Can we please all stop the nonsense? Now?
While I admit that I haven’t seen the literal statement “seeks are better than scans” in a while, I do keep encountering that generic idea, just in other words.
Just as recently as this week, on the very popular blog of my good friend Pinal Dave (who knows I’m writing this post), I read this: “The query was indeed running extremely slow […] even though the main operator on the table was index seek.”
So? What gives you the impression that an Index Seek should give better performance? Is this an artefact of the “seeks are better than scans” myth? And why are you permeating that to your readers?
That blog might have been the catalyst, but it’s not new. I see it too often, far too often.
“Looking at the execution plan, we see an Index Scan, so obviously we start from there”.
“Obviously”? Really?
Of course, the scan might be a problem, if there are signs of it being a problem. The four letters s, c, a, and n, though, are not that sign. So anyone who ever wrote or said something like the above: you too are part of the problem. You too are permeating the myth.
Stop it. Now.
Facts? We dun’ needs no steenkin’ facts round ‘ere
Fact: Microsoft staff are not idiots. And especially the execution plan team has managed to employ some really smart people. When Microsoft builds an execution plan operator, they have good reasons for it. They don’t build operators that are objectively bad and should never be used.
So the mere fact that scan operators exist is already a sign that they are not bad.
Now, people might argue against this that, perhaps, scans are needed in situations where a seek would not be possible, and that’s why they need to be in the product, but that even so it would still be beneficial to ensure that we do get a seek instead of that scan.
Those people would be wrong, though.
Fact: Scans and seeks have different functions.
The function of a scan is to read an index (or table), from a starting point, and then continue reading until either all rows are returned or no more data is requested. This scan can be configured to return rows in index order, or to return rows in any order that is determined the most effective at runtime.
The function of a seek is to find specific values within an index and then either return the matching row only, or return all rows in a range using that value as the starting point and another value as the ending point.
So we have operators that have different functions. And, most likely, queries that have different requirements. Guess what? We also have an optimizer that is usually pretty good at finding the right operator for the task. So next time you see a scan operator, don’t go into a frenzy over seeing that “terrible” operator. Instead, stay calm, look at the query and execution plan, and then you’ll probably realize that there’s a very good reason for that scan operator. And that it’s not the root cause of your misery.
Show me the money demo’s
Fact: You should never blindly trust anything you find on the internet. And right now, you are reading the internet. So why should you trust this?
You shouldn’t. At least, not blindly. You should verify. And what better way to verify then through demos!
(Note: All demos below use the AdventureWorks free sample database).
Selectivity and the tipping point
I think this is the example I see most often in discussions on when seek is better than scan, and when scan is better than seek: the infamous “tipping point”. Let’s look at two almost identical queries, with very different execution plans.
SELECT Title,
FirstName,
LastName
FROM Person.Person
WHERE LastName LIKE 'S%';
SELECT Title,
FirstName,
LastName
FROM Person.Person
WHERE LastName LIKE 'Sa%';

Just adding a single character to the LIKE argument changes the execution plan completely. When we’re searching for last name starting with S, we get a Clustered Index Scan, When we only want names starting with Sa, then we suddenly get a (nonclustered) Index Seek, a Nested Loops, and a Key Lookup.
Why?
This is where the tipping point comes into play. There is an index available that SQL Server can use to quickly access only the range of last names starting with S. Or starting with Sa. Reading a range, that sounds like ideal work for the seek operator. But when using that index, extra work needs to be done. The index tells you where to find the data, but to access the data an additional step is needed: the Key Lookup.
SQL Server will now do a cost comparison. One alternative is the Clustered Index Scan. This is expensive, because the entire table has to be read. But it’s also stable. No matter how many rows the filter selects, the execution plan will always read exactly the entire table.
The other alternative is the Index Seek, which obviously finds the needed rows much, much faster and cheaper. But it does incur the cost of the Key Lookup, which goes up linearly with the number of matching rows.
The cardinality estimator expects that 2,133.55 rows have a last name starting with S. And that only 572.886 of them start with Sa. It then does the math. The very cheap Index Seek plus 2,133.55 executions of the Key Lookup comes up at a higher estimated cost than the Clustered Index Scan. But for an estimated 572.886, the numbers are different and now the Index Seek plus Key Lookup is estimated to be cheaper.
In this math, effectively what’s done is to check whether the restriction on rows returned is selective enough to reduce the amount below the “tipping point” – the estimated number of rows where the two execution plans have equal cost.
You can override these decisions. Add a FORCESEEK hint to the first query, and a FORCESCAN hint to the second, and the execution plans will switch around. But the estimated cost of both queries will go up. And if you execute the queries and compare their actual performance, for instance by looking at the QueryTimeStats property of the execution plan plus run-time statistics (aka “actual execution plan”), or by comparing SET STATISTICS IO output of the two queries, you’ll also see that forcing the different plans causes both queries to execute slower.
Bottom line: In this case, the scan operator was the best operator when it was chosen. And the seek operator was the best operator when that one was chosen. Forcing the optimizer to make a different choice was detrimental to query performance.
Covering index?
