This is the fifth post in the plansplaining series. Each of these blog posts focuses on a sample execution plan that exposes an uncommon and interesting pattern, and details exactly how that plan works.
In the first post, I covered each individual step of each operator in great detail, to make sure that everyone understands exactly how operators work in the pull-based execution plans. In this post (and all future installments), I will leave out the details that I now assume to be known to my readers. If you did not read part 1 already, I suggest you start there.
In this post I will take a look at bitmaps. Bitmaps are most commonly seen in execution plans for so-called star join queries.
Sample query
The query for this post is very similar to the query we used last month. In fact, the only thing I did was to add two filters to the query; other than that the query is unchanged.
SELECT ds.StoreManager,
dp.BrandName,
SUM(fos.TotalCost)
FROM dbo.FactOnlineSales AS fos
INNER JOIN dbo.DimStore AS ds
ON ds.StoreKey = fos.StoreKey
INNER JOIN dbo.DimProduct AS dp
ON dp.ProductKey = fos.ProductKey
WHERE ds.EmployeeCount < 30
AND dp.ColorName = 'Black'
GROUP BY ds.StoreManager,
dp.BrandName;
If you run this query in ConsosoRetailDW and inspect the execution plan, you will see that the small change in the query has resulted in a small change to the execution plan. The picture below represents the right-hand side of the execution plan, where the data is retrieved, joined, and filtered. (The left-hand side is responsible for grouping and aggregating, a detailed discussion of that process is out of scope for this post).
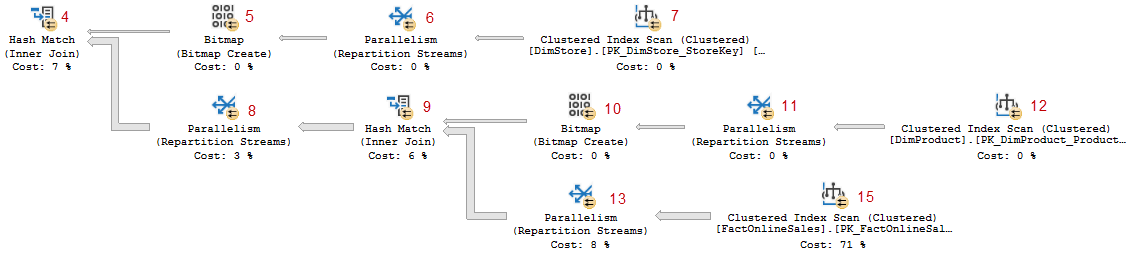
If you compare this picture to the one in the previous post, you will see more similarities than differences. Once you start digging into the properties you will see a few more differences but most of the execution plan is actually the same. Which means I can save a lot of time by not explaining the things that are unchanged.
Where are my filters?
Based on the additional WHERE clause in the query, you might have expected to see one or more Filter operators added to the plan. Or the use of Index Seek operators with appropriate indexes on the EmployeeCount and ColorName columns. But there are no such indexes so the optimizer has no better option than the Clustered Index Scan, and the reason that you see no Filter operator is because the optimizer loves to push predicates as deep into the tree as possible.
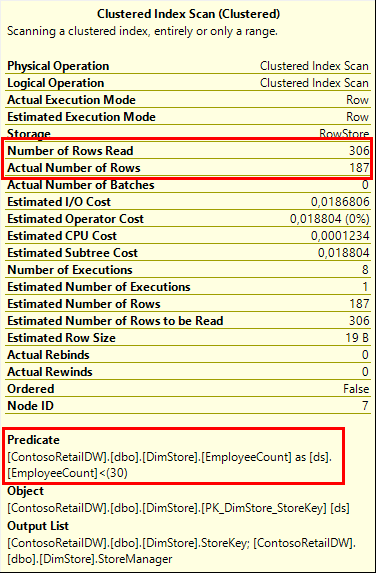 In this case it was able to push the predicates completely into the Clustered Index Scan (the screenshot shown here is for Clustered Index Scan #7, but #12 is very similar). It is still a scan. The storage engine still has to read all rows from the table – 306 in this case as evidenced by the Number of Rows Read property. But the storage engine itself then checks the predicate, and only he 187 rows that match this predicate are then returned to the Clustered Index Scan operator (which then, as usual, returns them to its parent operator).
