This is part eight of the plansplaining series. Each of these posts takes an execution plan with an interesting pattern, and details exactly how that plan works.
In this post we look at a query that, given the known limitations of the available join operators, appears to be impossible to execute. But it’s a legal query so it should run. And it does. But how?
Sample query
The query below can be executed in any version of the AdventureWorks sample database. Don’t bother understanding the logic, there is none. It is merely constructed to show how SQL Server handles what appears to be an impossible situation.
SELECT d1.Name, d2.GroupName
FROM HumanResources.Department AS d1
FULL OUTER JOIN HumanResources.Department AS d2
ON d2.DepartmentID > d1.DepartmentID;
If you look at the descriptions of the various join operators in the Execution Plan Reference, you will see that this query poses the optimizer for what appears to be an insolvable problem: none of the join operators can be used for this query!
The Nested Loops algorithm can only be used for inner join, left outer join, left semi join, or left anti semi join. A right outer join or right [anti] semi join in the query can still use Nested Loops if the optimizer can reverse the inputs. But this query calls for a full outer join, which is simply not supported by Nested Loops.
Both the Merge Join and the Hash Match algorithms require at least one equality predicate in the join criteria. This query has just a single join criterium and it is an inequality. So these algorithms are also not eligible for this query. And Adaptive Join (not yet described in the Execution Plan Reference) chooses between the Nested Loops and Hash Match algorithm at runtime, so it suffers from the restrictions of both.
The query is legal syntax and should run. And it does indeed. Let’s look at the execution plan to find out how the optimizer solved this conundrum. (As usual, I have edited the NodeID numbers of each operator into the screenshot for easy reference).
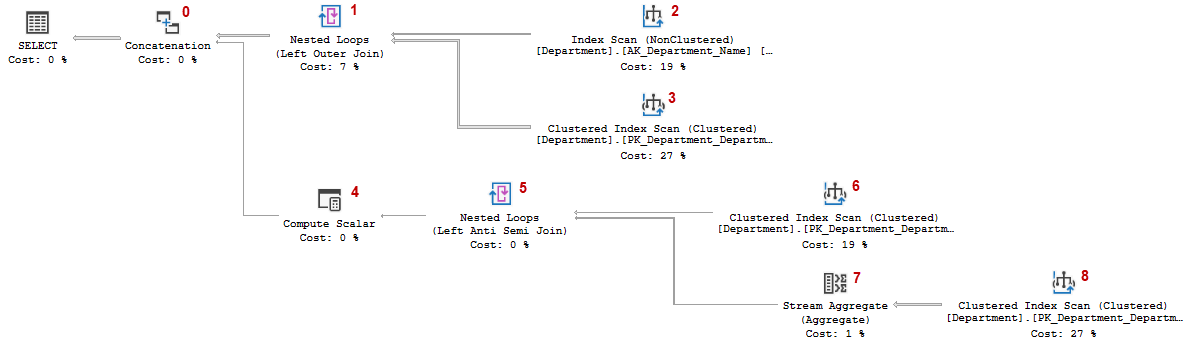
Apparently, trying to make SQL Server do the impossible merely results in making SQL Server do a lot of extra work. Instead of two scans and a single join, as we would expect in most cases of a single two-table join query, we now see four scans, two joins, and some additional extra work. Time to break it down and see what’s going on!
Concatenation #0
The concatenation operator has a quite simple operation. It has two or more inputs and a single output. All it does it request rows from its first input and pass them unchanged; then if the first input is exhausted repeat the same for the second input; and so on until it has processed all of its inputs. In short, it has the same function in an execution plan that UNION ALL has in a T-SQL query, except that UNION ALL always concatenates the results of two queries, and Concatenation can concatenate as many inputs as needed.
In this case there are exactly two inputs, so we can immediately see that the execution plan consists of two independent sub-trees, and their results are concatenated and then returned to the client.
The top input
The first input to the Concatenation operator consists of three operators: Index Scan #2 which reads columns DepartmentID and Name from the table with alias d1; Clustered Index Scan #3 which reads columns DepartmentID and GroupName from the table with alias d2; and Nested Loops #1 to join them together, using logical join operation Left Outer Join.
I am not going to spend much time on this segment of the execution plan. It does exactly what it appears to do: read the two input tables and produce a left outer join result of the data. If you change FULL OUTER JOIN in the original query to LEFT OUTER JOIN, you will get an execution plan that looks exactly like this segment.
The observing reader might already have a clue at this time what is going on. Just think about the definition of what a full outer join should return – basically, the matching rows joined as normal (same as an inner join), plus the unmatched rows from the first table (with nulls for columns from the second table), plus the unmatched rows from the second table (with nulls for columns from the first table). A left outer join, as implemented here, returns exactly the first two items from this list.
