In part twenty-eight of the plansplaining series, I’ll wrap up the six-part mini-series on window functions. After covering the basics, fast-track optimization, window frames ending at UNBOUNDED FOLLOWING, window frames specified with RANGE instead of ROWS, and LAG and LEAD, we will look at the LAST_VALUE and FIRST_VALUE analytical functions, and find that a function we would have expected to be available as an internal aggregate function does not exist at all! We’ll also find out how SQL Server works around that.
LAST_VALUE
We already encountered the LAST_VALUE internal aggregate function in the previous post, where it is used to compute the results of LAG and LEAD functions. It can, quite obviously, also be used to evaluate the LAST_VALUE analytical T-SQL function, which was introduced in SQL Server 2012.
SELECT p.ProductID,
p.Name,
p.ListPrice,
p.ProductLine,
LAST_VALUE(p.ListPrice) OVER (PARTITION BY p.ProductLine
ORDER BY p.ListPrice
ROWS BETWEEN 2 FOLLOWING
AND 5 FOLLOWING) AS LaterPrice
FROM Production.Product AS p;
The execution plan is in no way surprising:

(Click on the picture to enlarge)
It is basically the same execution plan that we already saw in the first episode of this mini-series; the only difference is the computation of the frame boundaries in the Compute Scalar operator, and the aggregate function used in the Stream Aggregate. And those changes immediately follow from the changes in the query.
Add NULL handling
The IGNORE / RESPECT NULLS clause, that was added to LAG and LEAD in SQL Server 2022, can be applied to the LAST_VALUE function as well. RESPECT NULLS is the default, and leaves the behavior unchanged. IGNORE NULLS can change the results.
SELECT p.ProductID,
p.Name,
p.ListPrice,
p.ProductLine,
LAST_VALUE(p.ListPrice) IGNORE NULLS
OVER (PARTITION BY p.ProductLine
ORDER BY p.ListPrice
ROWS BETWEEN 2 FOLLOWING
AND 5 FOLLOWING) AS LaterPrice
FROM Production.Product AS p;
In this specific case, the results do not change, because there are no NULL values in the ListPrice column. But SQL Server still does create an execution plan that works as expected even if there are:

(Click on the picture to enlarge)
We already saw that, when applied to LAG, this results in an execution plan that uses a different internal function, unsurprisingly called LAST_VALUE_IGNORE_NULLS. This function was introduced in SQL Server 2024, for the very reason that it is needed to implement the IGNORE NULLS clause on LAG, LEAD, and LAST_VALUE. So no surprises here.
FIRST_VALUE
It probably won’t surprise you that Microsoft gave you the full package: together with LAST_VALUE, another analytical function, for FIRST_VALUE, was also introduced in SQL Server 2012. And of course it also was extended with support for IGNORE NULLS in SQL Server 2022.
So, just for completeness sake, let’s modify the example above. I have also changed the window frame a bit, to ensure it is a use case that actually makes sense and shows some interesting results, even in a dataset that does not actually have any NULL values.
SELECT p.ProductID,
p.Name,
p.ListPrice,
p.ProductLine,
FIRST_VALUE(p.ListPrice) IGNORE NULLS
OVER (PARTITION BY p.ProductLine
ORDER BY p.ListPrice
ROWS BETWEEN 5 PRECEDING
AND 2 PRECEDING) AS EarlierPrice
FROM Production.Product AS p;
Once more, the execution plan looks the same, because the only difference is in the properties:

(Click on the picture to enlarge)
The only surprise here is not even in the execution plan itself. It computes the window frame boundaries, as expected, and then computes the results, by using the FIRST_VALUE_IGNORE_NULLS, which you probably also expected.
The surprise comes when you choose to look up this function in the list of all known internal aggregation functions. You might have expected to find this function marked as introduced in SQL Server 2022. But it is not. It has, in fact, existed since at least SQL Server 2012! But why? And, since we are looking at the list of supported internal aggregate functions anyway, why is there no FIRST_VALUE to complement the LAST_VALUE function?
Remove the NULL handling again
So, let’s just find out. Let’s remove the IGNORE NULLS clause (or change it to an explicit RESPECT NULLS) to see how SQL Server works around this apparent limitation to compute the FIRST_VALUE for a framed window.
SELECT p.ProductID,
p.Name,
p.ListPrice,
p.ProductLine,
FIRST_VALUE(p.ListPrice) OVER (PARTITION BY p.ProductLine
ORDER BY p.ListPrice
ROWS BETWEEN 5 PRECEDING
AND 2 PRECEDING) AS EarlierPrice
FROM Production.Product AS p;
The execution plan below was taken from a SQL Server 2022 instance, but you will get the exact same execution plan on SQL Server 2012, and on any version in between:

