This is the sixth post in the plansplaining series. Each of these blog posts focuses on a sample execution plan that exposes an uncommon and interesting pattern, and details exactly how that plan works.
In the first post, I covered each individual step of each operator in great detail, to make sure that everyone understands exactly how operators work in the pull-based execution plans. In this post (and all future installments), I will leave out the details that I now assume to be known to my readers. If you did not read part 1 already, I suggest you start there.
In this post I will take a look at a simple usage of the OVER clause with a not-so-simple execution plan. This particular usage of OVER has been available since SQL Server 2005. It allows us to mix detail and aggregated information in a single query. And I’ll have to admit that this particular execution plan pattern has had me baffled for more than a year before I finally understood exactly how it works.
Sample query
For this example I once more use the AdventureWorks sample database. I tested this on SQL Server 2017, but I have seen the same execution plan pattern in all versions since at least SQL Server 2012.
SELECT sp.BusinessEntityID,
sp.TerritoryID,
sp.SalesYTD,
SUM(sp.SalesYTD) OVER (PARTITION BY sp.TerritoryID) AS TerritorySales
FROM Sales.SalesPerson AS sp
The query above produces a very simple report, showing salespersons and their Sales YTD figure, compared to the total Sales YTD for all salespersons in their territory. The latter figure is computed by the OVER clause, as documented here.
When SQL Server 2005 released, everyone was excited about the shear simplicity of this solution, which previously required a correlated subquery. But a simple query does not necessarily equate to a simple execution plan, as you can see below. (As in the previous posts, I have added the node ID of each operator in the figure for easy reference in the rest of the text).

This appears to be an outrageously complex execution plan for such a simple query. The query reads from a single table, with no filters, no joins, and no ORDER BY. And yet the execution plan uses two join operators and a sort, plus a total of three Table Spool operators.
Time to jump in at the deep end and see what is going on in this execution plan!
Let’s start at the very beginning
 … And that beginning is in this case the far right of the top branch of the execution plan. Obviously, just as every other execution plan, this plan really starts executing at the top left. The SELECT pseudo-operator calls Nested Loops #0 requesting a row. Nested Loops then requests a row from Table Spool #1 and this continues until the far end of the upper branch: Clustered Index Scan #4. But this is where the real action starts, as this operator reads a row from the SalesPerson table and returns it. The Ordered property is set to False because the optimizer does not care about order. No surprise, since the rows are immediately fed into a Sort operator (#3).
… And that beginning is in this case the far right of the top branch of the execution plan. Obviously, just as every other execution plan, this plan really starts executing at the top left. The SELECT pseudo-operator calls Nested Loops #0 requesting a row. Nested Loops then requests a row from Table Spool #1 and this continues until the far end of the upper branch: Clustered Index Scan #4. But this is where the real action starts, as this operator reads a row from the SalesPerson table and returns it. The Ordered property is set to False because the optimizer does not care about order. No surprise, since the rows are immediately fed into a Sort operator (#3).
After receiving this first row, Sort #3 will store it in memory and then immediately call Clustered Index Scan #4 again. This repeats until the entire table has been read, delivered to Sort #3, and stored in memory. (I am not going into the details of spills at this time). Once all data is memory, the operator sorts the rows.
The properties of Sort #3 shows that this sorting is done by TerritoryID. It is not a far stretch to assume that this is done to prepare for calculating the total SalesYTD for each territory, as specified in the PARTITION specification of the OVER clause. However, at this point this is an educated guess. I need to keep in mind while inspecting the rest of the plan that I might be wrong.
All this work, fetching all 17 rows and sorting them by territory, has to be done first. Once done, Sort #3 can finally return the first row to Segment #2. That’s why Sort is considered a blocking operator. If the input of the Sort is a huge tree of joins between large tables that takes 5 minutes to evaluate, the blocking behavior means that 5 minutes will pass before the first row is returned from the Sort. Later requests require less work: once the sorted results are in memory, each subsequent call can immediately be returned.