The bottom input
Since the first input for Concatenation #0 already returns two of the three items from the list above, the second input should be expected to return the rest: rows from the second table (d2) that have no match in the first (d1). That sounds like a NOT EXISTS in T-SQL terminology, or a left anti semi join in execution plan terms.
Looking at the second input, you can indeed see elements of this expected left anti semi join, but there are a few extra operators as well. So let’s break this down in its parts.
Clustered Index Scan #6
This operator reads DepartmentID and GroupName from the table with alias d2.(This can be seen by reviewing its properties, specifically the Output List property – I decided to not include screenshots of all property lists in this post, merely the more interesting ones).
No big surprises here.
Nested Loops #5
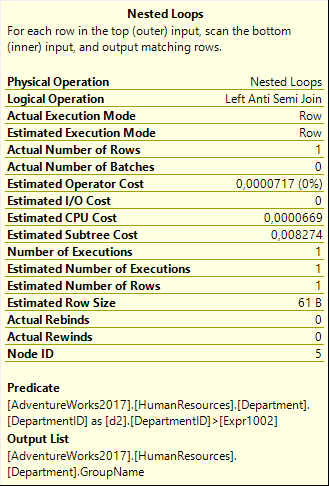 As you can see in the properties, this operator uses logical operation Left Anti Semi Join. This means that it looks for rows in the second input that match a specific condition; if it finds a match the row from the first input is discarded and the scan of the second input is aborted; if the scan completes without finding a match the row from the first input is passed. This is equivalent to using the
As you can see in the properties, this operator uses logical operation Left Anti Semi Join. This means that it looks for rows in the second input that match a specific condition; if it finds a match the row from the first input is discarded and the scan of the second input is aborted; if the scan completes without finding a match the row from the first input is passed. This is equivalent to using the NOT EXISTS keyword in a query.
The properties of this operator reveal that there is no Outer References property. This implies that the inner (bottom) input is “static” – it returns the same set of rows for every row from the outer (top) input. For each of these rows the Predicate property is evaluated to determine whether the row is a match of not.
This predicate reads (simplified) d2.DepartmentID > Expr1002. This is similar to the predicate in our query but d1.DepartmentID has been replaced by Expr1002. Why?
Clustered Index Scan #8
As expected, this operator reads the table with alias d1, returning only the DepartmentID column (which makes sense because for this part of the query the Name column from the d1 table is not needed).
The optimizer has set the Ordered property to false, so the storage engine is free to return the rows in any order it sees fit. (The same is the case for all other scan operators in this execution plan but here it is a bit more relevant as we will see later).
Stream Aggregate #7
 The properties of this operator (no screenshot shown) reveal that there is no Group By property. As explained on the Stream Aggregate page in the Execution Plan Reference, this means that it functions as a scalar aggregate. It returns a single row with the aggregation result of its entire input.
The properties of this operator (no screenshot shown) reveal that there is no Group By property. As explained on the Stream Aggregate page in the Execution Plan Reference, this means that it functions as a scalar aggregate. It returns a single row with the aggregation result of its entire input.
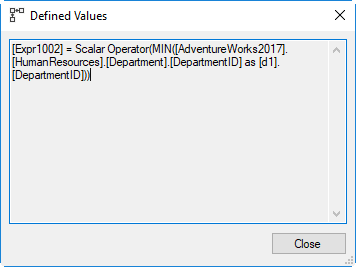
What type of aggregation is used can be seed in the Defined Values property (see screenshot). As you can see, this is where the Expr1002 column we saw referenced in Nested Loops #5 originates from. Simplified by removing unneeded four-part naming, parentheses, and brackets, the expression reads: “Expr1002 = MIN(d1.DepartmentID)”.
Nested Loops #5 (again)
Now that we have seen both inputs and the properties of the join operator itself we can bring these elements together to understand how it works.
All rows from table d2 are read. For each of these, the bottom input returns a single row with the lowest value of d1.DepartmentID, which is then compared to d2.DepartmentID to determine whether or not the row from d2 should be returned.
Since this is a left anti semi join, with a predicate d2.DepartmentID > d1.Department, the transformation to d2.DepartmentID > MIN(d1.DepartmentID) is indeed correct; it does not change the results in any way. It only affects performance. For the query as written, the bottom input of Nested Loops #5 (which executes 16 times) reads 16 rows, finds the minimum value, and then compares that single value to d2.DepartmentID in the join operator. Without the Stream Aggregate operator, it would instead read the same 16 rows, return all of them to the join operator and compare them there. Apparently, the optimizer still estimates that aggregating the data first is cheaper. (I personally doubt this – after all, without the aggregation the lower input would actually stop executing as soon as a match is found; in this case that would almost always be after reading the very first row. But even in other cases it is reasonable to assume that there is at least a non-zero chance of having to read less rows if you compare each row and stop after finding a match, as opposed to first reading and aggregating all rows and only then doing the comparison).
