Welcome to part ten of the plansplaining series. Each of these posts takes an execution plan with an interesting pattern, and details exactly how that plan (or pattern) works.
In this post we will look at a query and execution plan that may appear perfectly normal and unexpected at first sight, but that has some perhaps confusing execution counts.
Sample query
The sample query below will (as almost always) run in all versions of the AdventureWorks sample database. It returns a list of all staff, and for people that have a sales-related job title it adds the total of sales they made.
SELECT e.JobTitle, p.FirstName, p.LastName,
CASE WHEN e.JobTitle LIKE '%Sales%'
THEN (SELECT SUM(soh.SubTotal)
FROM Sales.SalesOrderHeader AS soh
WHERE soh.SalesPersonID = e.BusinessEntityID)
END AS TotalSold
FROM HumanResources.Employee AS e
INNER JOIN Person.Person AS p
ON p.BusinessEntityID = e.BusinessEntityID;The execution plan for this query (captured on SQL Server 2017) is shown below; as always I added numbers (equal to the NodeID of each operator) to the screenshot, to make it easier to refer to operators within this plan.

At first sight, this execution plan is not very surprising.
At the top right, we see a scan on the Employee table that drives a Nested
Loops join into a seek on Person – this is a very simple and direct
implementation of the join in the query. The result then goes through another
Nested Loops, into a branch that reads SalesOrderHeader, aggregates it, and
then does a computation – this obviously has to be the subquery within the CASE expression. Finally, Compute Scalar #0
probably does the logical evaluation of the CASE.
There, without even looking at a single property I already have a fair idea
what this execution plan does.
The index spool
The above explanation doesn’t mention Index Spool #8. The most common cause for Index Spool operators in a plan is when SQL Server wants an index really bad. The SalesOrderHeader table does have an index on the SalesPersonID column but it is not covering for this query, so the optimizer was faced with the choice between either using that index and accepting the cost of a lookup, or using a scan … and then it decided to go for door number three, the Index Spool that basically builds the index on the spot and throws it away when the query is done.
That explanation is indeed correct for this case. But it’s not the whole story as you will see when you read on. But let’s first look at one other oddity in this plan.
The missing operator
When the optimizer assigns each operator a NodeID value, it always works left to right and bottom to top, always starts at zero, and always increments by one. And yet, the execution plan above appears to have a gap. There is no operator with NodeID 3. And that is always a sign that something interesting is going on. It means that an operator was removed from the plan in a final cleanup phase, after the plan had already been chosen.
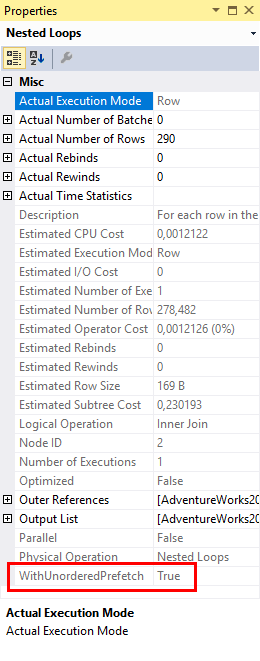 In this case, the reason for the missing operator can be found in the properties of Nested Loops #2. The missing operator #3 is related to prefetching, an optimization used to improve the performance of physical I/O on the inner (bottom) input of the Nested Loops operator. SQL Server implements two types of prefetching: ordered and unordered. Neither of these result in a fixed order being imposed on the data, however ordered prefetching does guarantee that the order of rows from the upper (top) input is preserved, whereas unordered prefetching might change the order of rows.
In this case, the reason for the missing operator can be found in the properties of Nested Loops #2. The missing operator #3 is related to prefetching, an optimization used to improve the performance of physical I/O on the inner (bottom) input of the Nested Loops operator. SQL Server implements two types of prefetching: ordered and unordered. Neither of these result in a fixed order being imposed on the data, however ordered prefetching does guarantee that the order of rows from the upper (top) input is preserved, whereas unordered prefetching might change the order of rows.