The sorted rows are delivered to Segment #2. I recently blogged about this operator so I will not spend a lot of words in this. Its property list shows that it is adding a segment column Segment1002 which marks every row where the TerritorySales is not equal to the previous row. This, too, appears to be related to the PARTITION specification in the OVER clause (but the same caveat applies).
Table Spool #1
So far, I have not covered anything special or unusual. It may not yet be perfectly clear why this work is being done, but it’s not hard to see what these operators do.
The actual fun starts at Table Spool #1. We have seen a Table Spool before but I need to provide a bit extra context here. According to the available documentation and other resources, Table Spool has two logical operations: Lazy Spool and Eager Spool.
An Eager Spool operation is blocking, just as the Sort we saw before. It first consumes its entire input and stores it (in a worktable, unlike Sort which uses memory). After that, it returns those rows, one by one, to its parent operator. The operator can later be initialized again, with the request to produce the same set of rows (“rewind”). In that case it will produce them by reading from the worktable. It can also be initialized again as a rebind, meaning that the worktable is emptied, and it again requests rows from its child, stores them, and returns them after processing the entire input.
A Lazy Spool has the same basic functionality of storing the rows it reads into a worktable, from which it can then later return the same rows again. Unlike an Eager Spool though, a Lazy Spool is not blocking. It will not try to fill the entire worktable first. It simply requests a row, stores it, and returns it; then repeats that for the next row. The rebind and rewind functionality are exactly the same.
This Table Spool is marked as a Lazy Spool, so it is non-blocking. The properties show a single execution, which is a rebind (which is always the case for the first execution). There are no rewinds, so you might wonder why the optimizer adds the extra work of storing all rows in a worktable when they are not processed a second time. We’ll see that later.
The missing link
However, the actual catch is that the described Lazy Spool behavior does not actually explain how this execution plan works. One essential piece of the puzzle is missing. It took me well over a year (and for the record, I was not investigating on a daily basis!) before I finally realized what I missed. The key clue for this was in the rowcounts, as shown in the screenshot below (edited for readability).

A Table Spool, working in Lazy Spool mode, and executed exactly once, would normally always return exactly as many rows as it receives. That is not the case here. It reads 17 rows, which corresponds to the number of rows in the input data. However, it returns just 12 rows. If you look at the results of the query, you might notice that this number is equal to the number of distinct TerritoryID values plus one.
After looking at multiple other execution plans with this pattern, it is clear that the number of rows going in the Table Spool is always equal to the data size, and the number of rows it returns is always equal to the number of distinct values of the PARTITION BY column (or columns). That can’t be a coincidence!
Segment aware
At this point I realized that the only possible explanation can be that the Table Spool operator is segment aware. As explained in an earlier post, an operator that is segment aware changes behavior if it is bound to a segment column. In plans with multiple Segment operators it can be a challenge to figure out which segment column it is bound to because this is not in any way represented in the execution plan. But in this simple case there is only one option. The Table Spool operator can only be tied to the segment column produced by Segment #2.
When tied to a segment column, Table Spool works in a way that falls somewhere in between the Lazy Spool and Eager Spool behaviors. When called, it repeatedly calls its child node to get a row, similar to an Eager Spool. However, instead of processing the entire input, it only processes a single segment. After it receives (and stores in its worktable) all rows for a segment, it then returns just a single row to its parent. This single row represents the entire segment.
So when execution of this query starts and Table Spool #1 is called the first time, it calls Segment #2 to grab a row and store it, then repeats that until a new segment starts. We know from the results that the first segment represents all rows with TerritoryID NULL, of which there are three. Those three rows are read and stored, and then a single row to represent the segment for TerritoryID NULL is returned to Nested Loops #0. That operator then uses its inner (lower) input to produce the full set of three rows for the segment (as will be described below). After that Nested Loops #0 once more calls Table Spool #1, which clears the worktable and then repeats the process for TerritoryID 1.
Nested Loops #0
 So far we have established that the outer (top) input of Nested Loops #0 produces one row for each segment/territory. This implies that the inner (lower) input executes once for each segment. Since this operator returns its data directly to the SELECT pseudo-operator, it has to return the final result set. With one row per segment coming from the outer input, this means that the full result set (except, perhaps, the TerritoryID column) has to come from that inner input.