At this point, most experts point out that the “solution” to this “problem” is to ensure that SQL Server has a covering index available. I won’t go into the details of that, just type “covering index” in any search engine and you’ll find tons of posts.
But is there really a problem? Do we really need a solution? Didn’t the demos just show that SQL Server is perfectly capable of choosing between the tools available to find the right tool for the job?
Granted, a covering index will always speed up this query, no matter how many and which starting letters of the last name you supply. This query will gain performance.
But at what cost?
Queries do not live in isolation. Making a new covering index adds an index to the database. Changing an existing index to be covering changes that index in the database. Those changes affect other queries, affect database size, compile times, maintenance jobs, and they can definitely also change performance of other queries. Sometimes for the better … but sometimes also for the worse.
It simply isn’t viable to have covering indexes for all queries. You’ll have to pick and choose, and you’ll have to accept that some queries run at suboptimal speed. Simply because speeding them up incurs too much pain elsewhere.
There are situations where it makes sense to create a covering index for a query that has a tipping point choice. Perhaps the best possible speed without that index is simply too slow for the business requirement. Perhaps the query runs into a bad parameter sniffing issue. Perhaps there are other reasons.
The reason will never be the sheer presence of a Clustered Index Scan operator, though. If you think scans are bad, and if you then start to do stuff to “tune” this query, even when it causes no problems at all, you are doing your job wrong.
Queries with TOP
Let’s move to a much simpler example, with a query to just show me a single row from a table. The type of query I often use when exploring data in a database I have been given access to, just to get a feel for the type of data present.
SELECT TOP (1) Title,
FirstName,
LastName
FROM Person.Person;

This query returns just a single row. It doesn’t get more selective than this. Surely, this is below the tipping point. And yet, the execution plan shows a scan, not a seek.
Why?
Remember the different function of each operator. A seek is intended to efficiently return rows with a given value, or in a given range of values. But there is no value or range of values in this query. The query asks for just a single row, and any row will do.
A scan, on the other hand, just starts somewhere and then keeps reading rows until all were returned … or until no more data is requested. And that’s what the Top operator does. The Top operator causes the execution plan to only request a single row from the Clustered Index Scan, nothing more. And because no more rows are requested, nothing more is read.
The scan, in this case, is a better choice than a seek would ever be. Searching a specific value (or range) takes effort. Having the freedom to just start anywhere means that in the worst case, the same amount of effort is needed. In the best case, it’ll be cheaper. And because a second row will never be requested, the only thing that matters is finding that first row.
So here, the scan is chosen because, even though we wanted just a single row, we didn’t care which row it would be, and that made the scan faster than the seek.
Queries with TOP and ORDER BY
So what happens if we still want just a single row, but now we do care about which row we get? What if we use TOP combined with ORDER BY to specify which single row we want?
SELECT TOP (1) Title,
FirstName,
LastName
FROM Person.Person
ORDER BY FirstName;
SELECT TOP (1) Title,
FirstName,
LastName
FROM Person.Person
ORDER BY LastName;
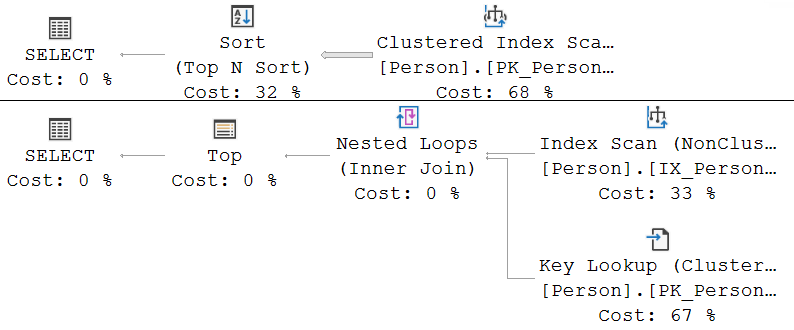
Now we do want a very specific row. And we do still want one. Way below the tipping point.
And yet … index scans again? Even though some random person on the internet said they’re bad? What’s wrong with SQL Server?
Let’s start at the first query. We want one row. The row with the lowest value in FirstName. But there is no index on FirstName, so we cannot use an index to find this row. The only way for SQL Server to find the lowest FirstName value is to read all rows, then sort them, and then return only the first row from the sorted set, which is what the Sort (Top N Sort) operator does.
We don’t know in advance which row has the lowest FirstName, so we need to read all rows before sorting, to guarantee correct results. Reading all rows … yes, now we understand why a scan operator was used here. The FirstName column was not properly indexed, leaving the optimizer no other alternatives.
But will adding an index fix this? Well, yes and no. That’s why I added the second query. The LastName column does already have an index, so this execution plan mimics what we would get for the first query if we add an index on FirstName.
The index on LastName does get used, and it does make the second query run faster. Much faster, in fact. But the index is still read in a scan. Not in a seek. Surely a seek would have been better? We want to read just a single row, and we know which row: the one with the lowest value of LastName.