(Click on the picture to enlarge)
We actually have a difference here that is visible even in the graphical execution plan. One extra Compute Scalar operator is added to the left of the Stream Aggregate. But let’s start with that Stream Aggregate itself.
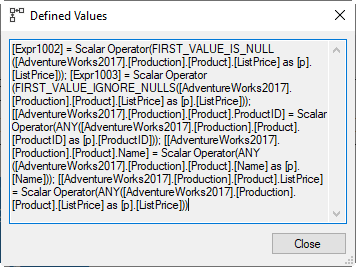 You see its Defined Values property in the screenshot to the right. There is of course no FIRST_VALUE function used. We already established that there is no such internal aggregate function. Instead, Expr1003 is computed by using the same FIRST_VALUE_IGNORE_NULLS function that we already saw in the example above, where we actually expected it. Here, we didn’t really expect it, because it does not produce the correct value in cases where the first row in the frame happens to have a NULL value in the referenced column.
You see its Defined Values property in the screenshot to the right. There is of course no FIRST_VALUE function used. We already established that there is no such internal aggregate function. Instead, Expr1003 is computed by using the same FIRST_VALUE_IGNORE_NULLS function that we already saw in the example above, where we actually expected it. Here, we didn’t really expect it, because it does not produce the correct value in cases where the first row in the frame happens to have a NULL value in the referenced column.
In order to fix that, the Stream Aggregate also computes Expr1002, using the FIRST_VALUE_IS_NULL function. This function returns a Boolean value that indicates, as the name suggests, whether the first value the operator encounters within a group is NULL or not NULL. Its operation is really very simple. At the start of each new group, it is initialized to NULL. It is then set to either True or to False as the first row is processed. After that, when processing the rest of the rows in the same group, it is simply left unchanged.
Now, it is important to realize that the Stream Aggregate can in fact return three different values for Expr1002. This column can be True or False, depending on whether the first row in each frame has a NULL or non-NULL value in the ListPrice column. But with framed windows, it is also possible that some rows have a completely empty frame. And this does indeed actually happen in our example, for the first two rows in each partition! In those cases, the internal counter for FIRST_VALUE_IS_NULL is initialized (to NULL), but then never set. And so, Expr1002 will be returned as NULL to the Compute Scalar in those cases.
For each of these three cases, it is easy to work out what the query should return. If Expr1002 is True, then the first value in the window frame is NULL, and FIRST_VALUE should return NULL and ignore Expr1003. If Expr1003 is False, then the first value is not NULL, and Expr1003 contains the requested value. And if Expr1003 is NULL, then the frame is empty, and NULL should be returned.
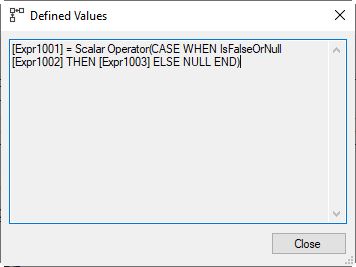 And yet we see a surprise in the Defined Values property of the Compute Scalar. You can see it in the screenshot on the right. We just established that we expect a NULL returned when Expr1002 is True or NULL, and only expect to return Expr1003 when Expr1002 is False. But instead, the IsFalseOrNull internal scalar function is used on Expr1002. We only return NULL when Expr1002 is True, and return Expr1003 both when it is False, but also when it is NULL! Why does it not use IsTrueOrNull [Expr1002], or IsFalse [Expr1002], to properly distinguish the cases that matter?
And yet we see a surprise in the Defined Values property of the Compute Scalar. You can see it in the screenshot on the right. We just established that we expect a NULL returned when Expr1002 is True or NULL, and only expect to return Expr1003 when Expr1002 is False. But instead, the IsFalseOrNull internal scalar function is used on Expr1002. We only return NULL when Expr1002 is True, and return Expr1003 both when it is False, but also when it is NULL! Why does it not use IsTrueOrNull [Expr1002], or IsFalse [Expr1002], to properly distinguish the cases that matter?
Well, there is of course the little fact that the list of supported internal scalar function does not include either IsTrueOrNull or IsFalse. But should we then not at least have expected IsFalseOrNull (Not ([Expr1002]))?
To be honest, the purist in me would have preferred that option. But reality is, it really does not matter! Expr1002 is only NULL when the window frame is empty. And if the window frame is empty, then that means that Expr1003 was initialized to NULL and then never updated, because there were no rows to update it with. And so, it actually does not make any real difference whether in this case we set Expr1001 to a hard-coded NULL or to the NULL value in Expr1003.
I guess Microsoft simply chose to use the slightly simpler version WHEN IsFalseOrNull Expr1002 THEN Expr1003 ELSE NULL END over the equivalent alternative of WHEN IsFalseOrNull NOT(Expr1002) THEN NULL ELSE Expr1003 END. Other than causing me a short moment of confusion when I first looked at this, absolutely no harm was done at all.
Summary
Support for the FIRST_VALUE and LAST_VALUE analytical function in T-SQL is and has always been perfectly symmetrical. But their implementation in the execution plans is not. Whereas the original LAST_VALUE was supported in a very straightforward way, the implementation for FIRST_VALUE was indirect and more complex. That then made implementation for IGNORE NULLS on FIRST_VALUE completely trivial, whereas a new internal aggregate function was required to also implement IGNORE NULLS on LAST_VALUE.
Why Microsoft chose for this asymmetric implementation is a question I cannot answer. My assumption is that the functions they chose to implement could also be used to optimize some other cases (that I have not yet found), whereas the functions they did not implement would have been less useful overall. But that is nothing but speculation.
This started as a simple reply to a T-SQL Tuesday prompt. It then grew to the point where I felt I had to split it. And then split it again. And, oh, there was even more interesting, so I added that too. But now, after six parts, it is finally done. This was my last post on plansplaining window functions. But it is not my last plansplaining post overall! The next one will be about a very different topic … and should have a lot more variety in the pictured execution plans!
As always, please let me know if there is any execution plan related topic you want to see explained in a future plansplaining post and I’ll add it to my to-do list!






{kind=link}
{kind=link}
1 Comment. Leave new
[…] Hugo Kornelis wraps up a mini-series on window functions: […]