So far we have established that the outer (top) input of Nested Loops #0 produces one row for each segment/territory. This implies that the inner (lower) input executes once for each segment. Since this operator returns its data directly to the SELECT pseudo-operator, it has to return the final result set. With one row per segment coming from the outer input, this means that the full result set (except, perhaps, the TerritoryID column) has to come from that inner input.
Before diving into the details of that inner input, I want to point out one oddity of this Nested Loops operator. Normally, a Nested Loops operator will have either an Outer References property or a Predicate property. This one has neither.
An Outer References property lists the columns that, coming from the outer input, are pushed into the inner input. Every time these values change, the logic in the inner input ensures that a different set of rows is returned: only the rows that are correct matches for these columns. Because the inner input is custom-tailored, the operator can assume that every row returned is a match; no Predicate property is needed.
When no Outer References property is present, nothing from the outer input is pushed into the inner input. Except for concurrency issues (and one specific case that I’ll address shortly), the same rows will be returned over and over. In this case, the Predicate property is used so the Nested Loops operator can distinguish matching from non-matching rows.
In this case, Outer References and Predicate are both missing. This is normally only seen for a cross join. However, I have looked at the output and I am pretty sure that it’s not eleven identical copies of any data. This execution plan is a very specific case where, without Outer References, each execution of the inner input still returns different data. This is accomplished by the segment-aware operation of Table Spool #1 in combination with the two Table Spool operators in the lower input.
Inner input of Nested Loops #0
For understanding the inner (bottom) input of Nested Loops #0, I will track first execution in detail. This is for the first segment, TerritoryID NULL, consisting of three rows.
When the inner input for this segment starts, Nested Loops #5 is called. This operator then calls its outer input. Compute Scalar #6 calls Stream Aggregate #7, which in turn calls Table Spool #8.
Table Spool #8
 In the description of the Table Spool operator above I state that it requests data from its child nodes, stores it in a worktable, and returns this data. Possibly multiple times. But Table Spool #8 does not even have a child operator. So where does this operator get its data from?
In the description of the Table Spool operator above I state that it requests data from its child nodes, stores it in a worktable, and returns this data. Possibly multiple times. But Table Spool #8 does not even have a child operator. So where does this operator get its data from?
This is in fact yet another way that Table Spool can operate. There is, as far as I know, no official name for this. I call it a Table Spool operating in “consumer-only” mode, because it consumes data from a worktable that is produced by another Table Spool. You can also see this in the properties. The presence of a Primary Node ID property indicates that this is a consumer-spool. The value of this property indicates which spool’s worktable it uses. In this case the value is 1, so Table Spool #8 returns data from the worktable that is created by Table Spool #1.
We saw earlier that, for the first segment, Table Spool #1 contains three rows. The three rows in the input table that have TerritoryID NULL. When Table Spool #8 is called it returns the first of these rows. When called again it returns the second, and so on. On the fourth call it returns an end of data signal.
Stream Aggregate #7
Table Spool #8 returns its rows to Stream Aggregate #7. In this execution plan, this Stream Aggregate operator has no Group By column. This means that it produces a scalar aggregate, a single row with aggregated data for the entire set. The Defined Values and Output List properties expose that it computes and returns the number of rows (3) and the sum of the SalesYTD values in these three rows.
The function of this operator in this area of the execution plan is very similar to the Stream Aggregate I discussed in the first plansplaining post, so I will not go into details here.
Compute Scalar #6
 The single row with aggregated values for the current segment is then passed to Compute Scalar #6. This operator is not very interesting either. The only interesting property is Defined Values. This shows that the only reason this operator exists is to check how many rows are in the current segment. If this number is zero, the result of the sum of all SalesYTD values is changed from whatever the Stream Aggregate operator returns for an empty set to
The single row with aggregated values for the current segment is then passed to Compute Scalar #6. This operator is not very interesting either. The only interesting property is Defined Values. This shows that the only reason this operator exists is to check how many rows are in the current segment. If this number is zero, the result of the sum of all SalesYTD values is changed from whatever the Stream Aggregate operator returns for an empty set to NULL. This is defined as the correct result of a SUM function on an empty set.