In this case it was able to push the predicates completely into the Clustered Index Scan (the screenshot shown here is for Clustered Index Scan #7, but #12 is very similar). It is still a scan. The storage engine still has to read all rows from the table – 306 in this case as evidenced by the Number of Rows Read property. But the storage engine itself then checks the predicate, and only he 187 rows that match this predicate are then returned to the Clustered Index Scan operator (which then, as usual, returns them to its parent operator).
If you look carefully, you may notice that the width of the arrows into and out of the two Parallelism operators (#7 and #11) are not the same. In this case you need to look hard to see it, but I have seen execution plans where the difference in width was far more obvious. It appears as if the Parallelism operators return less rows than they receive. That is not the case, though. What you see is the result of a visual bug in Management Studio: when an operator exposes both the Actual Number of Rows and the Number of Rows Read properties, then the arrow width is based on the Number of Rows Read. It represents the amount of work done by the parent operator, but not the amount of data flowing between the operators. Since arrow width normally always represents the amount of rows, I consider this to be highly confusing and I have reported it as a bug.
The bitmaps
If you look back at the execution plan I showed in the previous post, you might realize that just adding these two pushed-down predicates into the two Clustered Index Scan operators would have been sufficient. No other change is needed, and the joining and filtering part of the query would have been very straightforward: read only the small stores and the black products, then read all FactOnlineSales data and join everything. A lot of the rows read from FactOnlineSales would not be for black products or for small stores, so those rows would be removed from the intermediate results after the joins (which are all defined to do the Inner Join logical operation, which removes non-matching data from the results). The end result would be totally correct.
And yet, the optimizer has decided to do something else. It introduces two extra operators, called Bitmap, with “Bitmap Create” as the logical operation. That smells like extra work, and whenever I see something in an execution plan that smells like extra work I want to know exactly what it does so I can understand why the optimizer introduces it.
Bitmap #5 – creating a bitmap
 As implied by its logical operation, “Create Bitmap”, the Bitmap operator creates a bitmap. (I assume that this is the only logical operation that the Bitmap operator supports, since I have never seen a Bitmap operator with a different logical operation). A bitmap is a structure that stores Boolean values for a consecutive range of values in a small amount of memory. E.g. the range from 1 to 8000 has 8000 possible values. These can be represented as 8000 bits in just 1000 bytes. For each value, the location of the corresponding bit can be computed by dividing the value by 8; the dividend is the location and the remainder determines which of the bits to use. The value of that specific bit can then be tested, or it can be set to false (zero) or true (one).
As implied by its logical operation, “Create Bitmap”, the Bitmap operator creates a bitmap. (I assume that this is the only logical operation that the Bitmap operator supports, since I have never seen a Bitmap operator with a different logical operation). A bitmap is a structure that stores Boolean values for a consecutive range of values in a small amount of memory. E.g. the range from 1 to 8000 has 8000 possible values. These can be represented as 8000 bits in just 1000 bytes. For each value, the location of the corresponding bit can be computed by dividing the value by 8; the dividend is the location and the remainder determines which of the bits to use. The value of that specific bit can then be tested, or it can be set to false (zero) or true (one).
The bitmap is named Opt_Bitmap1005 in this case. This name is not exposed in the quick property popup, but you can find in in the full property sheet as shown here, in the Defined Values property. You will also note that this bitmap is not included in the Output List property. That’s because this bitmap is not created for each individual row; there is a single bitmap that accumulates information from all rows. Other operators in the execution plan can reference this bitmap by name, even though it is not passed to them in their input rows.