The WithOrderedPrefetch and WithUnorderedPrefetch properties of a Nested Loops join only have any effect on the performance if data to be read from the inner input is not yet in the buffer pool. Instead of waiting for the Nested Loops operator to activate its inner input, then request data, and then fetch it into the buffer pool, data flowing into the outer input of the Nested Loops operator is inspected in advance to check whether it will result in physical I/O. If it does, then it will already start an asynchronous I/O request, in the hope that the read will have completed and the data will already be in the buffer pool by the time it is actually needed.
When SQL Server adds prefetching to a Nested Loops operator, it adds s special “read ahead logic” operator in the execution plan. This operator will be positioned at the outer input of the Nested Loops, so in this case between Nested Loops #2 and Clustered Index #4. This special operator stays there until after the plan selection has been made; at that time a final cleanup phase will fold this special operator into the Nested Loops operator, leaving a gap in the otherwise consecutive NodeID numbering. So that’s why there is no operator #3 in this execution plan.
If you want to learn more about prefetching, I recommend reading Craig Freedman’s blog post, Paul White’s blog post, and Fabiano Amorim’s article. The rest of this blog post will focus on other areas of this execution plan.
How many executions?
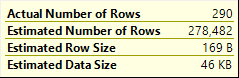 If you look at all the various counters in the execution plan, you might see some unexpected numbers. The screenshot to the right shows the data flowing out of Nested Loops #2 into the outer input of Nested Loops #1. The Actual Number of Rows is 290. So naturally, you would expect the operators on the inner input of Nested Loops #1 to execute a total of 290 times, right?
If you look at all the various counters in the execution plan, you might see some unexpected numbers. The screenshot to the right shows the data flowing out of Nested Loops #2 into the outer input of Nested Loops #1. The Actual Number of Rows is 290. So naturally, you would expect the operators on the inner input of Nested Loops #1 to execute a total of 290 times, right?
Turns out … you’d be wrong!
If you look at the far right, at Clustered Index Scan #9, you will see that the Number of Executions is 1, and that this matches the Estimated Number of Executions. This part is not the surprise. Clustered Index Scan #9 is called by Index Spool #8, an eager spool. We know that this spool on its first execution will fetch all data from Clustered Index Scan #9, store it in a worktable with an index to support its Seek Predicate, and then on all later executions it will fetch data from that worktable without invoking Clustered Index Scan #9 again. So the single execution of this operator is no surprise.
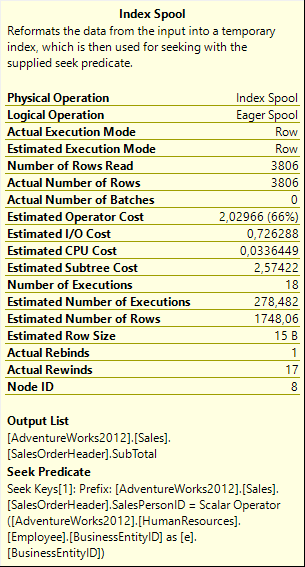 But let’s now look at Index Spool #8 itself. As you can see in the screenshot to the right, this operator was estimated to execute 278.482 times, which matches the Estimated Number of Rows in the outer input of Nested Loops #1. But … the actual execution count of this Index Spool is not the expected 290; we only see a mere 18 executions! What happened to the other executions?
But let’s now look at Index Spool #8 itself. As you can see in the screenshot to the right, this operator was estimated to execute 278.482 times, which matches the Estimated Number of Rows in the outer input of Nested Loops #1. But … the actual execution count of this Index Spool is not the expected 290; we only see a mere 18 executions! What happened to the other executions?
The first step is a quick reality check. Yes, I did not look in the wrong place, Nested Loops #1 really receives 290 rows on its outer input. It also returns 290 rows to its parent (Compute Scalar #0), and I can see that the final result set of the query has the full 290 rows.