Nested Loops #5
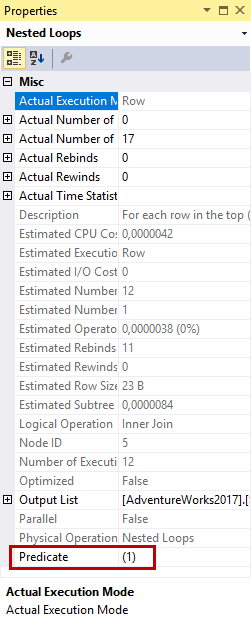 For this first segment (and for every other segment, for this is how Stream Aggregate works when doing scalar aggregation), the outer input of Nested Loops #5 returns just a single row. This row contains the total of all SalesYTD values for the current segment (in this case for the three rows with TerritoryID
For this first segment (and for every other segment, for this is how Stream Aggregate works when doing scalar aggregation), the outer input of Nested Loops #5 returns just a single row. This row contains the total of all SalesYTD values for the current segment (in this case for the three rows with TerritoryID NULL). This single row then drives the inner input of Nested Loops #5, which will add back the original detail data (as I’ll show below).
There is an intriguing difference between the two Nested Loops operators in this plan. Both need to join their outer input to each of the rows from the inner input. In both cases the Table Spool magic ensures that even though there is no Outer References property, the inner input actually changes to the correct set of rows on each next execution. So both these Nested Loops operators need neither Outer References nor Predicate. And yet, they are not the same.
If you look at the properties of Nested Loops #5, you will see that it actually does have a Predicate property. However, the value of this property is a simple constant value: 1. So where Nested Loops #1 has no Predicate to ensure that each row is a match, Nested Loops #5 uses a Predicate with a constant value that converts to the logic value true to achieve the same effect.
Please do not ask me why the optimizer chooses to use these two different techniques to achieve the same effect.
Table Spool #9
The last operator in the execution plan is Table Spool #9. Looking at its properties (not included in this blog post as it would be very repetitive), you can see that this operator also leeches on the hard work done by Table Spool #1. So this operator, again, reads and returns (upon three consecutive calls) the three rows for TerritoryID NULL that were originally read from the base table and stored in a worktable by Table Spool #1.
The Output List property of this Table Spool shows that it returns the three columns we need from the base table in the final output: BusinessEntityID, TerritoryID, and SalesYTD.
We already saw that the outer input of Nested Loops #5 produces a single row with the total sales for TerritoryID NULL. The inner input then, using this consumer Table Spool, adds the three original rows to that. This in effect produces the first three rows of the result set.
Nested Loops #5 returns these three rows (as always, one at a time) to Nested Loops #1. That operator returns them to SELECT so they can be passed to the calling client..
The next iteration
So far, Nested Loops #0 requested and received a single row from its outer input. After a lot of processing that row was returned; we have seen that this row represents the segment for TerritoryID NULL. Nested Loops #0 then requests rows from the inner input. The first three calls produced rows that are part of the result set. The fourth call results in an end-of-data signal. At this point Nested Loops returns to the outer input to request the next row.
I already described how the entire outer input works. The request bubbles down to the Sort operator. (The Clustered Index Scan operator is not used this time. Sort already has all its data in memory so it simply returns the next row when called). All rows for the next segment, for TerritoryID 1, will be stored in the worktable (after clearing out the previous contents) and a single row to represent this segment is returned to Nested Loops #0.
When that operator then once more requests rows from its inner input, the same operators will do the same thing as before. However, because the content of the spooled worktable has been changed in between, those operators now produce different results. This is how, even without an Outer References property, the Nested Loops operators in this execution plan manage to receive a different set of data for every execution of the inner input.
Loose ends
When it comes to execution plans, I am a sucker for details. (Cue sounds of faked surprise from the readers).