You will also notice this operator uses hashing (sorry to those who are still recovering from last month…). It has a Hash Keys property, which is set to StoreKey in this case. The hash function here is not the same as the one used in Parallelism operator #6 (see previous post), as the hash function for a bitmap operator needs a much larger range than the eight-value range used to direct rows to threads. It may or may not be the same as the hash function used in Hash Match operator #4; these details are not published by Microsoft and not exposed in the execution plan in any way.
So here is what this operator does. When it is initialized, it creates a bitmap that is large enough for the range of possible results of the hash function, and it sets all bits to false (zero). Then, every time GetNext() is called it reads a row from its input, hashes the StoreKey to find a location in the bitmap, and sets the corresponding bit to true (one). It then passes the row, unchanged, to its parent operator. This repeats until all rows are processed.
Simple example: Let’s say that only three stores in our database have less than 30 employees. These stores have StoreKey 17, 38, and 82. The first row the Bitmap operator receives is for StoreKey 17; it hashes the number 17 and the result is 29, so bit 29 in the bitmap is set to one. It then reads the next row, for StoreKey 38; hashes the number 38 which results in 15; and sets bit 15 to one. The third row it reads is for StoreKey 82; due to a hash collision this number also hashes to 29 so it will once more set bit 29 to one (effectively not changing anything). There are no more rows so the end result will be a bitmap with bits 15 and 29 set to one and all other bits set to zero.
The bitmap is not used here. At this point it appears that SQL Server is doing lots of extra stuff for no good reason at all. Trust me, the reason for this extra work will become clear later.
One final note. I described the above as if this is a single-threaded operation. However, the execution plan runs in parallel. This means that the actual implementation is a bit more complex then suggested here. In fact, I do not even know exactly how a bitmap in a parallel execution plan works. One possibility is that there is a separate copy of the bitmap for each thread; each instance of the Bitmap operator then writes to its own copy without interference from the other threads, but operators that read the bitmap must then combine the bitmaps from all threads. Another possibility is that there is a single copy of the bitmap that is used by all threads at the same time; this necessitates additional complexity to ensure that the threads do not run into race conditions as they update the bitmap, but makes reading from the bitmap a lot simpler.
Clustered Index Scan #15 – using the bitmaps
I will now skip a lot of the steps in the execution plan. The two Hash Match operators, the Clustered Index Scan on the DimProduct table, and all the Parallelism operators, are all already explained in the previous post. And Bitmap operator #10 is doing effectively the same as Bitmap operator #5, except that in this case the hash is computed off the ProductKey column and the resulting bitmap is called Opt_Bitmap1004.
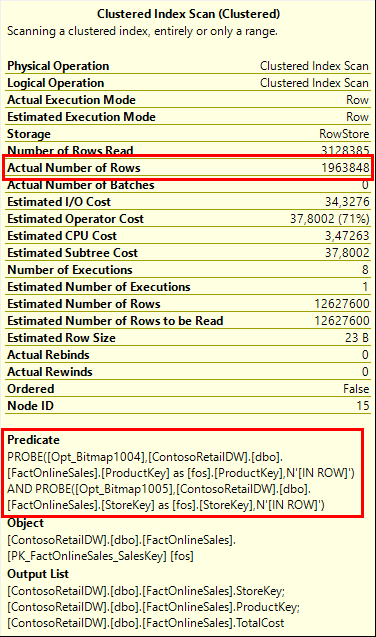 To understand why these two Bitmap operators are included, I will focus on the Clustered Index Scan operator (#15) that actually uses these operators. If you look at its properties, you see that this operator now also has a Predicate property. You would have expected this if the query contained any direct filter on any columns from this table but that is not the case. And the predicate looks different from what you normally see. There are two conditions here. After removing some extra parentheses and brackets and simplifying the tablename references, the second one reads “PROBE(Opt_Bitmap1005, fos.StoreKey, N'[IN ROW]’)”. But what exactly does this mean?