The next step is to look where the number changed. The properties of Stream Aggregate #7 show the same numbers for estimated and actual number of executions; the properties of Compute Scalar #6 also show the same estimate, and include no actual count at all (not unusual for a Compute Scalar; an in-depth explanation of this curious behavior is properly better left for a future post). For now, it appears that Nested Loops #1 is the root cause. Even though it processes and returns 290 rows, it only actually executes its inner input 18 times. Let’s look in a bit more detail.
Nested Loops #1
 Hovering the mouse over Nested Loops #1 shows a property that is not often seen on Nested Loops operators. In fact, many people have never seen this property and are unaware of its existence. It is the Pass Through property, a property I have so far only seen on Nested Loops operators (and only for Logical Operation Inner Join or a Left Outer Join).
Hovering the mouse over Nested Loops #1 shows a property that is not often seen on Nested Loops operators. In fact, many people have never seen this property and are unaware of its existence. It is the Pass Through property, a property I have so far only seen on Nested Loops operators (and only for Logical Operation Inner Join or a Left Outer Join).
When the Pass Through property is present, the Nested Loops will for each row it reads on the outer input first evaluate the condition listed in this property. If the condition evaluates to true, then it will, as the name of the property implies, just pass its input row on, unchanged, to the parent operator. On the next call, it will then immediately move on to the next row on its outer input.
So simplified, you could say that Pass Through means: if this condition is true, then you can just skip all the join logic for this row and pass it through, unchanged.
For the columns in the Output List that take their values from the inner input, no value can be given if the join was skipped due to the Pass Through property. I don’t know if they are always set to NULL in that case or if they are simply left at whatever they are and the rest of the plan makes sure to never look at that data.
In this case, the Pass Through property uses a function called “IsFalseOrNull”. This value can only be used internally within execution plans (I personally would not mind having it available in T-SQL as well, though!). It is intended to help in dealing with three-valued logic. The net effect of the entire condition is to check whether the JobTitle column includes the word “Sales”. If so, then that condition is true, which means that IsFalseOrNull returns False, which in turn means that the pass through logic is not invoked and the inner input of the Nested Loops operator executes as normal. However, when JobTitle does not include the word Sales, or when it is NULL, then the LIKE condition is either False or Unknown, and then IsFalseOrNull evaluates to True, which means that the pass through condition kicks in and the inner input is skipped.
If you look at the data produced by joining the Employee and the Person tables, you will notice that there are 290 rows total, but only 18 have a JobTitle that includes the word Sales. The Pass Through condition kicked in on the remaining 272 rows, and that is why the operators on the inner input of Nested Loops #1 executed only 18 times instead of the expected 290 executions.
We all love better performance!
 The Pass Through expression in this execution plan is clearly intended to improve performance. And at first sight that is exactly what it does. If you remove this property and leave the rest of the plan unchanged, then Compute Scalar #6, Stream Aggregate #7, and Index Spool #8 will all execute 272 additional times. And each of those times they will produce a result that then subsequently is ignored – because of the
The Pass Through expression in this execution plan is clearly intended to improve performance. And at first sight that is exactly what it does. If you remove this property and leave the rest of the plan unchanged, then Compute Scalar #6, Stream Aggregate #7, and Index Spool #8 will all execute 272 additional times. And each of those times they will produce a result that then subsequently is ignored – because of the CASE expression in the query, Compute Scalar #0 only actually does something with the value returned from these operators if “Sales” is included somewhere in the JobTitle, which is only the case for the 18 rows where the Pass Through property did not prevent execution of this branch.
And obviously, the reason that the optimizer even included this Pass Through property is that it, too, understood the significance of the CASE expression. The optimizer knew that the value returned by this branch will only be used in some cases, and hence needs not be computed at all in other cases. (What I do not understand, though, is why the Estimated Number of Executions for the operators in this branch do not reflect that understanding…)
But you might want to ask why the CASE expression is even there at all? It is of course possible that it is needed for correctness. Perhaps the application does sometimes allow a sale to be registered to an employee who does not have “Sales” as part of their job title. If we definitely do NOT want to see those sales included in the report, then the query definitely has to be written as it currently is. End of discussion.
