do not disappear from equi-JOINs but are obvious in the need for correction.
I’m not trying to not pick, just trying to read thoroughly. I’ve been working in SQL Server since v4.2 and I still learn stuff almost daily. I love the how-does-it-work aspect you explore!
Thanks, Bryant. I have found the two places where I had typed CASCASE instead of CASCADE and corrected them both.
Most of my personal experience is with OLTP systems. I’m going to assume that everyone working with OLAP is well aware of Kimball’s work, but I also think most BI practitioners are less concerned with performance impact of foreign keys. (In fact, I think that in many cases it’s perfectly valid to not define foreign keys in a data warehouse, whereas in an OLTP system I’d have your neck for merely proposing to leave them out). I’m glad you added this comment because it can help people who access this post, but I’m not going to work it into the post since I think adding a discussion of database design best practices in this already long posts would distract from its actual content.
Hugo,
I totally agree. What I was thinking was if someone wanted to use the DEFAULT method then they might see this and think about how adopting that little OLAP trick might benefit them. Rather than a design practicum added to the post, this serves my intent perfectly.
I am looking forward to your temporal post. We just rolled out temporal testing in tSQLt and I am doing a CoP on that subject in a couple of weeks. Seeing what you’ve dug up relative to temporal tables might be insightful.
[…] Hugo Kornelis continues a dive into foreign keys: […]