To understand why these two Bitmap operators are included, I will focus on the Clustered Index Scan operator (#15) that actually uses these operators. If you look at its properties, you see that this operator now also has a Predicate property. You would have expected this if the query contained any direct filter on any columns from this table but that is not the case. And the predicate looks different from what you normally see. There are two conditions here. After removing some extra parentheses and brackets and simplifying the tablename references, the second one reads “PROBE(Opt_Bitmap1005, fos.StoreKey, N'[IN ROW]’)”. But what exactly does this mean?
A PROBE function call in a predicate means that the operator has to verify a bitmap for each row. The first parameter specifies the bitmap. In this case it is Opt_Bitmap1005, which was created by Bitmap operator #5. The second parameter indicates which column should be hashed to find a bitmap location. If the third parameter is “IN ROW”, this means that the actual processing of this PROBE check is done within the storage engine, before returning the row to the operator. Without this IN ROW indication, all rows would be returned from the storage engine to the operator and the operator would then check the bitmap to determine whether or not the row is passed.
Earlier in this post I walked through the bitmap creation process with a simplified example using just three stores with less than 30 employees: 17, 38, and 82. This resulted in a bitmap with bits 15 and 29 set to true and all others set to false. Let’s now see how this bitmap is used as some of the rows from the FactOnlineSales table are read. The first row has StoreKey value 29. This value is hashed and the result is 46; the storage engine checks bit 46 in the bitmap and sees that it is false. This row is rejected and not returned to the scan operator; the storage engine immediately moves to the next row. This second row has StoreKey 38. We already know that 38 hashes to 15, and since bit 15 is set this row qualifies. Assuming it also qualifies the second PROBE predicate, it will be returned to the Clustered Index Scan, which then returns it to its parent. This row will now traverse through all the join operators and end up in the aggregation part of the execution plan, as it should.
A PROBE predicate can also produce false positives. Let’s continue our example with the third row, which is for StoreKey 65. There happens to be a hash collision between 38 and 65, so the value 65 also has 15 as its hash result. This row, too, will qualify and be returned (again assuming the second PROBE predicate allows it to pass as well). But this will not result in incorrect results. The row will be joined to some Product data in Hash Match #9, but in Hash Match #4 there will be no row from DimStore that matches StoreKey 65, so the row will still not be returned.
False negatives are not possible. If a FactOnlineSales row has a StoreKey value of 17, 38, or 82, the result of the hash function will always be 15 or 29; these bits are set so these rows will all qualify. And similarly, if they are for black products then they will also qualify the other PROBE predicate, so these rows will certainly be returned,
So what the two PROBE predicates in this query effectively do is: use a hash on both the StoreKey and the ProductKey to find a location in the two bitmaps, then check to see if that location is a hash value with at least one qualifying store or product. All qualifying rows will always match this filter. Some non-qualifying rows might also match, due to hash collisions, so the rest of the query still has to ensure that these are removed. (In this case that happens automatically due to the inner joins; sometimes an explicit Filter operator is used for this). But most non-qualifying rows will be removed in the scan.
As you see in the screenshot above, only 1.9 million rows were returned from the Clustered Index Scan, instead of the 12.6 million that would have been returned if the optimizer had chosen not to use bitmaps in this case. (And in case you wonder about false positives: I checked and there were exactly 9 of them for this quey – that is how infrequent hash collision are in the actual hash functions used).
In the screenshot above you may also notice a confusing Number of Rows Read property. The operator is a scan; it really reads all rows from the table. If you run the query with SET STATISTICS IO ON, you will see a number of logical IOs that matches the number of pages in the table. Trust me on this, the Clustered Index Scan operator #15 really reads all 12.6 million rows that are in this table and the reported number is wrong. I have filed a bug report for this.
Wrong estimate?
The wary reader might have noticed in the last screenshot that there is a huge difference between the estimated and the actual number of rows. The estimate is 12.6 million – that is, it is equal to the number of rows in the table. Looking at the execution plan it appears as if the optimizer estimates that every row in the table will match the bitmaps and be passed on to the parent operators. But based on that estimate, why would the optimizer even bother? If that estimate were correct, the bitmaps would not provide any cost saving, while still introducing extra overhead in the execution plan.