But is it?
However, a query such as this is also very often the result of a developer looking at the query, looking at the data, looking at the business rules, and then deciding to help the optimizer a bit. In the case of the AdventureWorks sample database, all employees that have any sales to their name actually do have “Sales” in their job title. So for this database, the query could also have been written as this, and it would return the same result.
SELECT e.JobTitle, p.FirstName, p.LastName,
(SELECT SUM(soh.SubTotal)
FROM Sales.SalesOrderHeader AS soh
WHERE soh.SalesPersonID = e.BusinessEntityID) AS TotalSold
FROM HumanResources.Employee AS e
INNER JOIN Person.Person AS p
ON p.BusinessEntityID = e.BusinessEntityID;Perhaps the query started like this. And then, perhaps,
there was a developer looking at this query and deciding “You know what, SQL
Server is going to tally up SalesOrderHeader for all staff members, even though
most of them are not in sales and will therefor not have any sales in there.
I’ll just step in and add a CASE
expression to help SQL Server skip the executions for all those non-sales
folk!”
Now before I go on, I am actually happy with these developers. I really prefer developers that give thought to performance over those that don’t care. However, in this case the developer was wrong. Good intentions, but bad results. And when I find the original query in my production code, I’ll find the developer, compliment them on their attention to detail, and then remind them that they should definitely also test.

This is the execution plan I got when running the version of the query without the CASE expression. The logic to join Employee and Person is unchanged, but now the logic to compute the total sold for each employee in a sales role has changed. Instead of a Nested Loops with multiple passes. We now get a Merge Join with a single pass, and with early aggregation on a Hash Match. And the Index Spool has been completely removed.
I won’t go into the details of this execution plan. But if
you compare the two versions of the query by running them with SET STATISTICS IO ON and SET STATISTICS TIME ON, you will see that
both queries have the same amount of I/O on the base tables, but the first
query also has a lot of logical reads on a worktable, due to the Index Spool.
The second query does have both a worktable and a workfile – these are there in
case the Sort or the Hash Match operators need to spill. But neither does
spill, so there is no actual I/O on those.
Mainly as a result of all the additional I/O on that
worktable, the original query (with a CASE expression in the query, and with a Pass Through expression and an Index
Spool operator in the execution plan) also takes more time – 114 ms vs 46 ms on
my laptop.
However, do not forget that all this bases on one very important assumption: that given the way the application works, we can be sure that the two versions of the query always return the same data. Based on the query alone that is not guaranteed, so unless the application gives us additional guarantees the two queries are not equal, and you should always opt for the one that returns correct results, regardless of performance.
Conclusion
The main topic of this post is the Pass Through property. It is not a very widely known property, but it can be important to understand how an execution plan really works. After all, you would not want to invest a lot of effort to tune a branch of an execution plan only to find out later that it only executes for a fraction of the rows.
However, we also saw an example of what people might call “premature optimization”: a change to a query intended to help the optimizer but insufficiently verified as to whether it really meets that intended goal. Query optimization is complex, and changes that appear to be beneficial for performance do not always result in an execution plan that is always faster. And it is also very important to realize that in this case the two queries were only the same based on the data currently in the database; unless there are constraints in place (preferably in the database, but sometimes enforced by the application) to ensure that this is always the case, the two queries might return different results and only one of them should be considered correct.
Finally, we had a short discussion on Nested Loops prefetching and how that results in a gap in the NodeID numbers of the operators in an execution plan.
That concludes part 10 of the plansplaining series. I still have a few ideas left on my list for future episodes, but it is growing shorter – so please, help me out if you can! If you see an unusual and interesting pattern in an execution plan, let me know so I can add it to my list!





{kind=link}
{kind=link}