Compute Scalar #4
The final operator to discuss is the Compute Scalar. Looking at its properties, it is easy to see what it does: it simply adds an extra column to each row returned from Nested Loops #5; this column is called (simplified) d1.Name and is set to null.
This makes sense. The Nested Loops operator returns only a single column, d2.GroupName. But Concatenate expects all input data streams to return the same amount of columns, so the equivalent of the d1.Name column must be added before the stream can flow into the Concatenate.
Bringing it together
As already mentioned above, the Concatenation operator effectively combines the results of two independent queries. The first, shown on top in the execution plan, performs a left outer join between the two inputs. This returns two of the three elements that the query asks for: al matching rows (joined as normal), and all unmatched rows from the first table. The bottom input of the query then finds only the unmatched rows from the second table, which the Concatenation operator then adds to the results.
Effectively, the execution plan can be thought of as implementing this query, which is semantically equivalent to the original query though more complex:
SELECT d1.Name, d2.GroupName
FROM HumanResources.Department AS d1
LEFT OUTER JOIN HumanResources.Department AS d2
ON d2.DepartmentID > d1.DepartmentID
UNION ALL
SELECT NULL, d2.GroupName
FROM HumanResources.Department AS d2
WHERE NOT EXISTS
(SELECT *
FROM HumanResources.Department AS d1
WHERE d2.DepartmentID > d1.DepartmentID);
If you execute the query above and look at its execution plan, you will see that this query does indeed have the exact same execution plan as our original query.
Optimization
It may appear wasteful to do two joins and four scans (plus the extra aggregation and concatenation) instead of a single join and two scans. But as explained in the introduction, I forced the optimizer to find a workaround because I submitted a query that simply could not be executed as a single join between two tables, due to limitations in the available algorithms. So in that sense, this is really the best the optimizer could do.
That being said, there certainly is room for improvement. I already mentioned above that I doubt whether aggregating all rows to do just a single comparison in the Nested Loops operator is actually more effective then returning individual rows – especially because a Nested Loops with logical operation Left Anti Semi Join can stop calling rows from the inner input after the first match is found.
There are two other optimizations possible that in this case were probably not done because of the small table size (16 rows for both input tables), but that I have actually seen in execution plans for similar queries on much larger tables. The first is based on the observation that Nested Loops #5 uses a static inner input. This means that it will be the same for each execution – so why compute it over and over again? Why not add a Table Spool operator so that the actual computation of the MIN(d1.DepartmentID) is done only once, storing the result stored in a worktable which can then produce it again every execution without having to recompute it? And also, since DepartmentID is the clustered index key, why not change the Ordered property on Clustered Index Scan #8 to true and add a Top operator, so that only the first row (which by definition stores the lowest DepartmentID value) is returned?
However, my biggest disappointment is that the optimizer even chose to use a static inner input at all. I really would have expected to see a dynamic inner input on Nested Loops #5. The Outer References property would have been set to d2.DepartmentID. And the entire inner input would have been replaced by a single Clustered Index Seek operator on table d1, with its Seek Predicates property set to d2.DepartmentID > d1.DepartmentID. Each execution of this inner input would then navigate the index to the first matching row and either return nothing (if no match exists) or return the first match – and then not be called again so any other matching rows are not returned.
Long story short, I would have preferred to get the execution plan that it is actually produced for the (equivalent) query below:
SELECT d1.Name, d2.GroupName
FROM HumanResources.Department AS d1
FULL OUTER JOIN HumanResources.Department AS d2
ON d1.DepartmentID < d2.DepartmentID;
Conclusion
All join operators have their specific limitations. Due to these, it is possible to write a query that at first glance appears impossible to run. But as long as it is a syntactically correct query, SQL Server has to be able to run it.
In this plan we looked at the hoops SQL Server has to jump to in one of such cases, where the inequality-based join predicate forces a Nested Loops join, but the query ask for a join type that is not supported by Nested Loops. We saw that in this case the query effectively gets rewritten to an equivalent but more complex query that can use supported operators.
I am still open for suggestions on topics to cover in this series. If you see an unusual and interesting pattern in an execution plan, let me know so I can consider using it in a future post!






{kind=link}
{kind=link}
1 Comment. Leave new
[…] Hugo Kornelis has a brain-teaser for us: […]