But there is more. If you look at Parallelism operator #13, you will see that this operator has a much lower estimated number of rows: just 1.5 million. But there is no predicate on this operator, so how can the optimizer estimate that this operator, that without predicate would always pass along each row unchanged (just on a different thread) would reduce the number of rows from 12.6 million to 1.5 million?
The answer to these questions have to do with the exact sequence of steps the optimizer takes when creating an execution plan. Most of the decisions are taken during the main optimization phases. But once a plan has been chosen, a final “cleanup” phase runs. And one of the things this cleanup phase does is: pushing PROBE filters down into a scan where this is possible.
So here is what the execution plan would have looked like if the cleanup step had not pushed this probe filter into the clustered index scan (sorry for the switch to the old execution plan artwork, but I spent two hours doctoring up a fake screenshot a few years back and I don’t feel like repeating it).
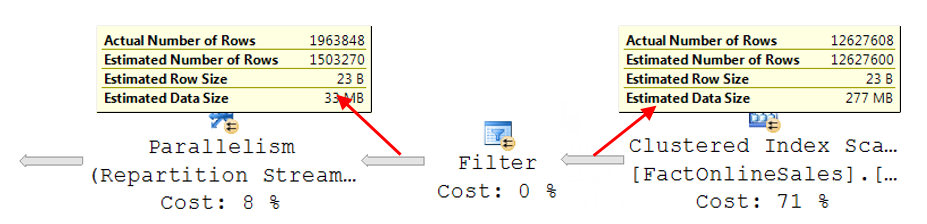
The Clustered Index Scan reads the entire table and returns all rows, because no filter is pushed down (yet). The estimate matches that (to six digits accuracy). The filter then applies the bitmaps to reduce the rowcount to 1.9 million, with an estimate of 1.5 million, which is within the normal margins of error. The Parallelism operator does not affect the estimated or actual row count at all, as expected.
But the cleanup step does execute. It realizes that the probe in the Filter operator can be pushed into the Clustered Index Scan. And now the Filter itself does nothing so it is removed. And the Microsoft developers who built this didn’t take the extra steps to change the original estimate of 12.6 million rows for the Clustered Index Scan to the 1.5 million rows that were actually estimated to be remaining after the filter. Probably because they figured that the estimated number of rows is only relevant for plan selection, which by this time has already concluded. Maybe someone should tell them that consultants actually look at estimated and actual row count as part of their tuning?
Credit where credit is due: I did not know the above, and I probably never would have found out, until a few years ago Paul White (b|t) explained the process. I do not know if this was in a blog post, in an email, or in any other way. I have tried to find the source (and link to it if possible) but I was unable to. That’s why I decided to reproduce it. If Paul’s explanation of this process is available somewhere, then please indicate this in a comment and I will update this post with a link.
Conclusion
In this post I looked at the execution plan of a query that joins two dimension tables to a fact table, with filters on the dimension tables. Because the filters are not directly on the fact table, normal methods of pushing down predicates work only for the dimension tables. But the fact table is the large table, with millions of rows – this is where you WANT pushdown to happen!
In order to make that possible, SQL Server uses bitmaps. The Bitmap operators that create the bitmaps use hashing to map the values that are needed to a hash value, then set a bit in the bitmap to mark that value as “required”. Now the Clustered Index Scan on the large fact table can use the same hash function on the corresponding columns, check the bit in the bitmap, and thus filter out a huge amount of data very early. There is still the risk of “false positives” due to hash collisions, so the rest of the execution plan still has to implement any filters that the query requires.
There is a cost associated with this pattern. There is some additional startup cost, reason why you will never see this pattern when querying small tables. The Bitmap operators take time, and the bitmap itself uses up memory. Plus, the probe action in the clustered index scan also uses CPU cycles as the hash function has to be executed for each row. But if sufficient rows are filtered out early, then the cost saving in the rest of the plan, where now far less rows are processed, greatly outweigh that cost.