But let’s take a step back, shall we? A seek is intended to find a specific value. And “the lowest value” is not very specific at all. A seek operator wants to know what value it needs to look for. Anderson? Aalbrecht? Abbas? A scan operator, on the other hand can be configured to return rows in index order, which of course implies it starts at the very first LastName value. Which happens to be exactly the one we need, and so the Top operator once again is used to ensure that the scan returns this first row, and then simply stops working.
So as you see, queries with TOP favor scan operators. If any row will do, then a scan is the fastest way to get a row. If the first row from an index is needed, then an ordered scan on that index is the most efficient. And if no supporting index exists, all rows need to be read (using a scan, of course) and sorted. This last one is definitely an example where there is room for performance gain. Not because it uses a scan, but because it lacks an index, which forces it to read all rows, and then sort them, just to return a single row.
Two rights do not make a … what?
We’ve seen that using TOP in a query results in execution plans with a scan, not a seek. We have also seen that using a LIKE filter for last names starting with S has that same effect.
So let’s combine the two, to see the scanniest of all scans:
SELECT TOP (1) Title,
FirstName,
LastName
FROM Person.Person
WHERE LastName LIKE 'S%'
ORDER BY LastName;

What? No scan? A seek?
Why?
This is why studying execution plans never gets boring. There are always new and interesting interactions to discover and to explore.
We know that a TOP without a WHERE will always prefer a scan. It either needs to read all rows to get them sorted, or it reads a single row and returns that. But the WHERE ruins that. Now, a scan operator will never be guaranteed to find the first matching row immediately. So now, a scan operator suddenly looks much less appealing.
And also, the reason why a scan was chosen when we first looked for people whose last name starts with S was that, based on the estimates, the high number of executions of the Key Lookup operator would drive up the query cost and make it slow. Now, we no longer care about how many last names start with an S. We see the Top operator again that we have seen before. It ensures that the other operators never are asked for a second row. And hence we knew that the Key Lookup will never execute more than once. Way below the tipping point!
Complexity
Reality gets more complex. I have seen cases that are too complex to reproduce in a simple blog example, where scans were chosen for yet other reasons. For instance, one query I worked on used a scan on one of the indexes it had available instead of a seek on another, more selective index; in this case the reason was that, while the scan incurred more I/O and more work, it was able to return rows in the correct order for an operation later in the plan. Had I tried to force the seek on the more selective index, then the cost of the pure data access would have been lower, but the execution plan would have been hit by an additional Sort operator to slow down the query as a whole.
Simplicity
And sometimes reality is not complex at all. In a data warehouse, if a user wants to report on all sales ever recorded, aggregated by various interesting parameters, there there’s simply no contest. They want all the data. Guess what? That’s what scans are best at. So you’ll always get scans in those types of queries. And trust me, that’s what you want to get in such cases.
Conclusion
You saw a selection of relatively simple examples where scans were sometimes used, sometimes not used. When a scan was used, it wasn’t a red flag. Often, the scan was a very good choice, and a seek would never improve the execution plan. In some other cases, there was room for optimization, but always because of reasons other than the index scan. In the examples shown, the actual problem was the absence of a good index.
A scan can of course be a problem. But so can a seek. Both operators have their strengths and their weaknesses. In simple scenarios, the optimizer will always pick the right tool for the job at hand. In more complex cases … well, let’s just say that it almost always still does a mighty fine job.
Scan operators are not bad. Scan operators are not a red flag. Scan operators are not a sign that the query is slow. Nor are seek operators a sign that it is fast.
So if after this I ever hear or read the old “scans are bad seeks are good” myth again, I’m going to throw something.
All operators are good when used appropriately. When a query is slow, the root cause is always either the optimizer picking the wrong operator for that specific case, or the user (i.e., you) not providing the optimizer with the tools it needs to help you (i.e. well written queries, exactly enough and just the right indexes, and properly maintained statistics).
Focus on that. Fix that. And stop focusing on myths, stop thinking there are simple solutions.
If this were simple, everyone would be doing it.



{kind=link}
{kind=link}
5 Comments. Leave new
Awesome article, Hugo. Thanks for finally demystifying this.
Nicely done. I fear it won’t stop the ‘Scan bad, seek good’ mantra but not for lack of excellent illustration.
Kimberly Tripp explains the tipping point and how to predict when a query will move to a scan versus a seek on Pluralsight. Definitely low-level très geek, stuff. Following up your excellent post with this will improve understanding and help mute the mantra further.
I, too, have heard this many times in my 20+ years of fun with SQL Server. I even succumbed to it early on…until I started considering things like context. And the fact that the geeks on the SQL Server team at Microsoft probably know a lot more than me. I also hear similar mantras around ‘Nested loop! Must tune!’. And while I find ‘Parameter sniffing evil!’ to be one of the most egregious examples I applaud your efforts on seeks v. scans!
[…] Hugo Kornelis explains that both seeks and scans exist for a good reason: […]
[…] tend to be happy when they see seek operators in execution plans, because they incorrectly assume seeks are faster than scans. In this case, it is important to be aware that the seek is based on only the ValidUntil column. If […]
[…] Index Seek is usually faster than an Index Scan. Not always though, it’s pretty nuanced, and if you need to a query that gets an entire table, well the table needs to […]