The description above sounds very logical. But does it really match with all the details you can glean from the execution plan? Here is the bad news: it doesn’t. Upon very critical inspection, two issues stand out. One is related to the Output List property of the Table Spool operators. The other is related to the Actual Number of Rows returned by Table Spool #1.
Let’s investigate these loose ends and see if there is a logical explanation.
Output List
 The screenshot on the left shows the Output List property of Table Spool #1. The TerritoryID column is expected: the row returned represents a segment, which equates to a single TerritoryID value. The other columns are surprising. Given that there are for example three rows for the
The screenshot on the left shows the Output List property of Table Spool #1. The TerritoryID column is expected: the row returned represents a segment, which equates to a single TerritoryID value. The other columns are surprising. Given that there are for example three rows for the NULL segment, which of the three rows are these values taken from? And why are the other rows not used?
Look at the rest of the plan, and you’ll see that Nested Loops #0 receives identical-named columns from its other input. It then returns columns of these names to its parent. It is in my experience very rare to see duplicated column names in execution plans that do not actually refer to the exact same data, but this is an example where this does happen. I must admit that I do not know how Nested Loops #0 picks which of the two BusinessEntityID, TerritoryID, and SalesYTD columns it returns. But I do know that, at least in this case, it always picks the inner input for at least the BusinessEntityID and SalesYTD columns. That is the only way this execution plan makes sense.
This implies that the columns that Table Spool #1 returns to Nested Loops #0 are effectively ignored. Actually returning them appears to be a waste. Why is this done?
Looking at the other Table Spool operators, they all have the exact same Output List. Totally expected for Table Spool #9: this is the spool that adds back the original rows so all these columns are in fact needed. For Table Spool #8, though, only SalesYTD would be needed; none of the other columns are used by or returned from its parent operator (Stream Aggregate #7). Again, an (admittedly small) waste of work to return more columns then needed.
My guess is that this is just a technical limitation of the Table Spool operator. There is no property to define which columns to store in the worktable. It makes sense to assume that the Output List property does double duty for this operator: it defines the columns returned as well as the columns stored in the worktable. That would explain why Table Spool #1 has no other option but to return all three columns, even though they are not used. For Table Spool #8, which consumes the worktable produced elsewhere, a further speculation is needed. My guess is that this is a further limitation, or rather the reverse of the previous limitation: The Output List always has to be equal to the set of columns stored in the worktable.
The extra row
 The other loose end is in the number of rows returned by Table Spool #1. In the above explanation, I describe the segment-aware operation of Table Spool as storing the entire segment in its worktable and then returning just a single row to represent that segment. However, there are eleven distinct values of TerritoryID in the data (each of the numbers 1 to 10, plus
The other loose end is in the number of rows returned by Table Spool #1. In the above explanation, I describe the segment-aware operation of Table Spool as storing the entire segment in its worktable and then returning just a single row to represent that segment. However, there are eleven distinct values of TerritoryID in the data (each of the numbers 1 to 10, plus NULL), and the actual number of rows returned by Table Spool #1 is twelve. Where does that extra row come from?
I must admit that I have not (yet?) figured this out completely. At this point I have two possible theories.
The first theory is that this is just a bug. Table Spool #1 detects that a segment is complete when it reads a row with the segment column set. However, this is actually already the first row of the next segment. This row cannot go into the worktable yet (that would cause incorrect results from the rest of the query), so it has to temporarily store that row in memory. It then first returns a row for the previous segment. When called again, it empties the worktable, stores the row from memory in it, and then proceeds to request the next row.
However, the very first row it reads also has the segment column set. In this case there is no previous segment. Properly coded, this first segment needs to be handled as a special case. But what if this special case was forgotten? It would return a row to represent the (non-existing) previous segment – and no, I do not know what values would be in the columns it returns. That row would then drive an execution of the inner input of Nested Loops #0. Since the worktable is empty, Table Spool #8 returns nothing; this then results in Stream Aggregate #7 and Compute Scalar #6 also returning nothing, so Nested Loops #5 would not even bother to call Table Spool #9 anymore.