This post illustrates the most common usage of bitmaps (and hence the Bitmap operator) in SQL Server execution post. There are other situation where bitmaps are used. The PROBE function is often used in the predicate of a scan, but I have seen it on other operators as well, so make sure to find exactly where each bitmap is created and where it is then used if you want to understand what a bitmap is used for in each specific plan.
This post was a small diversion from the normal style of my plansplaining posts, because it focuses mostly on a single operator. Next month I will return to the normal style. I will look at a query that uses the OVER clause to get aggregated data and detailed data in a single result set. Each of the operators used in its execution plan by itself is relatively easy to understand, but their interaction is very complicated.
But let me repeat this: I do not want this series to be about only my interesting plans. Reader input is greatly encouraged! If you have ever run into a pattern in an execution plan that appeared to make no sense until you dug into the gory details, or even into a pattern that still makes no sense to you, let me know and I will consider it for inclusion in a future post.






{kind=link}
{kind=link}
9 Comments. Leave new
[…] Hugo Kornelis explains what the Bitmap operator is in an execution plan: […]
Great post! This was one of the blanks with regards to query plan operators I had yet to fill in. Thanks!
Thanks, Daniel! I am happy to hear that you benefited from my post!
One year later, this still is an awesome post that just saved my day 🙂
The explanation about apparent estimate mismatches was really helpful — thank you!
Excellent article. When will Probe on a scan be “IN ROW” and not “IN ROW”?
Hello there.
Thanks for the great post. Bitmap and probing are probably one of the most thing confusing me so far since I started my career as a data engineer.
But what I think is that, with bitmap creation and probing in clustered index scan operator, it is in fact just that the CPU time of hashing just moves from the join operator to the scan operator. The CPU time for the Scan operator will increase while the CPU time of join operator will decrease. I believe the total time for (just) joining will be the same, or even it will increase, because there is a lot of overhead.
What I believe is that the real purpose of the bitmap operator is to reduce the numer of data that needs to be REPARTITIONED (in the Repartition Stream operator). Moving that large amount of data between thread is indeed costly. First you have to hash the key to determine where the rows should go, and also the cost of moving data around the threads. That is the reason why, bitmap never appears on a single threaded hash join, even it is joining a very big table.
Thanks for your comment, Thuan! I am glad you found my post to be helpful.
You are right that the cost of the hash computation just moves. That computation still has to be done, just now in the Clustered Index Scan. We can’t remove that, ever.
But the savings are more than only the Repartition Streams. There are multiple savings.
1. The Clustered Index Scan itself. Since the bitmap probe test is pushed into the storage engine, rows that don’t match are not even returned from the storage engine to the operator. So it’s not the operator that asks the storage engine to read a row, receives the row, rejects it and asks another rows; it’s the operator that asks the storage engine to read a row, the storage engine reads a row, rejects it immediately, then reads the next and only returns those that match. That saves a few CPU cycles and context switches between storage engine and operator.
2. Rows returned by the Clustered Index Scan. In a row mode execution plan, every row returned by the operator to its parent operator forces a re-load of the instruction cache at the CPU level. This is costly. (One of the reasons why batch mode execution can run so much faster). So reducing the number of rows passed between operators is always a direct cost reduction.
3. Rows to be processed by the Hash Match join. While the computation of the hash function is only moved around and not avoided, we do save the overhead of locating the bucket for the hash value and noticing it’s an empty bucket.
4. And finally, all operators sitting between the Clustered Index Scan and the Hash Match also have to process less rows. In the example here that was only the Parallelism (Redistribute Streams) operator, which is indeed quite costly due to all the synchronisation between threads. But I have also seen plans where there are more (or less) operators between the scan operator that has the pushed down probe and the Hash Match operator.
[…] Quoting: https://sqlserverfast.com/blog/hugo/2018/05/plansplaining-part-5-bitmaps/ […]