All the numbers in the execution plan (both the Actual Number of Rows and the Number of Executions properties of each operator) match up with this explanation. There is but one oddity, though. A scalar Stream Aggregate that reads no rows would normally still produce a single row as its output (just do a SELECT COUNT(*) on an empty table and look at the execution plan to verify). This one doesn’t. The Number of Executions is 12, but the Actual Number of Rows is 11, so it returns nothing in this case. There is nothing in the execution plan, not even in the full XML, that tells the operator to behave different than a “normal” scalar Stream Aggregate. This is the part I do not understand. If anyone does know why this happens, please post a comment and share your knowledge (or even your theory).
The second possible explanation for the 12th row coming from Table Spool #1 is that this is not a bug, but by design. If that is the case, then a Table Spool running on segmented input apparently is designed to always returns one extra row, before returning the rows that represent the segments. That design would only make sense if there are specific use cases where this row is needed and used to perform some specific work. I have not ever seen this in any execution plan I studied, so I have no way to even speculate on the reason for this. If you, reader, have any speculation here, or if you have ever seen an execution plan that gives you reason to believe that extra row is used, please let me know in the comments section!
The rest of the above explanation still applies. The extra row is returned to Nested Loops #0, which invokes its inner input; that inner input ends up returning nothing because Table Spool #8 cannot produce rows from an empty worktable.
Seeing it in action
The video below (double-click to enlarge) visualizes all of the above. Don’t pay attention to the two extra Compute Scalar operators, these are used for the computations I added in order to slow down the processing sufficiently to create this animation.
If you watch the animation, you can see most of what I describe above in action. The first phase is when Clustered Index Scan #4 reads all its rows and returns them to Sort #3. Once done the sorting happens (not slowed down and not visible in the animation) and then the second phase starts.
Due to where I placed the delay, you now miss some of the action as some numbers jump up immediately: 4 rows returned from Sort #3 (all rows for the first segment plus the fourth row, the start of the second segment that tells Table Spool #1 that the first segment is complete), 2 rows returned by Table Spool #1 (the first for the “bug or unknown feature” empty segment, and the first real segment), and you see stuff happening in the lower part of the execution plan. This is in fact already the second execution. Because the first execution processes no rows, it is not affected by the delay and you cannot see it happening. We can infer that it has happened by looking at all the numbers.
After that you see the same process repeat a few more time: a few rows (for a single segment) flowing from Sort #3 through Segment #2 to Table Spool #1, one row returned from Table Spool #1 to Nested Loops #0, and then the inner input of that Nested Loops reading the rows for that segment from Table Spool #8, and then again from Table Spool #9.
Conclusion
This was an extremely long post, even by my standards. If you are here, you either skipped parts (Boo! Hiss!); or you actually read it all (Applause!). Well done!
The main takeaway of this post is that Table Spool is a segment aware operator. When bound to a segment column, it eagerly builds a worktable for a single segment, returns one row to represent that segment, then clears out the worktable and builds it again for the next segment.
In this specific case, other Table Spool operators on the inner side of a Nested Loops join were reading data from that same worktable. Even though the Nested Loops join did not have an Outer References property, so no values were pushed down to change the results returned by the inner input, the ever-changing data in the worktable resulted in the same effect.
Next month will be shorter, I promise. In episode 7, I will look at an execution plan that uses what perhaps is one of the simplest operators in existence, Constant Scan, in a rather creative pattern.
But let me repeat my standard closing paragraph: I do not want this series to be about only my interesting plans. Reader input is greatly encouraged! If you have ever run into a pattern in an execution plan that appeared to make no sense until you dug into the gory details, or even into a pattern that still makes no sense to you, let me know and I will consider it for inclusion in a future post.






{kind=link}
{kind=link}
2 Comments. Leave new
[…] I will not explain the exact way this part of the plan works, because I have already done so in part 6 of the plansplaining series. And if you experiment with the query, you will see that you get the same plan shape regardless of […]
[…] then you might even have recognized the execution plan as one I have already discussed at length here, and mentioned again […]